1.Neo4j安装
Neo4j 是一个基于图形结构的 NoSQL 数据库,专门用于存储和管理图数据。与传统的关系型数据库不同,Neo4j 使用 图(graph)的形式来表示数据,其中数据点(称为 节点)通过 边(relationships)相互连接。Neo4j使用Java语言开发。
最新版本的neo4j-community-5.25.1需要JDK17+版本,所以我们必须先下载安装JDK17,并且正确配置JDK17 的环境变量。
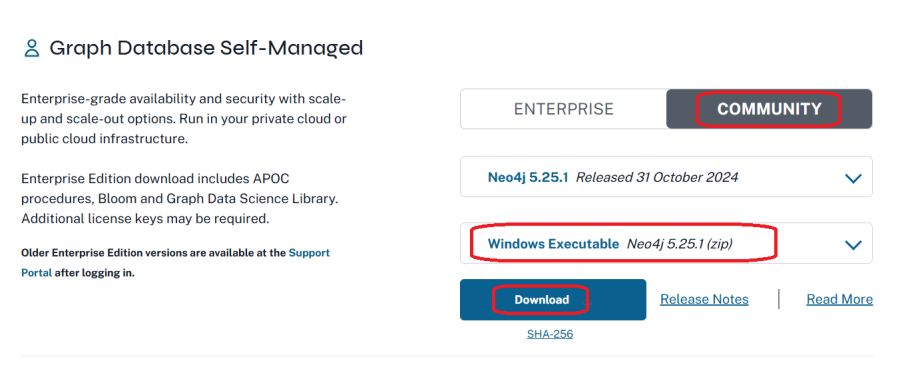
下来安装Neo4j,进入Neo4j官网,网站如下:https://neo4j.com/developer/ 找到Graph Database Self-Managed,点击COMMUNITY,选择Windows Executable,点击下载,把下载的压缩包解压至C盘目录下。
配置环境变量:
- 打开设置页面:右击“此电脑”->属性->高级系统设置->环境变量
- 新建系统环境变量:名为NEO4J_HOME,值为C:\neo4j-community-5.25.1
- 修改Path变量:在其值中增加%NEO4J_HOME%\bin
启动Neo4j:
在命令行输入:neo4j console,之后在浏览器搜索:http://localhost:7474 进行用户创建。初始用户名及密码都是neo4j,之后会让你重置密码。
2.知识图谱概述
2.1 知识图谱的定义与重要性
知识图谱(Knowledge Graph)是一种用于表示和存储知识的结构化数据模型。它通过节点(Node)和边(Edge)来表示实体(Entity)及其之间的关系(Relationship),形成一个复杂的网络结构。知识图谱的核心在于其能够捕捉实体间的复杂关系,这些关系不仅仅是简单的键值对,而是多维度的、层次化的关联。
知识图谱的重要性体现在以下几个方面:
- 信息整合:知识图谱能够将分散在不同来源的信息整合在一起,形成一个统一的知识库。这使得用户可以在一个平台上访问和查询多种类型的信息,而不需要切换不同的数据库或系统。
- 智能搜索:通过图结构,知识图谱支持复杂的查询,能够回答诸如“找出所有在[年份]发布的电影,其中包含演员X”这样的问题,这在传统数据库中是难以实现的。
- 增强AI性能:在人工智能领域,知识图谱可以为机器学习模型提供额外的上下文信息,从而提升模型的理解和推理能力。例如,在自然语言处理中,知识图谱可以帮助模型更好地理解词语之间的关系,从而提高翻译、问答等任务的准确性。
2.2 知识图谱在人工智能中的应用
知识图谱在人工智能(AI)领域有着广泛的应用,尤其是在自然语言理解、信息检索、智能推荐等领域。以下是几个典型的应用场景:
- 自然语言理解:知识图谱可以帮助AI系统更好地理解自然语言中的实体和关系。例如,当用户查询“谁是乔布斯的妻子?”时,知识图谱可以直接提供答案“劳伦·鲍威尔·乔布斯”,而不需要通过复杂的文本分析。
- 信息检索:在信息检索系统中,知识图谱可以帮助系统更好地理解用户的查询意图,从而提供更精准的搜索结果。例如,当用户搜索“苹果公司”时,知识图谱不仅可以提供苹果公司的基本信息,还可以展示苹果公司的创始人、产品线、竞争对手等相关信息。
- 智能推荐:在智能推荐系统中,知识图谱可以帮助系统更好地理解用户的兴趣和偏好,从而提供更个性化的推荐。例如,当用户喜欢某位演员的电影时,知识图谱可以推荐该演员的其他作品,或者推荐与该演员合作过的其他演员的作品。
2.3 知识图谱与传统数据库的区别
虽然知识图谱和传统数据库都用于存储和管理数据,但它们在数据模型、查询语言和应用场景上有着显著的区别。
- 数据模型:传统数据库通常采用表格(Table)的形式来存储数据,数据之间的关系通过外键(Foreign Key)来表示。而知识图谱则采用图(Graph)的形式来存储数据,数据之间的关系通过边(Edge)来表示。这种图模型使得知识图谱能够更自然地表示实体之间的复杂关系。
- 查询语言:传统数据库通常使用SQL(Structured Query Language)来查询数据,而知识图谱则使用Cypher等图查询语言。Cypher语言的设计更加贴近图的结构,使得查询图数据变得更加直观和高效。
- 应用场景:传统数据库通常用于存储结构化数据,如订单、用户信息等,而知识图谱则更适用于存储和查询实体及其关系,如社交网络、知识库等。知识图谱在处理复杂关系和非结构化数据时具有明显的优势。
总之,知识图谱作为一种强大的工具,正在改变我们理解和利用知识的方式。通过构建和应用知识图谱,我们可以实现更智能化的应用和服务,从而更好地应对现实世界中的各种挑战。
3.Neo4j的基本概念与特点
Neo4j是一款高性能的图数据库,专门用于存储和处理复杂的关系数据。与传统的关系型数据库不同,Neo4j使用节点(Node)和关系(Relationship)来表示数据,这种结构使得它在处理复杂关系时表现出色。
节点(Node)
节点是Neo4j中的基本数据单元,类似于传统数据库中的记录或行。每个节点可以包含多个属性(Property),这些属性类似于数据库中的字段。例如,一个表示人物的节点可能包含name、age、gender等属性。
关系(Relationship)
关系是Neo4j中连接两个节点的桥梁,类似于传统数据库中的外键。关系可以有方向,表示从一个节点指向另一个节点的关系。例如,Person节点和Location节点之间可以通过BORN_IN边连接,表示某人出生在某地。
标签(Label)
标签用于对节点进行分类,类似于传统数据库中的表。一个节点可以有多个标签,表示它属于多个类别。例如,一个节点可以同时有Person和Actor两个标签,表示它既是一个人,也是一个演员。
属性(Property)
属性是节点和边的附加信息,类似于传统数据库中的字段。属性可以是字符串、数字、日期等类型。例如,一个Person节点的name属性可以是字符串类型,age属性可以是数字类型。
图(Graph)
图是由节点和边组成的集合,表示数据之间的关系。Neo4j的核心就是存储和查询这些图结构的数据。图数据库的优势在于它可以高效地处理复杂的关系查询,而传统数据库在这方面往往表现不佳。
4.Cypher的基本语法
Cypher是Neo4j的查询语言,专门用于图数据库的查询和操作。它的语法设计直观,易于理解和使用,特别适合处理图结构的数据。Cypher的核心概念包括节点(Node)、关系(Relationship)、属性(Property)和模式(Pattern)。
4.1 创建、更新、删除节点和关系
创建节点:
使用 CREATE 语句可以创建新的节点。节点可以带有标签和属性。
CREATE (n:Person {name: 'Charlie', age: 25})
RETURN n
创建关系:
使用 CREATE 语句可以在两个节点之间创建关系。关系可以带有属性。
MATCH (a:Person {name: 'Alice'}), (b:Person {name: 'Bob'})
CREATE (a)-[:WORKS_WITH {since: 2021}]->(b)
RETURN a, b
更新节点和关系:
使用 SET 语句可以更新节点或关系的属性。
MATCH (n:Person {name: 'Alice'})
SET n.age = 32
RETURN n
删除节点和关系:
使用 DELETE 语句可以删除节点或关系。注意,删除节点时,必须先删除与之相关的所有关系。
MATCH (n:Person {name: 'Charlie'})
DETACH DELETE n
简单匹配:
匹配所有标签为 Person 的节点。
MATCH (n:Person)
RETURN n
条件匹配:
匹配年龄大于30的 Person 节点。
MATCH (n:Person)
WHERE n.age > 30
RETURN n
路径匹配:
匹配所有 Person 节点及其 WORKS_WITH关系。
MATCH (a:Person)-[:WORKS_WITH]->(b:Person)
RETURN a, b
5.py2neo操作neo4j知识图谱
py2neo 是一个 Python 库,用于与 Neo4j 图数据库进行交互。以下是py2neo操作neo4j图数据库的简单示例。
首先安装py2neo依赖。
pip install py2neo
代码实现:
from py2neo import Graph
from py2neo import Graph, Node, Relationship, Subgraph, NodeMatcher, RelationshipMatcher
if __name__ == '__main__':
# from requests import delete
# import time
###连接数据库
graph = Graph('bolt://localhost:7687', auth=('neo4j', 'neo4j1234'))
# g = Graph('http://localhost:7474',auth = ('neo4j','12345678'))
# 创建节点
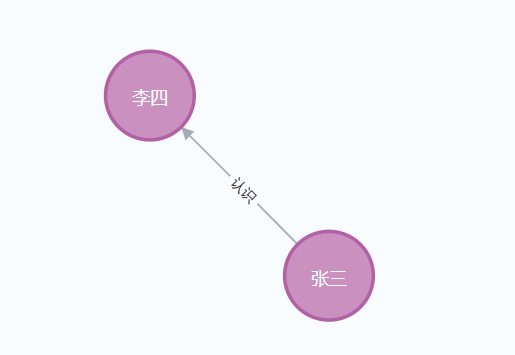
p1 = Node("Person", name="张三")
p2 = Node("Person", name="李四")
graph.create(p1)
graph.create(p2)
# 创建关系
r = Relationship(p1, "认识", p2)
graph.create(r)
# 节点查询
mather = NodeMatcher(graph)
result = mather.match("Person", name="张三").first()
print(result)
# 查询关系
relation_matcher = RelationshipMatcher(graph)
ret = relation_matcher.match((result,), r_type="认识").first()
print(ret)
# 直接运行cypher语句
ret = graph.run('match(p:Person{name:"李四"}) return p').data()
print(ret)
运行结果:
(_0:Person {name: '\u5f20\u4e09'})
(张三)-[:认识 {}]->(李四)
[{'p': Node('Person', name='李四')}]
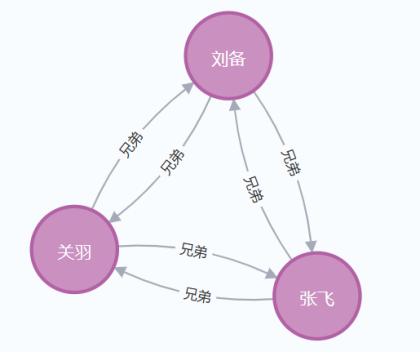
5.1 案例一:三国英雄刘关张关系图谱
from py2neo import Graph
from py2neo import Graph, Node, Relationship, Subgraph, NodeMatcher, RelationshipMatcher
if __name__ == '__main__':
###连接数据库
graph = Graph('bolt://localhost:7687', auth=('neo4j', 'neo4j1234'))
# 创建节点
p1 = Node("Person", name="张飞")
p2 = Node("Person", name="刘备")
p3 = Node("Person", name="关羽")
graph.create(p1)
graph.create(p2)
graph.create(p3)
# 创建关系
# 张飞和刘备互为兄弟
r = Relationship(p1, "兄弟", p2)
graph.create(r)
r = Relationship(p2, "兄弟", p1)
graph.create(r)
#张飞和关羽也互为兄弟
r = Relationship(p1, "兄弟", p3)
graph.create(r)
r = Relationship(p3, "兄弟", p1)
graph.create(r)
#刘备和关羽互为兄弟
r = Relationship(p2, "兄弟", p3)
graph.create(r)
r = Relationship(p3, "兄弟", p2)
graph.create(r)
# 节点查询
mather = NodeMatcher(graph)
result = mather.match("Person", name="张飞").first()
print(result)
# 查询关系
relation_matcher = RelationshipMatcher(graph)
ret = relation_matcher.match((result,), r_type="兄弟").all()
print(ret)
# 直接运行cypher语句
ret = graph.run('match(p:Person{name:"张飞"}) return p').data()
print(ret)
运行结果:
(_0:Person {name: '\u5f20\u98de'})
[兄弟(Node('Person', name='张飞'), Node('Person', name='关羽')), 兄弟(Node('Person', name='张飞'), Node('Person', name='刘备'))]
[{'p': Node('Person', name='张飞')}, {'p': Node('Person', name='张飞')}, {'p': Node('Person', name='张飞')}]
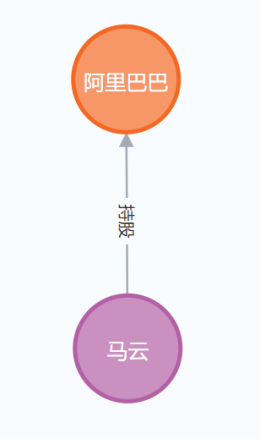
5.2 案例二:金融知识图谱
金融领域涉及大量的实体和关系,如公司、股东、投资关系等。通过构建金融知识图谱,可以帮助金融机构更好地进行风险评估、投资分析和市场预测。
from py2neo import Graph
from py2neo import Graph, Node, Relationship, Subgraph, NodeMatcher, RelationshipMatcher
if __name__ == '__main__':
###连接数据库
graph = Graph('bolt://localhost:7687', auth=('neo4j', 'neo4j1234'))
# 创建节点
c1 = Node("Company", name="阿里巴巴", industry='互联网')
p1 = Node("Person", name="马云", title='阿里巴巴创始人')
graph.create(c1)
graph.create(p1)
# 创建关系
r = Relationship(p1, "持股", c1)
graph.create(r)
# 节点查询
mather = NodeMatcher(graph)
result = mather.match("Person", name='马云').first()
print(result)
# 查询关系
relation_matcher = RelationshipMatcher(graph)
ret = relation_matcher.match((result,), r_type="持股").all()
print(ret)
运行结果:
(_12:Person {name: '\u9a6c\u4e91', title: '\u963f\u91cc\u5df4\u5df4\u521b\u59cb\u4eba'})
[持股(Node('Person', name='马云', title='阿里巴巴创始人'), Node('Company', industry='互联网', name='阿里巴巴'))]