使用Python和Numpy构建神经网络之波士顿房价预测
使用Python和Numpy构建神经网络之波士顿房价预测
波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。和大家对房价的普遍认知相同,波士顿地区的房价是受诸多因素影响的。
1.数据集下载
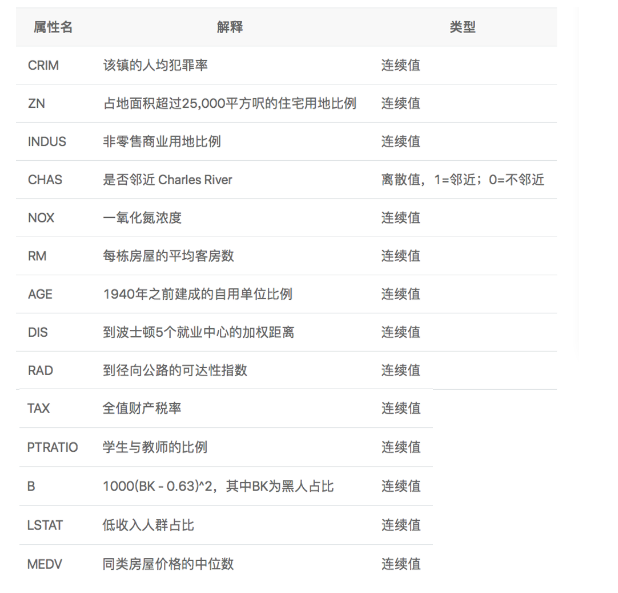
下载数据集:https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data 该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型,如图所示。
2.逻辑框架
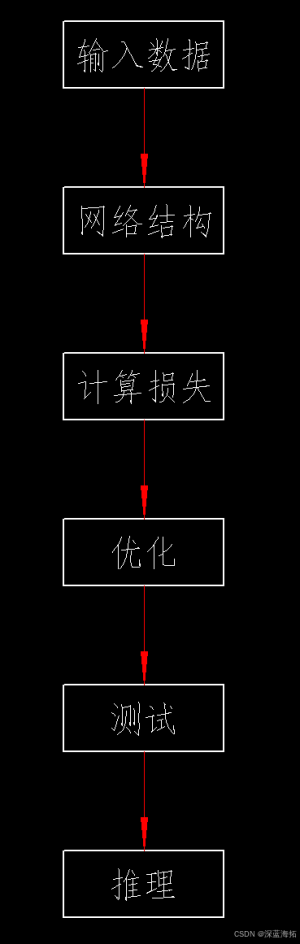
3.程序实现
# 导入需要用到的package
import numpy as np
import json
import matplotlib.pyplot as plt
#加载数据函数
def load_data():
# 从文件导入数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
# 测试集和训练集必须是没有交集的
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算训练集的最大值,最小值
maximums, minimums = training_data.max(axis=0), \
training_data.min(axis=0)
# 对数据进行归一化处理
for i in range(feature_num):
data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
#构建网络模型函数
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
# np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
N = x.shape[0]
gradient_w = 1. / N * np.sum((z - y) * x, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = 1. / N * np.sum(z - y)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, eta=0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, training_data, num_epochs, batch_size=10, eta=0.01):
n = len(training_data)
losses = []
for epoch_id in range(num_epochs):
# 在每轮迭代开始之前,将训练数据的顺序随机打乱
# 然后再按每次取batch_size条数据的方式取出
np.random.shuffle(training_data)
# 将训练数据进行拆分,每个mini_batch包含batch_size条的数据
mini_batches = [training_data[k:k + batch_size] for k in range(0, n, batch_size)]
for iter_id, mini_batch in enumerate(mini_batches):
# print(self.w.shape)
# print(self.b)
x = mini_batch[:, :-1]
y = mini_batch[:, -1:]
a = self.forward(x)
loss = self.loss(a, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(loss)
print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'.
format(epoch_id, iter_id, loss))
return losses
#测试主程序
if __name__ == '__main__':
# 获取数据
train_data, test_data = load_data()
# 创建网络
net = Network(13)
# 启动训练
losses = net.train(train_data, num_epochs=50, batch_size=100, eta=0.1)
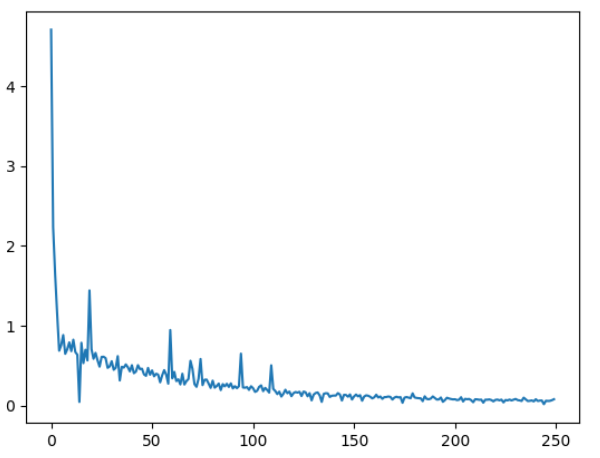
# 画出损失函数的变化趋势
plot_x = np.arange(len(losses))
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
运行结果:
Epoch 0 / iter 0, loss = 4.7068
Epoch 0 / iter 1, loss = 2.2347
Epoch 0 / iter 2, loss = 1.6424
Epoch 0 / iter 3, loss = 1.1477
Epoch 0 / iter 4, loss = 0.6882
Epoch 1 / iter 0, loss = 0.7592
Epoch 1 / iter 1, loss = 0.8844
Epoch 1 / iter 2, loss = 0.6493
Epoch 1 / iter 3, loss = 0.7054
Epoch 1 / iter 4, loss = 0.7930
Epoch 2 / iter 0, loss = 0.6826
Epoch 2 / iter 1, loss = 0.8264
Epoch 2 / iter 2, loss = 0.6717
Epoch 2 / iter 3, loss = 0.6381
Epoch 2 / iter 4, loss = 0.0473
Epoch 3 / iter 0, loss = 0.7877
Epoch 3 / iter 1, loss = 0.5335
Epoch 3 / iter 2, loss = 0.7007
Epoch 3 / iter 3, loss = 0.5667
Epoch 3 / iter 4, loss = 1.4431
Epoch 4 / iter 0, loss = 0.7081
Epoch 4 / iter 1, loss = 0.5871
Epoch 4 / iter 2, loss = 0.6614
Epoch 4 / iter 3, loss = 0.5685
Epoch 4 / iter 4, loss = 0.4888
Epoch 5 / iter 0, loss = 0.6105
Epoch 5 / iter 1, loss = 0.6129
Epoch 5 / iter 2, loss = 0.5951
Epoch 5 / iter 3, loss = 0.4739
Epoch 5 / iter 4, loss = 0.4920
Epoch 6 / iter 0, loss = 0.5570
Epoch 6 / iter 1, loss = 0.4498
Epoch 6 / iter 2, loss = 0.4739
Epoch 6 / iter 3, loss = 0.6205
Epoch 6 / iter 4, loss = 0.3162
Epoch 7 / iter 0, loss = 0.4873
Epoch 7 / iter 1, loss = 0.4770
Epoch 7 / iter 2, loss = 0.5167
Epoch 7 / iter 3, loss = 0.4814
Epoch 7 / iter 4, loss = 0.4300
Epoch 8 / iter 0, loss = 0.5070
Epoch 8 / iter 1, loss = 0.4072
Epoch 8 / iter 2, loss = 0.4273
Epoch 8 / iter 3, loss = 0.5075
Epoch 8 / iter 4, loss = 0.4582
Epoch 9 / iter 0, loss = 0.4634
Epoch 9 / iter 1, loss = 0.3925
Epoch 9 / iter 2, loss = 0.3741
Epoch 9 / iter 3, loss = 0.4730
Epoch 9 / iter 4, loss = 0.3877
Epoch 10 / iter 0, loss = 0.4417
Epoch 10 / iter 1, loss = 0.3678
Epoch 10 / iter 2, loss = 0.3998
Epoch 10 / iter 3, loss = 0.3895
Epoch 10 / iter 4, loss = 0.2928
Epoch 11 / iter 0, loss = 0.3799
Epoch 11 / iter 1, loss = 0.4454
Epoch 11 / iter 2, loss = 0.3890
Epoch 11 / iter 3, loss = 0.2760
Epoch 11 / iter 4, loss = 0.9479
Epoch 12 / iter 0, loss = 0.3421
Epoch 12 / iter 1, loss = 0.4236
Epoch 12 / iter 2, loss = 0.3085
Epoch 12 / iter 3, loss = 0.3301
Epoch 12 / iter 4, loss = 0.2666
Epoch 13 / iter 0, loss = 0.4007
Epoch 13 / iter 1, loss = 0.2651
Epoch 13 / iter 2, loss = 0.3080
Epoch 13 / iter 3, loss = 0.3342
Epoch 13 / iter 4, loss = 0.5628
Epoch 14 / iter 0, loss = 0.4612
Epoch 14 / iter 1, loss = 0.2704
Epoch 14 / iter 2, loss = 0.2365
Epoch 14 / iter 3, loss = 0.3384
Epoch 14 / iter 4, loss = 0.5850
Epoch 15 / iter 0, loss = 0.2574
Epoch 15 / iter 1, loss = 0.3246
Epoch 15 / iter 2, loss = 0.3269
Epoch 15 / iter 3, loss = 0.2768
Epoch 15 / iter 4, loss = 0.2229
Epoch 16 / iter 0, loss = 0.3139
Epoch 16 / iter 1, loss = 0.2253
Epoch 16 / iter 2, loss = 0.2466
Epoch 16 / iter 3, loss = 0.2771
Epoch 16 / iter 4, loss = 0.1955
Epoch 17 / iter 0, loss = 0.2702
Epoch 17 / iter 1, loss = 0.2423
Epoch 17 / iter 2, loss = 0.2742
Epoch 17 / iter 3, loss = 0.2354
Epoch 17 / iter 4, loss = 0.2795
Epoch 18 / iter 0, loss = 0.2166
Epoch 18 / iter 1, loss = 0.2446
Epoch 18 / iter 2, loss = 0.2194
Epoch 18 / iter 3, loss = 0.2442
Epoch 18 / iter 4, loss = 0.6518
Epoch 19 / iter 0, loss = 0.2280
Epoch 19 / iter 1, loss = 0.2252
Epoch 19 / iter 2, loss = 0.2330
Epoch 19 / iter 3, loss = 0.1982
Epoch 19 / iter 4, loss = 0.2439
Epoch 20 / iter 0, loss = 0.2193
Epoch 20 / iter 1, loss = 0.1730
Epoch 20 / iter 2, loss = 0.1864
Epoch 20 / iter 3, loss = 0.2358
Epoch 20 / iter 4, loss = 0.2545
Epoch 21 / iter 0, loss = 0.1825
Epoch 21 / iter 1, loss = 0.2234
Epoch 21 / iter 2, loss = 0.1961
Epoch 21 / iter 3, loss = 0.1646
Epoch 21 / iter 4, loss = 0.5058
Epoch 22 / iter 0, loss = 0.2102
Epoch 22 / iter 1, loss = 0.1841
Epoch 22 / iter 2, loss = 0.1455
Epoch 22 / iter 3, loss = 0.1759
Epoch 22 / iter 4, loss = 0.1144
Epoch 23 / iter 0, loss = 0.1487
Epoch 23 / iter 1, loss = 0.1996
Epoch 23 / iter 2, loss = 0.1558
Epoch 23 / iter 3, loss = 0.1773
Epoch 23 / iter 4, loss = 0.1193
Epoch 24 / iter 0, loss = 0.1569
Epoch 24 / iter 1, loss = 0.1714
Epoch 24 / iter 2, loss = 0.1640
Epoch 24 / iter 3, loss = 0.1739
Epoch 24 / iter 4, loss = 0.1211
Epoch 25 / iter 0, loss = 0.1765
Epoch 25 / iter 1, loss = 0.1683
Epoch 25 / iter 2, loss = 0.1181
Epoch 25 / iter 3, loss = 0.1568
Epoch 25 / iter 4, loss = 0.0671
Epoch 26 / iter 0, loss = 0.1391
Epoch 26 / iter 1, loss = 0.1591
Epoch 26 / iter 2, loss = 0.1657
Epoch 26 / iter 3, loss = 0.1291
Epoch 26 / iter 4, loss = 0.0478
Epoch 27 / iter 0, loss = 0.1481
Epoch 27 / iter 1, loss = 0.1562
Epoch 27 / iter 2, loss = 0.1538
Epoch 27 / iter 3, loss = 0.1093
Epoch 27 / iter 4, loss = 0.1248
Epoch 28 / iter 0, loss = 0.1272
Epoch 28 / iter 1, loss = 0.1269
Epoch 28 / iter 2, loss = 0.1575
Epoch 28 / iter 3, loss = 0.1402
Epoch 28 / iter 4, loss = 0.0650
Epoch 29 / iter 0, loss = 0.1358
Epoch 29 / iter 1, loss = 0.1347
Epoch 29 / iter 2, loss = 0.1127
Epoch 29 / iter 3, loss = 0.1409
Epoch 29 / iter 4, loss = 0.0780
Epoch 30 / iter 0, loss = 0.1163
Epoch 30 / iter 1, loss = 0.1397
Epoch 30 / iter 2, loss = 0.1168
Epoch 30 / iter 3, loss = 0.1325
Epoch 30 / iter 4, loss = 0.0625
Epoch 31 / iter 0, loss = 0.1143
Epoch 31 / iter 1, loss = 0.1299
Epoch 31 / iter 2, loss = 0.1249
Epoch 31 / iter 3, loss = 0.1121
Epoch 31 / iter 4, loss = 0.0920
Epoch 32 / iter 0, loss = 0.1046
Epoch 32 / iter 1, loss = 0.1377
Epoch 32 / iter 2, loss = 0.1026
Epoch 32 / iter 3, loss = 0.1161
Epoch 32 / iter 4, loss = 0.0859
Epoch 33 / iter 0, loss = 0.1070
Epoch 33 / iter 1, loss = 0.1089
Epoch 33 / iter 2, loss = 0.1153
Epoch 33 / iter 3, loss = 0.1099
Epoch 33 / iter 4, loss = 0.0773
Epoch 34 / iter 0, loss = 0.1021
Epoch 34 / iter 1, loss = 0.1124
Epoch 34 / iter 2, loss = 0.1033
Epoch 34 / iter 3, loss = 0.1074
Epoch 34 / iter 4, loss = 0.0365
Epoch 35 / iter 0, loss = 0.1015
Epoch 35 / iter 1, loss = 0.1083
Epoch 35 / iter 2, loss = 0.1018
Epoch 35 / iter 3, loss = 0.0939
Epoch 35 / iter 4, loss = 0.1545
Epoch 36 / iter 0, loss = 0.1030
Epoch 36 / iter 1, loss = 0.0972
Epoch 36 / iter 2, loss = 0.0941
Epoch 36 / iter 3, loss = 0.0926
Epoch 36 / iter 4, loss = 0.0574
Epoch 37 / iter 0, loss = 0.1175
Epoch 37 / iter 1, loss = 0.0848
Epoch 37 / iter 2, loss = 0.0810
Epoch 37 / iter 3, loss = 0.0895
Epoch 37 / iter 4, loss = 0.1162
Epoch 38 / iter 0, loss = 0.0970
Epoch 38 / iter 1, loss = 0.0768
Epoch 38 / iter 2, loss = 0.0787
Epoch 38 / iter 3, loss = 0.1028
Epoch 38 / iter 4, loss = 0.0486
Epoch 39 / iter 0, loss = 0.0706
Epoch 39 / iter 1, loss = 0.0998
Epoch 39 / iter 2, loss = 0.0904
Epoch 39 / iter 3, loss = 0.0837
Epoch 39 / iter 4, loss = 0.0791
Epoch 40 / iter 0, loss = 0.0808
Epoch 40 / iter 1, loss = 0.0705
Epoch 40 / iter 2, loss = 0.0750
Epoch 40 / iter 3, loss = 0.1061
Epoch 40 / iter 4, loss = 0.0531
Epoch 41 / iter 0, loss = 0.0857
Epoch 41 / iter 1, loss = 0.0814
Epoch 41 / iter 2, loss = 0.0845
Epoch 41 / iter 3, loss = 0.0695
Epoch 41 / iter 4, loss = 0.0438
Epoch 42 / iter 0, loss = 0.0809
Epoch 42 / iter 1, loss = 0.0790
Epoch 42 / iter 2, loss = 0.0740
Epoch 42 / iter 3, loss = 0.0759
Epoch 42 / iter 4, loss = 0.0383
Epoch 43 / iter 0, loss = 0.0753
Epoch 43 / iter 1, loss = 0.0751
Epoch 43 / iter 2, loss = 0.0787
Epoch 43 / iter 3, loss = 0.0706
Epoch 43 / iter 4, loss = 0.0546
Epoch 44 / iter 0, loss = 0.0729
Epoch 44 / iter 1, loss = 0.0765
Epoch 44 / iter 2, loss = 0.0675
Epoch 44 / iter 3, loss = 0.0760
Epoch 44 / iter 4, loss = 0.0414
Epoch 45 / iter 0, loss = 0.0715
Epoch 45 / iter 1, loss = 0.0669
Epoch 45 / iter 2, loss = 0.0767
Epoch 45 / iter 3, loss = 0.0660
Epoch 45 / iter 4, loss = 0.0757
Epoch 46 / iter 0, loss = 0.0850
Epoch 46 / iter 1, loss = 0.0703
Epoch 46 / iter 2, loss = 0.0664
Epoch 46 / iter 3, loss = 0.0595
Epoch 46 / iter 4, loss = 0.1010
Epoch 47 / iter 0, loss = 0.0799
Epoch 47 / iter 1, loss = 0.0588
Epoch 47 / iter 2, loss = 0.0611
Epoch 47 / iter 3, loss = 0.0660
Epoch 47 / iter 4, loss = 0.0544
Epoch 48 / iter 0, loss = 0.0811
Epoch 48 / iter 1, loss = 0.0589
Epoch 48 / iter 2, loss = 0.0640
Epoch 48 / iter 3, loss = 0.0650
Epoch 48 / iter 4, loss = 0.0193
Epoch 49 / iter 0, loss = 0.0617
Epoch 49 / iter 1, loss = 0.0592
Epoch 49 / iter 2, loss = 0.0608
Epoch 49 / iter 3, loss = 0.0693
Epoch 49 / iter 4, loss = 0.0813
参考文章链接:百度飞浆案例之波士顿房价预测任务
4.使用飞桨重写波士顿房价预测
飞桨支持两种深度学习任务的代码编写方式,更方便调试的动态图模式和性能更好并便于部署的静态图模式。
- 动态图模式(命令式编程范式,类比Python):解析式的执行方式。用户无需预先定义完整的网络结构,每写一行网络代码,即可同时获得计算结果。
- 静态图模式(声明式编程范式,类比C++):先编译后执行的方式。用户需预先定义完整的网络结构,再对网络结构进行编译优化后,才能执行获得计算结果。
飞桨框架2.0及之后的版本,默认使用动态图模式进行编码,同时提供了完备的动转静支持,开发者仅需添加一个装饰器( to_static ),飞桨会自动将动态图的程序转换为静态图的program,并使用该program训练并可保存静态模型以实现推理部署。
实现代码:
#加载飞桨、NumPy和相关类库
import paddle
from paddle.nn import Linear
import paddle.nn.functional as F
import numpy as np
import os
import random
#加载数据
def load_data():
# 从文件导入数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ', dtype=np.float32)
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原始数据集拆分成训练集和测试集
# 使用80%的数据做训练,20%的数据做测试,测试集和训练集不能存在交集
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算训练集的最大值和最小值
maximums, minimums = training_data.max(axis=0), training_data.min(axis=0)
# 记录数据的归一化参数,在预测时对数据进行归一化
global max_values
global min_values
max_values = maximums
min_values = minimums
# 对数据进行归一化处理
for i in range(feature_num):
data[:, i] = (data[:, i] - min_values[i]) / (maximums[i] - minimums[i])
# 划分训练集和测试集
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
#模型设计
class Regressor(paddle.nn.Layer):
# self代表类的实例自身
def __init__(self):
# 初始化父类中的一些参数
super(Regressor, self).__init__()
# 定义一层全连接层,输入维度是13,输出维度是1
self.fc = Linear(in_features=13, out_features=1)
# 网络的前向计算
def forward(self, inputs):
x = self.fc(inputs)
return x
#通过load_one_example函数实现从数据集中抽一条样本作为测试样本。
def load_one_example():
training_data,test_data = load_data()
# 从测试集中随机选择一条作为推理数据
idx = np.random.randint(0, test_data.shape[0])
idx = -10
one_data, label = test_data[idx, :-1], test_data[idx, -1]
# 将数据格式修改为[1,13]
one_data = one_data.reshape([1,-1])
return one_data, label
if __name__ == '__main__':
# 声明定义好的线性回归模型
model = Regressor()
# 开启模型训练模式,模型的状态设置为train
model.train()
# 使用load_data加载训练集数据和测试集数据
training_data, test_data = load_data()
# 定义优化算法,采用随机梯度下降SGD
# 学习率设置为0.01
opt = paddle.optimizer.SGD(learning_rate=0.005, parameters=model.parameters())
epoch_num = 20 # 设置模型训练轮次
batch_size = 10 # 设置批大小,即一次模型训练使用的样本数量
#模型的训练过程采用二层循环嵌套方式
# 定义模型训练轮次epoch(外层循环)
for epoch_id in range(epoch_num):
# 在每轮迭代开始之前,对训练集数据进行样本乱序
np.random.shuffle(training_data)
# 对训练集数据进行拆分,batch_size设置为10
mini_batches = [training_data[k:k + batch_size] for k in range(0, len(training_data), batch_size)]
# 定义模型训练(内层循环)
for iter_id, mini_batch in enumerate(mini_batches):
x = np.array(mini_batch[:, :-1]) # 将当前批的房价影响因素的数据转换为np.array格式
y = np.array(mini_batch[:, -1:]) # 将当前批的标签数据(真实房价)转换为np.array格式
# 将np.array格式的数据转为张量tensor格式
house_features = paddle.to_tensor(x, dtype='float32')
prices = paddle.to_tensor(y, dtype='float32')
# 前向计算
predicts = model(house_features)
# 计算损失,损失函数采用平方误差square_error_cost
loss = F.square_error_cost(predicts, label=prices)
avg_loss = paddle.mean(loss)
if iter_id % 20 == 0:
print("epoch: {}, iter: {}, loss is: {}".format(epoch_id, iter_id, avg_loss.numpy()))
# 反向传播,计算每层参数的梯度值
avg_loss.backward()
# 更新参数,根据设置好的学习率迭代一步
opt.step()
# 清空梯度变量,进行下一轮计算
opt.clear_grad()
# 保存模型参数,文件名为LR_model.pdparams
paddle.save(model.state_dict(), 'LR_model.pdparams')
print("模型保存成功, 模型参数保存在LR_model.pdparams中")
# 将模型参数保存到指定路径中
model_dict = paddle.load('LR_model.pdparams')
model.load_dict(model_dict)
# 将模型状态修改为.eval
model.eval()
# 声明定义好的线性回归模型
one_data, label = load_one_example()
# 将数据格式转换为张量
one_data = paddle.to_tensor(one_data, dtype="float32")
predict = model(one_data)
# 对推理结果进行后处理
predict = predict * (max_values[-1] - min_values[-1]) + min_values[-1]
# 对label数据进行后处理
label = label * (max_values[-1] - min_values[-1]) + min_values[-1]
print("Inference result is {}, the corresponding label is {}".format(predict.numpy(), label))
print("######################使用飞桨高层API实现波士顿房价预测任务#######################")
paddle.set_default_dtype("float32")
# 使用飞桨高层API加载波士顿房价预测数据集,包括训练集和测试集
train_dataset = paddle.text.datasets.UCIHousing(mode='train')
eval_dataset = paddle.text.datasets.UCIHousing(mode='test')
# 模型训练
model = paddle.Model(Regressor())
model.prepare(paddle.optimizer.SGD(learning_rate=0.005, parameters=model.parameters()),
paddle.nn.MSELoss())
model.fit(train_dataset, eval_dataset, epochs=10, batch_size=10, verbose=1)
result = model.evaluate(eval_dataset, batch_size=10)
print("result:", result)
result_pred = model.predict(one_data, batch_size=1) # result_pred是一个list,元素数目对应模型的输出数目
result_pred = result_pred[0] # tuple,其中第一个值是array
print("Inference result is {}, the corresponding label is {}".format(result_pred[0][0], label))
执行效果:
epoch: 0, iter: 0, loss is: 0.258030503988266
epoch: 0, iter: 20, loss is: 0.14185956120491028
epoch: 0, iter: 40, loss is: 0.08604950457811356
epoch: 1, iter: 0, loss is: 0.2451344132423401
epoch: 1, iter: 20, loss is: 0.10678903758525848
epoch: 1, iter: 40, loss is: 0.062011513859033585
epoch: 2, iter: 0, loss is: 0.21440701186656952
epoch: 2, iter: 20, loss is: 0.1973455548286438
epoch: 2, iter: 40, loss is: 0.09936390817165375
epoch: 3, iter: 0, loss is: 0.15263861417770386
epoch: 3, iter: 20, loss is: 0.04788539931178093
epoch: 3, iter: 40, loss is: 0.07627897709608078
epoch: 4, iter: 0, loss is: 0.06664790958166122
epoch: 4, iter: 20, loss is: 0.19398480653762817
epoch: 4, iter: 40, loss is: 0.27896788716316223
epoch: 5, iter: 0, loss is: 0.08476421236991882
epoch: 5, iter: 20, loss is: 0.04524032771587372
epoch: 5, iter: 40, loss is: 0.2460382729768753
epoch: 6, iter: 0, loss is: 0.1367662250995636
epoch: 6, iter: 20, loss is: 0.08492419868707657
epoch: 6, iter: 40, loss is: 0.015655431896448135
epoch: 7, iter: 0, loss is: 0.155685156583786
epoch: 7, iter: 20, loss is: 0.08739550411701202
epoch: 7, iter: 40, loss is: 0.017319075763225555
epoch: 8, iter: 0, loss is: 0.033760540187358856
epoch: 8, iter: 20, loss is: 0.0434451699256897
epoch: 8, iter: 40, loss is: 0.022688254714012146
epoch: 9, iter: 0, loss is: 0.043561890721321106
epoch: 9, iter: 20, loss is: 0.11841733008623123
epoch: 9, iter: 40, loss is: 0.014307085424661636
epoch: 10, iter: 0, loss is: 0.05903610959649086
epoch: 10, iter: 20, loss is: 0.05533682554960251
epoch: 10, iter: 40, loss is: 0.03706558421254158
epoch: 11, iter: 0, loss is: 0.055392153561115265
epoch: 11, iter: 20, loss is: 0.05402038246393204
epoch: 11, iter: 40, loss is: 0.05260971188545227
epoch: 12, iter: 0, loss is: 0.03315025195479393
epoch: 12, iter: 20, loss is: 0.032783109694719315
epoch: 12, iter: 40, loss is: 0.2286667823791504
epoch: 13, iter: 0, loss is: 0.0501670241355896
epoch: 13, iter: 20, loss is: 0.03353588655591011
epoch: 13, iter: 40, loss is: 0.01641666330397129
epoch: 14, iter: 0, loss is: 0.03694063425064087
epoch: 14, iter: 20, loss is: 0.07043042778968811
epoch: 14, iter: 40, loss is: 0.021749012172222137
epoch: 15, iter: 0, loss is: 0.05543922632932663
epoch: 15, iter: 20, loss is: 0.07714284956455231
epoch: 15, iter: 40, loss is: 0.12558944523334503
epoch: 16, iter: 0, loss is: 0.07065430283546448
epoch: 16, iter: 20, loss is: 0.0287704486399889
epoch: 16, iter: 40, loss is: 0.006807880010455847
epoch: 17, iter: 0, loss is: 0.033732857555150986
epoch: 17, iter: 20, loss is: 0.03706945851445198
epoch: 17, iter: 40, loss is: 0.017718113958835602
epoch: 18, iter: 0, loss is: 0.07457436621189117
epoch: 18, iter: 20, loss is: 0.046510472893714905
epoch: 18, iter: 40, loss is: 0.00983769353479147
epoch: 19, iter: 0, loss is: 0.03274852782487869
epoch: 19, iter: 20, loss is: 0.02240535244345665
epoch: 19, iter: 40, loss is: 0.023245973512530327
模型保存成功, 模型参数保存在LR_model.pdparams中
Inference result is [[21.125443]], the corresponding label is 19.700000762939453
######################使用飞桨高层API实现波士顿房价预测任务#######################
The loss value printed in the log is the current step, and the metric is the average value of previous steps.
Epoch 1/10
step 41/41 [==============================] - loss: 285.6673 - 3ms/step
Eval begin...
step 11/11 [==============================] - loss: 94.2743 - 1ms/step
Eval samples: 102
Epoch 2/10
step 41/41 [==============================] - loss: 52.4783 - 1ms/step
Eval begin...
step 11/11 [==============================] - loss: 33.2306 - 997us/step
Eval samples: 102
Epoch 3/10
step 41/41 [==============================] - loss: 20.3978 - 1ms/step
Eval begin...
step 11/11 [==============================] - loss: 25.1834 - 816us/step
Eval samples: 102
Epoch 4/10
step 41/41 [==============================] - loss: 20.8903 - 1ms/step
Eval begin...
step 11/11 [==============================] - loss: 32.8978 - 997us/step
Eval samples: 102
Epoch 5/10
step 41/41 [==============================] - loss: 14.6813 - 1ms/step
Eval begin...
step 11/11 [==============================] - loss: 42.8505 - 1ms/step
Eval samples: 102
Epoch 6/10
step 41/41 [==============================] - loss: 28.3935 - 1ms/step
Eval begin...
step 11/11 [==============================] - loss: 51.6567 - 907us/step
Eval samples: 102
Epoch 7/10
step 41/41 [==============================] - loss: 20.2560 - 1ms/step
Eval begin...
step 11/11 [==============================] - loss: 57.6026 - 1ms/step
Eval samples: 102
Epoch 8/10
step 41/41 [==============================] - loss: 23.6186 - 2ms/step
Eval begin...
step 11/11 [==============================] - loss: 61.2470 - 997us/step
Eval samples: 102
Epoch 9/10
step 41/41 [==============================] - loss: 12.1101 - 1ms/step
Eval begin...
step 11/11 [==============================] - loss: 62.9535 - 911us/step
Eval samples: 102
Epoch 10/10
step 41/41 [==============================] - loss: 16.1943 - 1ms/step
Eval begin...
step 11/11 [==============================] - loss: 63.7898 - 1ms/step
Eval samples: 102
Eval begin...
step 10/11 - loss: 7.2215 - 1ms/step
step 11/11 - loss: 63.7898 - 1ms/step
Eval samples: 102
result: {'loss': [63.78981018066406]}
Predict begin...
step 1/1 [==============================] - 0s/step
Predict samples: 13
Inference result is 16.123117446899414, the corresponding label is 19.700000762939453