近年来的科学研究不断证实,不确定性才是客观世界的本质属性。换句话说,上帝还真就掷骰子。不确定性的世界只能使用概率模型来描述,正是对概率的刻画促成了信息论的诞生。
1.什么是熵
熵(Entropy) 是一个来自热力学的概念,由物理学家鲁道夫·克劳修斯(Rudolf Clausius)引入。它描述了一个系统的无序程度或混乱程度。在热力学中,熵反映了系统状态的微观可能性数目:熵越高,系统的无序程度越大,系统的微观状态数目也越多。
在生活中,信息的载体是消息,而不同的消息带来的信息即使在直观感觉上也是不尽相同的。比如,“中国男子足球队获得世界杯冠军”的信息显然要比“中国男子乒乓球队获得世界杯冠军”的信息要大得多。究其原因,国足勇夺世界杯是如假包换的小概率事件(如果不是不可能事件的话),发生的可能性微乎其微;而男乒夺冠已经让国人习以为常,丢掉冠军的可能性才是意外。因此,以不确定性来度量信息是一种合理的方式。不确定性越大的消息可能性越小,其提供的信息量就越大。
熵的本质即一个系统内在的混乱程度。假象你有一个刚整理好的书架,每本书都按照大小和颜色排列得整整齐齐。这时,书架的熵很低,因为一切都井然有序。但如果你把书随机地放回书架,那么书的排列方式就会变得非常多样,熵就增加了。
总的来说,熵是一个衡量无序程度或不确定性的指标。在物理学中,它描述了系统的混乱程度;在信息论中,它描述了信息的不确定性。熵越高,意味着系统的无序程度越大,或者信息的不确定性越高。
熵增定理就是说,也被称为热力学第二定律,是热力学中的一个基本原理,在没有外部干预的情况下,事物总是倾向于变得更加混乱和无序。这个原理适用于物理世界,也适用于信息、经济和社会系统。
2.熵的计算
在信息论中,熵是用来量化信息的不确定性或随机性的度量。信息论中的熵(香农熵)用符号H表示,它与事件发生的概率分布有关。具体公式为:
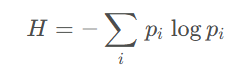
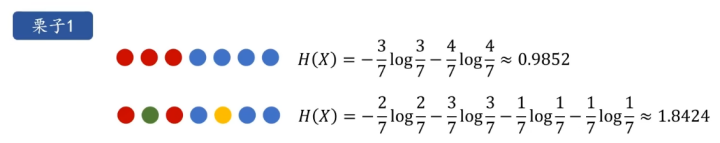
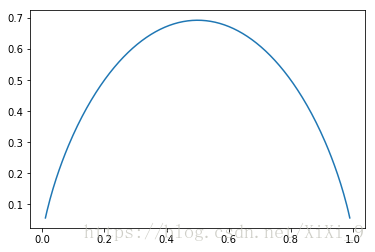
下面的python代码画出pi,取值为0.01到0.99的过程中,熵H(X)的取值曲线图。
import numpy as np
import matplotlib.pyplot as plt
#计算二分类中熵的值,设二分类中X的取值x1和x2,取x1的概率为p,则取x2的概率为1-p。
#如果传入的p是一个数组,则方法entopy(p)会计算p中每个元素值的熵,然后以数组的形式返回所有的结果
def entropy(p):
return -p * np.log(p) - (1-p) * np.log(1-p)
#pVec是一个等差数组,包括200个元素,起始值为0.01,最后一个值为0.99。
pVec = np.linspace(start = 0.01, stop =0.99, num =200)
print(type(pVec))
plt.plot(pVec,entropy(pVec)) #画图
plt.show() # 将图显示出来
3.条件熵与信息增益
条件熵和信息增益是信息论和机器学习中的两个重要概念,它们都与数据的不确定性和信息的减少有关。让我们来通俗地解释一下这两个概念:
- 条件熵
条件熵可以通俗地理解为:在已知某个条件(或信息)的情况下,某一事件剩余的不确定性。
举个例子: 假设你想预测明天是否会下雨(事件 Y)。如果没有任何额外信息,预测的难度较大(不确定性高)。但如果你知道今天的天气(例如今天乌云密布,记为条件 X),那么预测明天是否下雨的不确定性就会降低。条件熵就是量化这种“已知今天天气后,预测明天下雨的不确定性”。
- 信息增益
信息增益是决策树算法中一个非常重要的概念,它用来衡量一个特征对数据集分类的贡献程度。通俗来说,信息增益可以帮助我们判断一个特征是否“有用”,以及有多“有用”。
举个例子,如果你知道今天是晴天,那么你可以预测冰淇淋的销量会很高,因为晴天通常意味着人们更愿意买冰淇淋。这个信息(天气是晴天)帮助你减少了对销量的不确定性,这就是信息增益。在机器学习中,我们经常用信息增益来选择特征,因为那些能最大程度减少不确定性的特征,通常对预测结果更有帮助。例如,在选择一个模型的特征时,我们可能会优先选择那些信息增益高的特征,因为它们提供了更多的信息,帮助我们更好地预测结果。
总结一下,条件熵是已知某些信息时,对结果不确定性的度量;而信息增益则是衡量通过知道某个特征,我们能减少多少不确定性的指标。这两个概念都与信息的减少和决策的不确定性有关。
4.KL散度
KL散度,全称是Kullback-Leibler散度,它的名字来源于两位数学家Solan Kullback和Richard Leibler,他们在1951年提出了这个概念。KL散度是一个衡量两个概率分布之间差异的工具。它可以帮助我们判断两个分布是否相似,或者一个分布对另一个分布的“信息损失”有多大。在实际应用中,KL散度常用于机器学习中的模型评估,比如比较模型预测的概率分布和真实分布之间的差异。
通俗地解释一下KL散度:
想象一下,你有两个箱子,每个箱子里都装着不同颜色的球。第一个箱子代表了真实世界中球的颜色分布,我们称之为真实分布;第二个箱子是你对球颜色的猜测,我们称之为猜测分布。 现在,你想要衡量你的猜测有多接近真实情况。KL散度就是用来衡量这两个分布之间差异的一个工具。具体来说,它计算的是在真实分布的情况下,使用猜测分布来预测结果时,会损失多少信息。
举个例子: - 真实分布:假设真实箱子里有70%的红球和30%的蓝球。 - 猜测分布:你猜测箱子里有50%的红球和50%的蓝球。
KL散度会计算,如果你用猜测分布来预测球的颜色,相比于真实分布,你平均会损失多少信息。在这个例子中,因为你的猜测分布没有考虑到红球实际上比蓝球多,所以你的猜测会损失一些信息。
KL散度的计算公式是这样的:
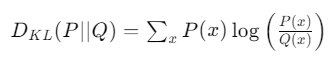
其中,P是真实分布,Q是猜测分布,x是可能的结果,比如球的颜色。 KL散度有几个重要的性质: - 非负性:KL散度总是非负的,这意味着它永远不会是负数。如果两个分布完全相同,那么KL散度为0。 - 不对称性:KL散度不是对称的,也就是说, (Q∣∣P)通常是不相等的。 - 不是真正的距离:虽然KL散度衡量了两个分布之间的差异,但它并不满足传统意义上“距离”的所有性质,比如三角不等式。
总的来说,KL散度是一个衡量概率分布之间差异的有用工具,它在机器学习、信息论和统计学等领域有着广泛的应用。
5.最大熵原理
最大熵原理是一个在信息论、统计物理和机器学习等领域中非常重要的概念。通俗来说,最大熵原理可以这样解释:
想象一下,你有一个装满不同颜色球的盒子,但你不知道盒子里具体有多少种颜色和每种颜色有多少个球。现在,你要猜测盒子里球的分布情况。最大熵原理告诉我们,在你没有任何额外信息的情况下,最合理的猜测是所有颜色的球数量是均匀分布的。也就是说,每种颜色的球出现的概率是相同的,这样的情况下,系统的不确定性(或者说“熵”)是最大的。
在统计学和机器学习中,最大熵原理通常用来指导我们如何从有限的数据中做出最不偏不倚的预测。比如,我们想要预测一个单词序列中下一个出现的单词是什么。如果我们没有任何上下文信息,最合理的预测就是每个单词出现的概率都是相同的,因为这样的情况下,我们对下一个单词的不确定性是最大的。
在信息论中,熵是一个度量信息量或不确定性的指标。最大熵原理告诉我们,在给定一些约束条件(比如某些已知的平均值或概率)的情况下,最不确定的分布(即熵最大的分布)是最优的选择。这种选择通常被认为是最公平、最没有偏见的,因为它没有对任何特定的结果做出额外的假设。
简而言之,最大熵原理就是一种在不确定性中寻求最大不确定性的方法,它帮助我们在缺乏信息的情况下做出最公正、最不偏不倚的决策。
6.小结
本节阐述了工智能必备的信息论基础,着重于抽象概念的解释而非数学公式的推导,其要点如下:
- 信息论处理的是客观世界中的不确定性;
- 条件熵和信息增益是分类问题中的重要参数;
- KL 散度用于描述两个不同概率分布之间的差异;
- 最大熵原理是分类问题中的常用准则。