1.Ollama简介
2024年4月19日消息,Meta推出了新版本Llama人工智能模型Llama 3,希望与ChatGPT竞争。而Ollama是一个开源的 LLM(大型语言模型)服务工具,用于简化在本地运行大语言模型,降低使用大语言模型的门槛,使得大模型的开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新大语言模型,包括如Llama 3、Phi 3、Mistral、Gemma等开源的大型语言模型。
因此,Ollama与Llama的关系:Llama是大语言模型,而Ollama是大语言模型(不限于Llama模型)便捷的管理和运维工具。
2.Ollama部署运行
1).安装ollama
访问官方网站:Ollama官方网站。https://ollama.com/
2).下载安装包:点击Download按钮,下载适用于您设备的Ollama安装包。
3). 验证安装
ollama --version

4).常用命令
ollama有类似docker的命令。下面是一些模型(large language models)的操作命令:
- ollama list:显示模型列表
- ollama show:显示模型的信息
- ollama pull:拉取模型
- ollama push:推送模型
- ollama cp:拷贝一个模型
- ollama rm:删除一个模型
- ollama run:运行一个模型
3.ollama部署通义千问模型
在ollama官网选择models,找到qwen2模型,这里选择7b版本。
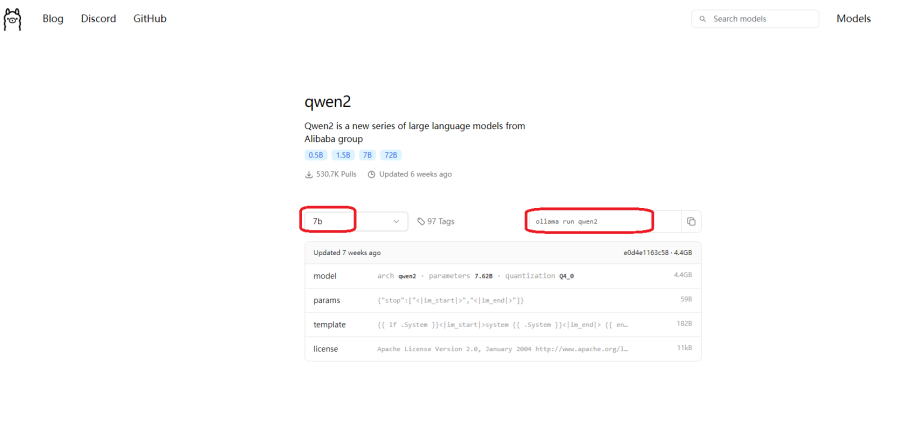
运行以下命令下载并运行模型。
ollama run qwen2:7b
下载&启动运行成功如下:

对话测试如下:
>>> 你好?
你好!有什么问题我可以帮助你解答吗?
>>> 你是谁?
我是阿里云开发的一款超大规模语言模型,我叫通义千问。作为一个AI助手,我的主要任务是回答用户的问题、提供信息和在各个领域与用户进行交流。我被设计为能理解自然语
言,并以简洁明了的方式提供帮助或解答问题。请随时告诉我你有需要了解的内容,我会尽力提供支持!
>>> 什么是通义千问?
通义千问是阿里云研发的超大规模语言模型,它具有生成人类级别文本、回答问题和与用户进行对话的能力。作为一个AI助手,我旨在帮助解答问题、提供建议或进行信息交流。
请告诉我你有什么需要了解的内容或者想要探讨的话题,我会尽力提供帮助!
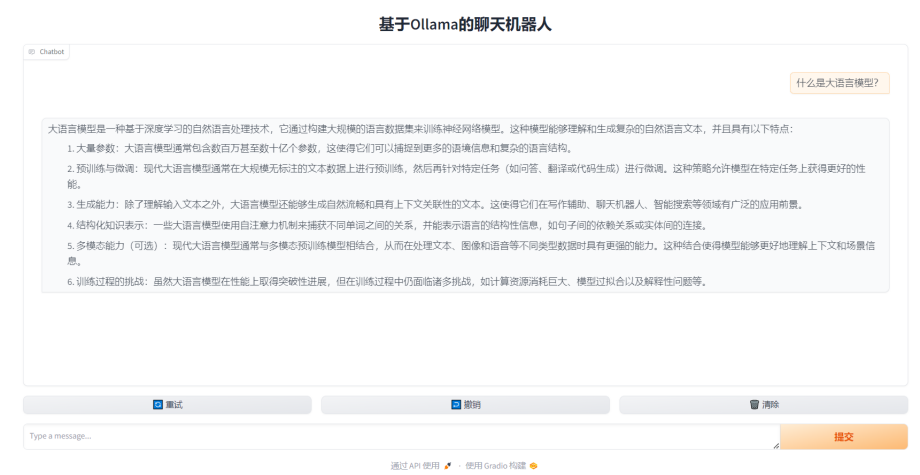
>>> 什么是大语言模型?
大语言模型(Large Language Model, LLM)是指通过大量数据训练的复杂深度学习模型,能够处理自然语言任务并生成与输入相关的文本。这些模型在结构上通常包含许多层神
经网络和大量的参数,使其具有高度的学习能力和适应性。
高级用法:
Ollama不仅提供了简单的命令行操作,还允许用户通过高级配置来充分利用Qwen2模型的功能。
样例1:调整生成文本的多样性 通过调整top_p和top_k参数,我们可以控制生成文本的多样性和连贯性: top_k 降低生成无意义文本的概率。较高的值(例如 100)将提供更多样的回答,而较低的值(例如 10)将更为保守。(默认:40) int top_k 40 top_p 与 top-k 一起工作。较高的值(例如 0.95)将导致文本更多样化,而较低的值(例如 0.5)将生成更集中和保守的文本。(默认:0.9) float top_p 0.9
ollama run qwen2:7b --top_p 0.9 --top_k 50
样例2:避免重复生成文本 在需要避免模型重复生成相同文本的场景中,可以调整repeat_penalty参数: repeat_penalty 设置对重复的惩罚强度。较高的值(例如 1.5)将更强烈地惩罚重复,而较低的值(例如 0.9)将更宽容。(默认:1.1)
ollama run qwen2:7b --repeat_penalty 2.0
4.gradio和ollama实现LLM对话功能
安装依赖:
pip install ollama
pip install gradio
实现代码:
import gradio as gr
from ollama import Client
client = Client(host="127.0.0.1:11434")
def chat_fn(message, history):
messages = []
msg = {'role': 'system', 'content': 'You are a helpful assistant.'}
messages.append(msg)
for m in history:
msg = {'role': 'assistant', 'content': m[0]}
messages.append(msg)
msg = {'role': 'user', 'content': m[1]}
messages.append(msg)
msg = {'role': 'user', 'content': message}
messages.append(msg)
response = client.chat(model='qwen2:7b', messages=messages, stream=True)
m = ''
for chunk in response:
m += chunk['message']['content']
yield m
if chunk['done'] == True:
print("\n")
print(f"total_duration : {chunk['total_duration']/1000000000:.6f} s")
print(f"load_duration : {chunk['load_duration']/1000000000:.6f} s")
print(f"prompt_eval_count : {chunk['prompt_eval_count']} Tokens")
print(f"prompt_eval_duration : {chunk['prompt_eval_duration']/1000000000:.6f} s")
print(f"eval_count : {chunk['eval_count']} Tokens")
print(f"eval_duration : {chunk['eval_duration']/1000000000:.6f} s")
gr.ChatInterface(fn=chat_fn,title='基于Ollama的聊天机器人').launch()
运行效果: