图卷积网络Graph Convolutional Network,简称GCN,最近两年大热,取得不少进展。最近,清华大学孙茂松教授组在 arXiv 发布了论文Graph Neural Networks: A Review of Methods and Applications,作者对现有的 GNN 模型做了详尽且全面的综述。GCN就是GNN中的一种重要的分支。
1.什么是卷积Convolution
Convolution的数学定义是:
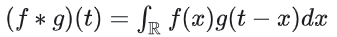
一般称g为作用在f上的filter或kernel。
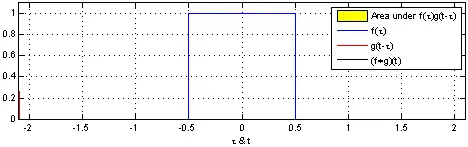
大家常见的CNN二维卷积示意图如下:
在图像里面卷积的概念很直接,因为像素点的排列顺序有明确的上下左右的位置关系。
2.为什么要有GCN
图的结构一般来说是十分不规则的,可以认为是无限维的一种数据,所以它没有平移不变性。而传统的CNN、RNN是针对有限的,有平移不变性的,然而,每一个节点的周围结构可能都是独一无二的,这种结构的数据,就让传统的CNN、RNN瞬间失效。所以很多学者从上个世纪就开始研究怎么处理这类数据了。这里涌现出了很多方法,例如GNN、DeepWalk、node2vec等等,GCN只是其中一种。
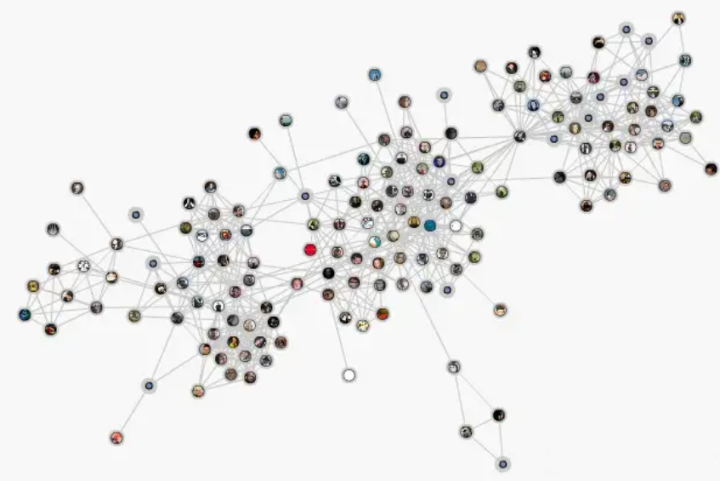
比如这个社交网络抽象出来的graph里面,有的社交vip会关联上万的节点,这些节点没有空间上的位置关系,也就没办法通过上面给出的传统卷积公式进行计算。
GCN(图卷积神经网络),实际上跟CNN的作用一样,就是一个特征提取器,只不过它的对象是图数据。GCN精妙地设计了一种从图数据中提取特征的方法,从而让我们可以使用这些特征去对图数据进行节点分类(node classification)、图分类(graph classification)、边预测(link prediction),还可以顺便得到图的嵌入表示(graph embedding)。
3.GCN的核心公式
GCN 的作用实际上和 CNN 差不多,都是一个特征提取器,只不过 GCN 的处理对象更加复杂。GCN 设计了一种从图数据当中提取特征的方法,从而可以应用到对图数据进行节点分类、图分类、边预测、还可以得到图的嵌入表示。
最终的GCN公式如下:
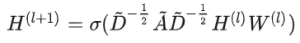
这个公式中:
A波浪=A+I,I是单位矩阵 D波浪是A波浪的度矩阵(degree matrix) H是每一层的特征,对于输入层的话,H就是X σ是非线性激活函数 先不用考虑为什么要这样去设计一个公式。我们现在只用知道:
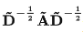 这个部分是可以事先计算好的就可以了。
这个部分是可以事先计算好的就可以了。
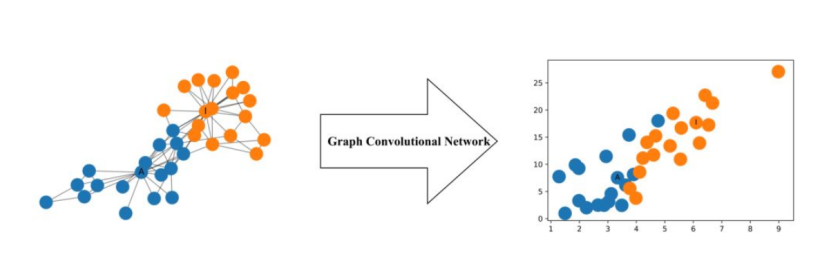
所以对于不需要去了解数学原理、只想应用GCN来解决实际问题的人来说,你只用知道:哦,这个GCN设计了一个牛逼的公式,用这个公式就可以很好地提取图的特征,而一个神经元包含一个函数和一个激活函数,这个公式就代表是神经元里的函数。这就够了,毕竟不是什么事情都需要知道内部原理,这是根据需求决定的。为了直观理解,我们引用论文中的Zachary空手道俱乐部图网络到特征表征的转换图如下:
4.PyTorch简单实现一个GCN
安装torch_geometric包。
pip install torch_geometric
构建方法:首先继承MessagePassing类,接下来重写构造函数和以下三个方法:
- message() #构建消息传递
- aggregate() #将消息聚合到目标节点
- update() #更新消息节点
完整代码如下:
import torch
import torch.nn.functional as F
import torch.nn as nn
import torch_geometric.nn as pyg_nn
from torch_geometric.datasets import Planetoid
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import degree, scatter, add_self_loops
#加载数据集
dataset = Planetoid(root='Cora', name='Cora')
#定义GCN层
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels, add_self_loops=True, bias=True):
super(GCNConv, self).__init__()
self.add_self_loops = add_self_loops
self.edge_index = None
self.linear = pyg_nn.dense.linear.Linear(in_channels, out_channels, weight_initializer='glorot')
if bias:
self.bias = nn.Parameter(torch.Tensor(out_channels, 1))
self.bias = pyg_nn.inits.glorot(self.bias)
else:
self.register_parameter('bias', None)
# 1.消息传递
def message(self, x, edge_index):
# 1.对所有节点进行新的空间映射
x = self.linear(x) # [num_nodes, feature_size]
# 2.添加偏置
if self.bias != None:
x += self.bias.flatten()
# 3.返回source、target信息,对应边的起点和终点
row, col = edge_index # [E]
# 4.获得度矩阵
deg = degree(col, x.shape[0], x.dtype) # [num_nodes]
# 5.度矩阵归一化
deg_inv_sqrt = deg.pow(-0.5) # [num_nodes]
# 6.计算sqrt(deg(i)) * sqrt(deg(j))
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col] # [num_nodes]
# 7.返回所有边的映射
x_j = x[row] # [E, feature_size]
# 8.计算归一化后的节点特征
x_j = norm.view(-1, 1) * x_j # [E, feature_size]
return x_j
# 2.消息聚合
def aggregate(self, x_j, edge_index):
# 1.返回source、target信息,对应边的起点和终点
row, col = edge_index # [E]
# 2.聚合邻居特征
aggr_out = scatter(x_j, row, dim=0, reduce='sum') # [num_nodes, feature_size]
return aggr_out
# 3.节点更新
def update(self, aggr_out):
# 对于GCN没有这个阶段,所以直接返回
return aggr_out
def forward(self, x, edge_index):
# 2.添加自环信息,考虑自身信息
if self.add_self_loops:
edge_index, _ = add_self_loops(edge_index, num_nodes=x.shape[0]) # [2, E]
return self.propagate(edge_index, x=x)
#定义GCN网络
class GCN(nn.Module):
def __init__(self, num_node_features, num_classes):
super(GCN, self).__init__()
self.conv1 = GCNConv(num_node_features, 16)
self.conv2 = GCNConv(16, num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
#模型调用
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
epochs = 200 # 学习轮数
lr = 0.0003 # 学习率
num_node_features = dataset.num_node_features # 每个节点的特征数
num_classes = dataset.num_classes # 每个节点的类别数
data = dataset[0].to(device) # Cora的一张图
# 4.定义模型
model = GCN(num_node_features, num_classes).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr) # 优化器
loss_function = nn.NLLLoss() # 损失函数
# 训练模式
model.train()
for epoch in range(epochs):
optimizer.zero_grad()
pred = model(data)
loss = loss_function(pred[data.train_mask], data.y[data.train_mask]) # 损失
correct_count_train = pred.argmax(axis=1)[data.train_mask].eq(data.y[data.train_mask]).sum().item() # epoch正确分类数目
acc_train = correct_count_train / data.train_mask.sum().item() # epoch训练精度
loss.backward()
optimizer.step()
if epoch % 20 == 0:
print("【EPOCH: 】%s" % str(epoch + 1))
print('训练损失为:{:.4f}'.format(loss.item()), '训练精度为:{:.4f}'.format(acc_train))
print('【Finished Training!】')
# 模型验证
model.eval()
pred = model(data)
# 训练集(使用了掩码)
correct_count_train = pred.argmax(axis=1)[data.train_mask].eq(data.y[data.train_mask]).sum().item()
acc_train = correct_count_train / data.train_mask.sum().item()
loss_train = loss_function(pred[data.train_mask], data.y[data.train_mask]).item()
# 测试集
correct_count_test = pred.argmax(axis=1)[data.test_mask].eq(data.y[data.test_mask]).sum().item()
acc_test = correct_count_test / data.test_mask.sum().item()
loss_test = loss_function(pred[data.test_mask], data.y[data.test_mask]).item()
print('Train Accuracy: {:.4f}'.format(acc_train), 'Train Loss: {:.4f}'.format(loss_train))
print('Test Accuracy: {:.4f}'.format(acc_test), 'Test Loss: {:.4f}'.format(loss_test))
运行结果:
【EPOCH: 】1
训练损失为:1.9757 训练精度为:0.1643
【EPOCH: 】21
训练损失为:1.8855 训练精度为:0.2143
【EPOCH: 】41
训练损失为:1.8208 训练精度为:0.3000
【EPOCH: 】61
训练损失为:1.7172 训练精度为:0.3929
【EPOCH: 】81
训练损失为:1.6257 训练精度为:0.4357
【EPOCH: 】101
训练损失为:1.5981 训练精度为:0.4500
【EPOCH: 】121
训练损失为:1.4985 训练精度为:0.5786
【EPOCH: 】141
训练损失为:1.4246 训练精度为:0.5786
【EPOCH: 】161
训练损失为:1.3176 训练精度为:0.6786
【EPOCH: 】181
训练损失为:1.2401 训练精度为:0.6786
【Finished Training!】
Train Accuracy: 0.9500 Train Loss: 1.0584
Test Accuracy: 0.4270 Test Loss: 1.7728