神经网络分类任务
神经网络分类任务
1.Mnist分类任务
- 网络基本构建与训练方法,常用函数解析
- torch.nn.functional模块
- nn.Module模块
2.读取Mnist数据集
会自动进行下载.
from matplotlib import pyplot
import numpy as np
from pathlib import Path
import requests
import pickle
import gzip
import torch
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
PATH.mkdir(parents=True, exist_ok=True)
URL = "http://deeplearning.net/data/mnist/"
FILENAME = "mnist.pkl.gz"
if not (PATH / FILENAME).exists():
content = requests.get(URL + FILENAME).content
(PATH / FILENAME).open("wb").write(content)
with gzip.open((PATH / FILENAME).as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
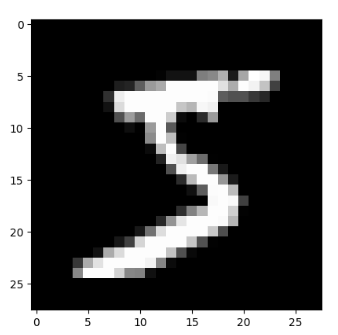
pyplot.imshow(x_train[0].reshape((28, 28)), cmap="gray")
pyplot.show()
print(x_train.shape)
输出结果:
(50000, 784)
注意数据需转换成tensor才能参与后续建模训练。
x_train, y_train, x_valid, y_valid = map(
torch.tensor, (x_train, y_train, x_valid, y_valid)
)
n, c = x_train.shape
x_train, x_train.shape, y_train.min(), y_train.max()
print(x_train, y_train)
print(x_train.shape)
print(y_train.min(), y_train.max())
输出结果:
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]) tensor([5, 0, 4, ..., 8, 4, 8])
torch.Size([50000, 784])
tensor(0) tensor(9)
3.torch.nn.functional
torch.nn.functional中有很多功能,后续会常用的。那什么时候使用nn.Module,什么时候使用nn.functional呢?一般情况下,如果模型有可学习的参数,最好用nn.Module,其他情况nn.functional相对更简单一些。
import torch.nn.functional as F
loss_func = F.cross_entropy
def model(xb):
return xb.mm(weights) + bias
bs = 64
xb = x_train[0:bs] # a mini-batch from x
yb = y_train[0:bs]
weights = torch.randn([784, 10], dtype = torch.float, requires_grad = True)
bs = 64
bias = torch.zeros(10, requires_grad=True)
print(loss_func(model(xb), yb))
输出结果:
tensor(11.8637, grad_fn=<NllLossBackward0>)
4.nn.Module
创建一个model来更简化代码。
- 必须继承nn.Module且在其构造函数中需调用nn.Module的构造函数。
- 无需写反向传播函数,nn.Module能够利用autograd自动实现反向传播。
- Module中的可学习参数可以通过named_parameters()或者parameters()返回迭代器。
from torch import nn
class Mnist_NN(nn.Module):
def __init__(self):
super().__init__()
self.hidden1 = nn.Linear(784, 128)
self.hidden2 = nn.Linear(128, 256)
self.out = nn.Linear(256, 10)
def forward(self, x):
x = F.relu(self.hidden1(x))
x = F.relu(self.hidden2(x))
x = self.out(x)
return x
net = Mnist_NN()
print(net)
for name, parameter in net.named_parameters():
print(name, parameter,parameter.size())
输出结果:
Mnist_NN(
(hidden1): Linear(in_features=784, out_features=128, bias=True)
(hidden2): Linear(in_features=128, out_features=256, bias=True)
(out): Linear(in_features=256, out_features=10, bias=True)
)
hidden1.weight Parameter containing:
tensor([[-0.0014, 0.0287, 0.0064, ..., -0.0067, -0.0291, -0.0009],
[ 0.0042, -0.0032, 0.0093, ..., -0.0142, 0.0017, 0.0029],
[-0.0195, -0.0022, 0.0303, ..., -0.0305, -0.0260, -0.0281],
...,
[-0.0083, -0.0214, 0.0063, ..., -0.0058, -0.0289, -0.0099],
[-0.0327, -0.0171, -0.0186, ..., 0.0112, -0.0272, -0.0325],
[ 0.0080, -0.0171, 0.0177, ..., 0.0196, -0.0302, -0.0209]],
requires_grad=True) torch.Size([128, 784])
hidden1.bias Parameter containing:
tensor([-2.5082e-02, 3.4613e-02, 2.8929e-02, -9.1332e-03, 3.1317e-02,
3.2871e-02, -1.8534e-02, -9.2351e-03, 1.3105e-02, 2.8164e-02,
2.2926e-02, 1.4692e-03, -1.6392e-02, -2.7027e-02, -2.3152e-03,
2.8548e-02, -3.7485e-03, 3.2557e-03, 3.4798e-02, 1.0538e-04,
3.5518e-02, -3.1315e-02, 1.9528e-02, 1.3368e-02, -6.2455e-03,
-1.8614e-03, -2.5163e-02, 1.2450e-02, -1.3421e-02, 1.7647e-02,
5.7835e-03, 1.9704e-03, 3.4963e-03, -1.2099e-02, -3.6703e-03,
2.4151e-02, 3.1279e-02, -1.0916e-02, -3.3869e-02, -2.3742e-02,
1.0694e-02, 8.2119e-03, 1.6860e-02, 1.4846e-03, -1.0588e-02,
-3.3914e-02, 4.9966e-03, -8.8861e-03, -3.4563e-02, -7.9519e-03,
1.7180e-02, 1.3122e-02, 2.0451e-02, -3.2566e-02, -2.4481e-02,
-2.2491e-02, -2.1122e-02, -1.0718e-02, 1.9556e-02, 1.6053e-02,
-1.7972e-02, -2.5955e-02, -4.3823e-03, -4.8794e-05, -1.0862e-02,
-3.0757e-02, -3.3692e-02, 3.6571e-03, -2.6568e-02, 1.0305e-02,
3.3073e-02, 1.6495e-02, 2.8315e-02, 1.7238e-02, -3.2841e-02,
2.6848e-02, 2.7803e-02, -2.0600e-02, 1.0160e-02, -6.3558e-03,
2.4960e-02, 3.1521e-02, -4.1828e-03, 2.8110e-02, 1.9540e-02,
-2.3993e-02, 1.8319e-02, 9.6065e-03, 3.0708e-02, -7.2993e-03,
-1.2475e-02, -1.2184e-02, -9.3824e-04, -3.4657e-02, 2.4282e-02,
2.9827e-02, -8.7789e-03, 1.6463e-02, 1.4160e-02, 1.9907e-03,
1.5485e-02, 5.3685e-03, 2.8379e-02, 1.9492e-02, -3.5959e-03,
-9.3017e-03, -2.2327e-02, 1.9342e-02, -2.9033e-03, -3.0324e-02,
2.6879e-02, 2.7407e-02, -2.7163e-02, 2.7238e-03, 3.5014e-02,
-7.3876e-03, -2.5034e-02, -3.2932e-02, 6.3722e-03, -2.8074e-02,
-4.0779e-03, 7.2072e-03, -2.8438e-02, 2.3013e-02, -3.4829e-02,
3.3665e-02, 2.2610e-02, 1.3138e-02], requires_grad=True) torch.Size([128])
hidden2.weight Parameter containing:
tensor([[-0.0830, 0.0739, -0.0288, ..., -0.0498, 0.0060, 0.0061],
[ 0.0302, -0.0582, -0.0272, ..., 0.0728, 0.0231, -0.0174],
[ 0.0661, 0.0846, -0.0226, ..., -0.0632, -0.0733, -0.0446],
...,
[ 0.0579, -0.0471, -0.0847, ..., -0.0218, 0.0637, -0.0073],
[ 0.0310, 0.0298, 0.0286, ..., 0.0175, 0.0307, 0.0559],
[-0.0179, 0.0157, 0.0527, ..., -0.0071, 0.0506, -0.0054]],
requires_grad=True) torch.Size([256, 128])
hidden2.bias Parameter containing:
tensor([ 0.0806, -0.0765, 0.0598, -0.0230, 0.0590, -0.0644, -0.0355, -0.0719,
0.0210, -0.0837, -0.0347, 0.0880, 0.0124, 0.0124, 0.0203, -0.0451,
0.0576, 0.0428, 0.0332, 0.0354, 0.0413, -0.0799, -0.0806, 0.0363,
-0.0144, -0.0037, -0.0464, -0.0627, 0.0548, -0.0028, 0.0078, -0.0543,
-0.0583, -0.0647, 0.0083, 0.0114, -0.0647, 0.0478, -0.0033, 0.0226,
0.0182, -0.0493, -0.0573, -0.0527, -0.0185, -0.0545, -0.0002, 0.0719,
0.0424, -0.0394, 0.0082, -0.0605, 0.0601, -0.0151, 0.0159, 0.0331,
-0.0226, 0.0089, 0.0363, 0.0065, -0.0517, -0.0190, -0.0276, -0.0134,
0.0396, 0.0570, 0.0192, -0.0545, -0.0022, 0.0238, 0.0594, -0.0548,
-0.0517, 0.0210, -0.0161, 0.0024, -0.0110, -0.0291, 0.0115, 0.0694,
-0.0753, -0.0688, 0.0519, -0.0381, 0.0540, 0.0405, -0.0008, 0.0850,
-0.0426, 0.0709, 0.0650, 0.0077, -0.0202, 0.0807, -0.0841, 0.0872,
0.0847, -0.0422, 0.0037, -0.0289, 0.0121, 0.0314, -0.0767, -0.0005,
-0.0126, -0.0426, 0.0745, 0.0028, -0.0839, 0.0139, 0.0513, 0.0355,
-0.0555, -0.0884, -0.0226, -0.0219, -0.0443, 0.0344, 0.0838, 0.0259,
0.0120, -0.0802, 0.0706, -0.0049, 0.0051, 0.0032, 0.0494, 0.0873,
0.0710, -0.0482, 0.0380, -0.0680, -0.0171, -0.0127, -0.0810, -0.0282,
0.0757, -0.0388, -0.0044, 0.0085, 0.0077, 0.0559, -0.0703, 0.0135,
-0.0598, 0.0087, 0.0809, 0.0728, -0.0003, 0.0672, -0.0329, -0.0536,
-0.0033, 0.0070, -0.0495, 0.0489, -0.0576, -0.0821, -0.0312, -0.0871,
0.0425, 0.0642, 0.0174, 0.0230, 0.0743, 0.0171, 0.0352, 0.0199,
-0.0519, -0.0268, -0.0076, -0.0795, -0.0550, 0.0436, -0.0339, 0.0761,
-0.0162, 0.0082, -0.0521, 0.0872, -0.0047, -0.0430, -0.0587, -0.0805,
0.0428, -0.0729, 0.0704, 0.0828, -0.0570, 0.0737, -0.0332, -0.0201,
-0.0170, 0.0472, -0.0321, -0.0501, -0.0683, -0.0636, 0.0858, -0.0635,
-0.0345, 0.0200, -0.0744, -0.0774, -0.0250, -0.0187, 0.0689, 0.0008,
-0.0499, 0.0658, 0.0456, 0.0169, -0.0563, -0.0696, 0.0236, 0.0230,
-0.0094, 0.0283, -0.0577, 0.0199, -0.0826, 0.0753, 0.0240, -0.0800,
0.0406, 0.0087, 0.0798, 0.0811, 0.0254, -0.0443, -0.0620, 0.0103,
-0.0796, 0.0172, 0.0731, -0.0679, 0.0048, 0.0078, 0.0830, -0.0364,
-0.0748, 0.0381, 0.0326, -0.0498, -0.0795, 0.0841, 0.0850, -0.0822,
-0.0646, 0.0378, 0.0831, -0.0073, -0.0105, 0.0134, 0.0840, -0.0501],
requires_grad=True) torch.Size([256])
out.weight Parameter containing:
tensor([[-0.0064, -0.0347, -0.0198, ..., -0.0109, 0.0033, -0.0012],
[-0.0465, 0.0574, 0.0524, ..., -0.0217, 0.0580, 0.0272],
[ 0.0238, -0.0463, -0.0057, ..., -0.0048, -0.0261, 0.0349],
...,
[ 0.0083, -0.0019, -0.0264, ..., 0.0210, 0.0292, -0.0611],
[ 0.0356, 0.0418, 0.0176, ..., -0.0086, 0.0081, -0.0302],
[ 0.0048, 0.0262, 0.0445, ..., 0.0353, -0.0432, 0.0412]],
requires_grad=True) torch.Size([10, 256])
out.bias Parameter containing:
tensor([ 0.0431, 0.0003, -0.0158, -0.0304, 0.0264, -0.0493, 0.0144, -0.0339,
0.0213, 0.0455], requires_grad=True) torch.Size([10])
5.使用TensorDataset和DataLoader
使用TensorDataset和DataLoader来简化。
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
from torch import optim
#############使用TensorDataset和DataLoader来简化##################
def get_data(train_ds, valid_ds, bs):
return (
DataLoader(train_ds, batch_size=bs, shuffle=True),
DataLoader(valid_ds, batch_size=bs * 2),
)
def get_model():
model = Mnist_NN()
return model, optim.SGD(model.parameters(), lr=0.001)
def loss_batch(model, loss_func, xb, yb, opt=None):
loss = loss_func(model(xb), yb)
if opt is not None:
loss.backward()
opt.step()
opt.zero_grad()
return loss.item(), len(xb)
def fit(steps, model, loss_func, opt, train_dl, valid_dl):
for step in range(steps):
model.train()
for xb, yb in train_dl:
loss_batch(model, loss_func, xb, yb, opt)
model.eval()
with torch.no_grad():
losses, nums = zip(
*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl]
)
val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums)
print('当前step:'+str(step), '验证集损失:'+str(val_loss))
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs * 2)
#三行代码搞定
train_dl, valid_dl = get_data(train_ds, valid_ds, bs)
model, opt = get_model()
fit(25, model, loss_func, opt, train_dl, valid_dl)
一般在训练模型时加上model.train(),这样会正常使用Batch Normalization和 Dropout。 测试的时候一般选择model.eval(),这样就不会使用Batch Normalization和 Dropout。
输出结果:
当前step:0 验证集损失:2.2793041885375978
当前step:1 验证集损失:2.245996584701538
当前step:2 验证集损失:2.192959008026123
当前step:3 验证集损失:2.106726198196411
当前step:4 验证集损失:1.9678182140350342
当前step:5 验证集损失:1.7617682785034179
当前step:6 验证集损失:1.5094052183151245
当前step:7 验证集损失:1.2630394382476806
当前step:8 验证集损失:1.0593502239227295
当前step:9 验证集损失:0.9065713457107544
当前step:10 验证集损失:0.7939958375930786
当前step:11 验证集损失:0.7104090020179749
当前step:12 验证集损失:0.6462713677406311
当前step:13 验证集损失:0.5958507433891297
当前step:14 验证集损失:0.5559158635139465
当前step:15 验证集损失:0.5234671715736389
当前step:16 验证集损失:0.49662490549087523
当前step:17 验证集损失:0.47411190090179445
当前step:18 验证集损失:0.45545100722312926
当前step:19 验证集损失:0.43968091354370115
当前step:20 验证集损失:0.4263882553100586
当前step:21 验证集损失:0.4145590144634247
当前step:22 验证集损失:0.4038331202030182
当前step:23 验证集损失:0.3949033221483231
当前step:24 验证集损失:0.3871174467325211
模型预测与评估。
# 在测试集上评估模型
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in valid_dl:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
print(f'Test Accuracy: {accuracy * 100:.2f}%')
输出结果:
Test Accuracy: 89.84%
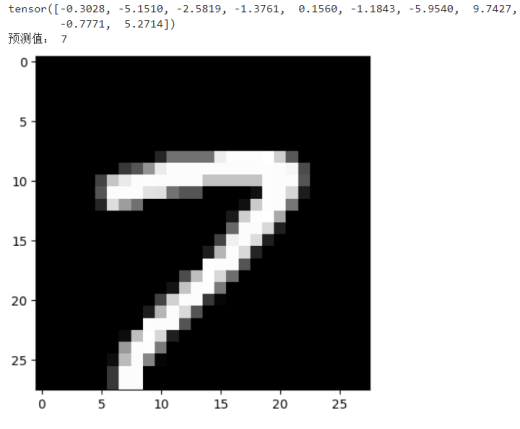
预测单个图片:
valid_img = x_train[123] #预测第123张图片
pyplot.imshow(valid_img.reshape((28, 28)), cmap="gray")
outputs = model(valid_img)
print(outputs.data)
predict = torch.max(outputs.data,0)
print("预测值:",predict.indices.item())