Pytorch线性回归之气温预测
Pytorch线性回归之气温预测
1.加载数据集
链接:https://pan.baidu.com/s/15FCX2C6jmptzj0xuAGm-dg 提取码:9527
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.optim as optim
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
features = pd.read_csv('temps.csv')
#看看数据长什么样子
features.head()
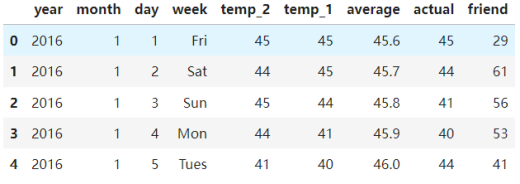
数据说明:
- year,moth,day,week分别表示的具体的时间
- temp_2:前天的最高温度值
- temp_1:昨天的最高温度值
- average:在历史中,每年这一天的平均最高温度值
- actual:这就是我们的标签值了,当天的真实最高温度
- friend:这一列可能是凑热闹的,你的朋友猜测的可能值,咱们不管它就好了。
2.查看维度和最高气温
print('数据维度:', features.shape)
features['actual'].max()
数据维度: (348, 9)
92
说明了一共有348条数据,9个特征
3.处理时间数据
# 处理时间数据
import datetime
# 分别得到年,月,日
years = features['year']
months = features['month']
days = features['day']
# datetime格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
dates[:5]
[datetime.datetime(2016, 1, 1, 0, 0),
datetime.datetime(2016, 1, 2, 0, 0),
datetime.datetime(2016, 1, 3, 0, 0),
datetime.datetime(2016, 1, 4, 0, 0),
datetime.datetime(2016, 1, 5, 0, 0)]
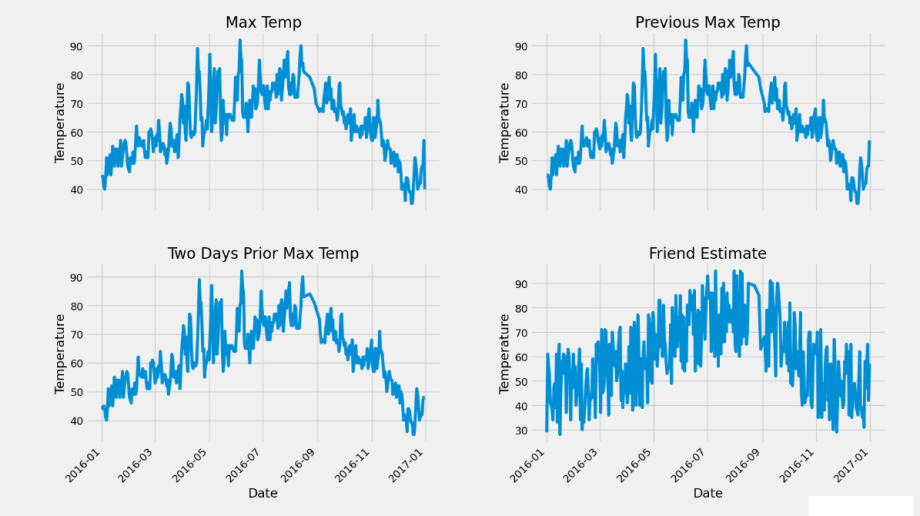
4.绘制特征图像
# 准备画图
# 指定默认风格
plt.style.use('fivethirtyeight')
# 设置布局
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize = (10,10))
# 注意: 设置坐标倾斜角度,防止累计在一起,造成重叠。
fig.autofmt_xdate(rotation = 45)
# 标签值
ax1.plot(dates, features['actual'])
ax1.set_xlabel(''); ax1.set_ylabel('Temperature'); ax1.set_title('Max Temp')
# 昨天
ax2.plot(dates, features['temp_1'])
ax2.set_xlabel(''); ax2.set_ylabel('Temperature'); ax2.set_title('Previous Max Temp')
# 前天
ax3.plot(dates, features['temp_2'])
ax3.set_xlabel('Date'); ax3.set_ylabel('Temperature'); ax3.set_title('Two Days Prior Max Temp')
# 我的逗逼朋友
ax4.plot(dates, features['friend'])
ax4.set_xlabel('Date'); ax4.set_ylabel('Temperature'); ax4.set_title('Friend Estimate')
plt.tight_layout(pad=2)
5.对于字符串进行编码
在原数据集当中,因为在week列中存在字符串,并不是整数类型,所以这个时候进行编码处理,这里使用pandas中的get_dummies进行编码。
# 独热编码
features = pd.get_dummies(features)
features.head(5)

可见对于字符串进行了编码,对于存在的写为“True”,不存在的写为“False”
6.标签操作
对于标签,在该数据集当中也就是actual,我们先将其存入labels中,后将这一列在数据集当中删除,因为之后训练不会用该列。
# 标签
labels = np.array(features['actual'])
# 在特征中去掉标签
features= features.drop('actual', axis = 1)
# 名字单独保存一下,以备后患
feature_list = list(features.columns)
# 转换成合适的格式
features = np.array(features)
features.shape
(348, 14)
7.归一化处理
在数据集当中,很明显数据集是大大小小的,有一些数值非常大,一些数值非常小,这个时候需要对其进行归一化,将所有数值按照权重、影响占比等缩放在(0,1)的范围当中。
from sklearn import preprocessing
input_features = preprocessing.StandardScaler().fit_transform(features)
input_features[0]
array([ 0. , -1.5678393 , -1.65682171, -1.48452388, -1.49443549,
-1.3470703 , -1.98891668, 2.44131112, -0.40482045, -0.40961596,
-0.40482045, -0.40482045, -0.41913682, -0.40482045])
8.转换格式
将上述inpu_data,labels转化为tensor格式,pytorch可以运用这个格式。
x = torch.tensor(input_features, dtype = float)
y = torch.tensor(labels, dtype = float)
9.构建网络模型
# 权重参数初始化
weights = torch.randn((14, 128), dtype = float, requires_grad = True)
biases = torch.randn(128, dtype = float, requires_grad = True)
weights2 = torch.randn((128, 1), dtype = float, requires_grad = True)
biases2 = torch.randn(1, dtype = float, requires_grad = True)
learning_rate = 0.001
losses = []
for i in range(1000):
# 计算隐层
hidden = x.mm(weights) + biases
# 加入激活函数
hidden = torch.relu(hidden)
# 预测结果
predictions = hidden.mm(weights2) + biases2
# 通计算损失
loss = torch.mean((predictions - y) ** 2)
losses.append(loss.data.numpy())
# 打印损失值
if i % 100 == 0:
print('loss:', loss)
#返向传播计算
loss.backward()
#更新参数
weights.data.add_(- learning_rate * weights.grad.data)
biases.data.add_(- learning_rate * biases.grad.data)
weights2.data.add_(- learning_rate * weights2.grad.data)
biases2.data.add_(- learning_rate * biases2.grad.data)
# 每次迭代都得记得清空
weights.grad.data.zero_()
biases.grad.data.zero_()
weights2.grad.data.zero_()
biases2.grad.data.zero_()
首先要进行权重的初始化,来为后面的学习打下基础,切记需要将每一次迭代后的梯度进行清零,否则将会一直累加,影响结果。
各个参数的设置是根据前面的特征数量来进行确定,我们要进行128个神经元的设计,需要凑一个14 * 128的矩阵给weights,同理,最后预测结果为一个结果,所以我们要将weights2设置为128 * 1。
10.预测结果
predictions.shape
predicted = predictions.detach().numpy()
plt.plot(dates, labels, label='Actual')
plt.plot(dates, predicted, label='Predicted')
plt.xlabel('Date')
plt.ylabel('Temperature')
plt.title('Actual vs Predicted')
plt.legend()
plt.show()
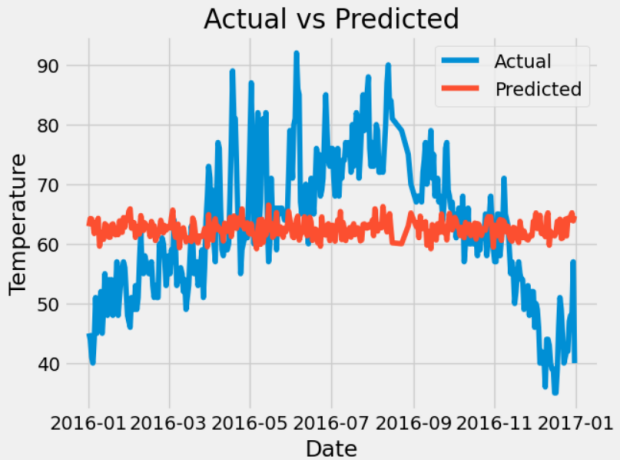
可见,使用该方法来进行预测时,其结果准确率不怎么高,下来我们将更新神经网络,将准确率提高!
11.更简单的构建网络模型
input_size = input_features.shape[1]
hidden_size = 128
output_size = 1
batch_size = 16
my_nn = torch.nn.Sequential(
torch.nn.Linear(input_size, hidden_size),
torch.nn.Sigmoid(),
torch.nn.Linear(hidden_size, output_size),
)
cost = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.Adam(my_nn.parameters(), lr = 0.001)
# 训练网络
losses = []
for i in range(1000):
batch_loss = []
# MINI-Batch方法来进行训练
for start in range(0, len(input_features), batch_size):
#end = start + batch_size if start + batch_size < len(input_features) else len(input_features)
if start + batch_size < len(input_features):
end = start + batch_size
else:
end = len(input_features)
xx = torch.tensor(input_features[start:end], dtype = torch.float, requires_grad = True)
yy = torch.tensor(labels[start:end], dtype = torch.float, requires_grad = True)
prediction = my_nn(xx)
loss = cost(prediction, yy)
optimizer.zero_grad()
loss.backward(retain_graph=True)
optimizer.step()
batch_loss.append(loss.data.numpy())
# 打印损失
if i % 100==0:
losses.append(np.mean(batch_loss))
print(i, np.mean(batch_loss))
x = torch.tensor(input_features, dtype = torch.float)
predict = my_nn(x).data.numpy()
# 转换日期格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
# 创建一个表格来存日期和其对应的标签数值
true_data = pd.DataFrame(data = {'date': dates, 'actual': labels})
# 同理,再创建一个来存日期和其对应的模型预测值
months = features[:, feature_list.index('month')]
days = features[:, feature_list.index('day')]
years = features[:, feature_list.index('year')]
test_dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
test_dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in test_dates]
predictions_data = pd.DataFrame(data = {'date': test_dates, 'prediction': predict.reshape(-1)})
# 真实值
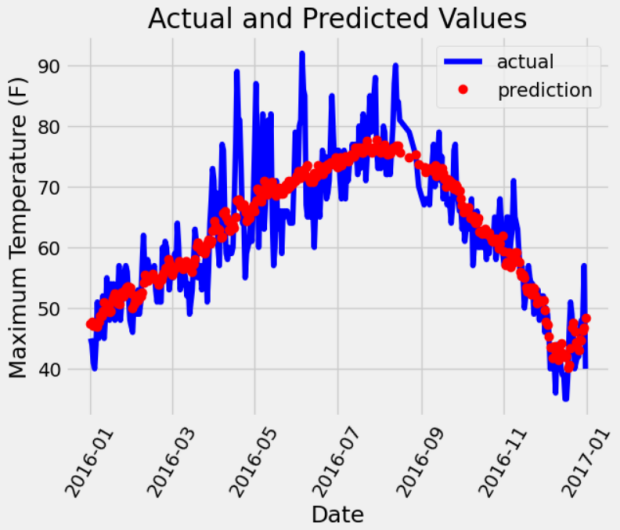
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')
# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = 'prediction')
plt.xticks(rotation =60)
plt.legend()
# 图名
plt.xlabel('Date')
plt.ylabel('Maximum Temperature (F)')
plt.title('Actual and Predicted Values')