本案例实现一个基于yolov8的安全帽佩戴的目标检测模型。
1.训练数据的准备
最简单的方法,就是在kaggle平台搜索相关的数据:搜索关键字Safety Helmet或者worker safety可以找到相应的训练数据。这里需要注意数据格式:例如,Safety Helmet 这份数据的格式是PASCAL VOC,而Site Safety这份数据的格式是YoloV8。前者需要将数据转换为Yolo格式,后者可以直接使用。
我们选择Site Safety这份数据,下载后可以直接使用。将下载的数据解压,在css-data文件夹中:
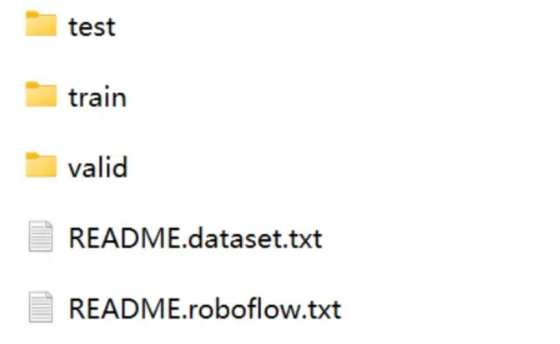
train保存了2605个训练数据,valid保存了114个验证数据,test保存了82个测试数据。打开train文件夹,其中image文件夹保存了图片数据,同一个数据的数据名和标记名是相同的,可以对应上。
2.训练数据的格式说明
我们随意打开一个数据图片和对应的标记数据:
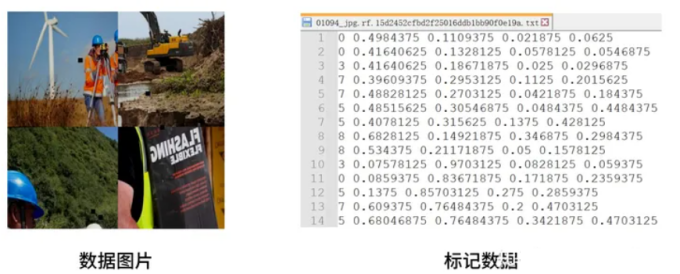
简单来说,每一行表示一个目标物体。在标记数据中包括了14行,因此对这个图片数据,会标记14个目标物体。
每一行的数据格式如下:
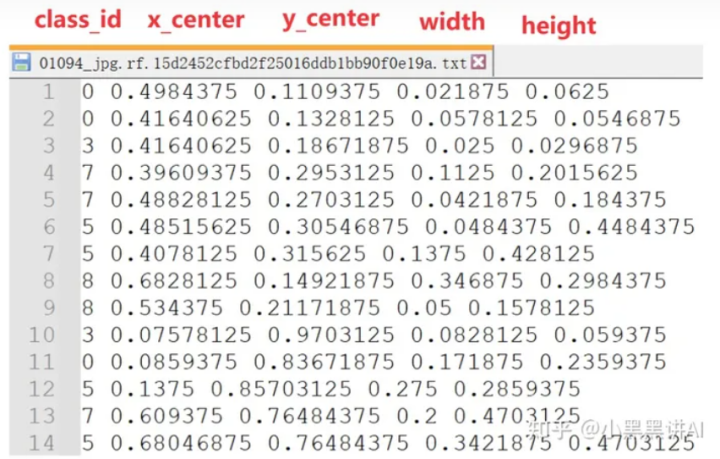
第1列是class_id,代表类别的编号。 第2列和第3列是x_center和y_center,代表物体边界框中心点的坐标。 第4列和第5列是width和height,代表物体边界框的宽度和高度。 这4个值的取值都在0到1之间。
我们以图片中的第1个目标物体来说明,也就是红框标记的蓝色安全帽:

它的标记数据是第1行,0、0.498、0.110等等。 这里的编号0,对应类别安全帽。 边界框中心点的坐标,是相对于图像宽度和高度的比例。 边界框的宽度和高度,同样是相对于图像的宽度和高度的比例。

例如,这个蓝色安全帽边界框中心点的x坐标,是0.498 * image_width。
中心点的y坐标,是0.110 * image_height。 物体边界框的宽度和高度,分别为 0.021 * image_width 和 0.062 * image_height: 另外,从这张图片可以看出,每个图片可以分为多张子图,每个子图也包括了多个目标物体。
因此,这份数据虽然只有2605张图片,但实际上可以有20000多个标记结果。
3.搭建环境和编写配置文件
使用conda create创建一个名为safety_env的新python环境:
conda create -n safety_env python==3.11.0
conda activate safety_env
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple ultralytics
创建一个yolov8工程,把css-data文件夹中数据集复制到dataset文件夹里面。
在dataset目录下创建yaml配置文件,文件取名为data.yaml:
# 用于训练的数据集
train: E:\ultralytics-main\dataset\train\images
# 用于测试的数据集
test: E:\ultralytics-main\dataset\test\images
# 用于验证的数据集
val: E:\ultralytics-main\dataset\valid\images
#number of classes
nc: 10
# class name
# 0: 安全帽
# 1: 口罩
# 2:无安全帽
# 3: 无口罩
# 4: 无安全背心
# 5: 人
# 6: 安全捶
# 7: 安全背心
# 8: 挖掘机
# 9: 车辆
names: ['Hardhat', 'Mask', 'NO-Hardhat', 'NO-Mask', 'NO-Safety Vest', 'Person', 'Safety Cone', 'Safety Vest', 'machinery', 'vehicle']
4.模型训练和测试
编写模型的训练代码yolo_train.py:
# 导入YOLO模块
from ultralytics import YOLO
if __name__ == '__main__':
# 使用YOLO的预训练模型,这个模型使用了coco数据集训练是通用的目标检测模型
model = YOLO('yolov8n.pt')
# 训练数据集
model.train(data='./dataset/data.yaml',epochs=100,batch=4,workers=4)
# 使用验证集验证效果
model.val()
也可以使用yolo命令训练。
#安全帽命令
yolo task=detect mode=train model=D:\ultralytics-main\ultralytics\cfg\models\v8\yolov8.yaml data=d:\ultralytics-main\dataset1\data.yaml epochs=100 imgsz=640 resume=True workers=4 batch=4
训练需要持续一段时间,每个epoch可能要训练3-5分钟,整体训练一个下午,基本就可以完成了。完成训练后,会在当前目录下的runs/detect/train6路径下,保存训练过程中的数据和模型文件。
其中weights文件夹中保存了模型文件,接下来我们使用best.pt进行测试。
编写测试代码yolo_test.py:
# 导入YOLO模块
from ultralytics import YOLO
if __name__ == '__main__':
# 使用YOLO的预训练模型,这个模型使用了coco数据集训练是通用的目标检测模型
model = YOLO('./runs/detect/train6/weights/best.pt')
# 使用训练好的模型预测
model.predict('./imgs/construction-safety.jpg', save=True)
model.predict('./imgs/indianworkers.mp4', save=True)
# classes = [0, 2],它代表只输出0和2这两个类别,也就是只识别安全帽是否佩戴。
# line_width = 3表示指定识别框的字体大小为 3。
model.predict('./imgs/worker001.jpg', save=True, classes=[0, 2], line_width=3)
model.predict('./imgs/worker002.jpg', save=True, classes=[0, 2], line_width=3)
model.predict('./imgs/worker003.jpg', save=True, classes=[0, 2], line_width=3)
识别结果会保存在当前目录下的runs/detect/predict中。打开结果文件夹,可以看到图片和视频的识别结果。


如果我们需要使用cpu方式进行模型预测。可以添加device=torch.device('cpu')参数。
# 使用cpu方式对训练好的模型预测
model.predict('./imgs/construction-safety.jpg', save=True, device=torch.device('cpu'))