pytorch反向传播
pytorch反向传播
1.什么是反向传播
反向传播是一种用于训练神经网络的算法,主要用来计算神经网络中每个参数的梯度。这些梯度告诉我们如何调整参数,以最小化损失函数(Loss Function),从而使模型更好地拟合数据。
实现过程如下:
- 反向传播从输出层开始,逐层向后计算每个参数对损失的导数(梯度)。
- 利用链式法则(链式求导法),将损失相对于每层参数的梯度依次计算出来。
2.反向传播相关概念
Autograd: - PyTorch的自动微分工具,能够自动计算张量的梯度。 - 通过调用tensor.backward(),PyTorch会自动计算所有涉及的梯度。
计算图: - 前向传播时,PyTorch会动态构建一个计算图,其中每个节点表示一个张量,每条边表示一个操作。 - 反向传播时,PyTorch沿着计算图的边缘,从输出层回溯到输入层,依次计算每个节点的梯度。
梯度累积和清零: - 每次调用loss.backward()时,梯度会累积在各个参数的.grad属性中。 - 在每次反向传播前,应调用optimizer.zero_grad()或model.zero_grad()清零梯度,以避免梯度累积影响后续计算。
3.反向传播计算过程
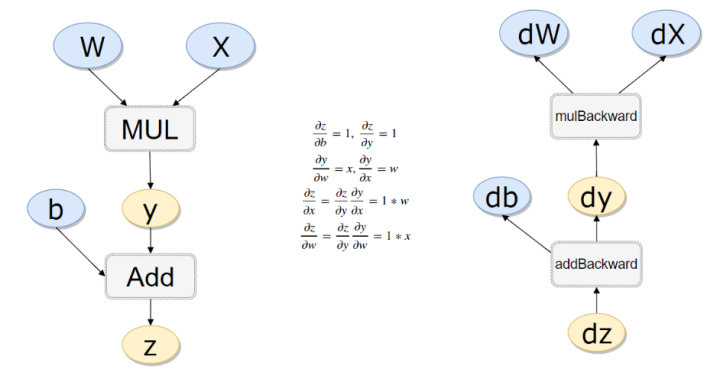
#计算流程
x = torch.rand(1)
b = torch.rand(1, requires_grad = True)
w = torch.rand(1, requires_grad = True)
print(x,y,z)
y = w * x
z = y + b
x.requires_grad, b.requires_grad, w.requires_grad, y.requires_grad ,z.requires_grad #注意y也是需要的
输出:
tensor([0.9209]) tensor(0.2198, grad_fn=<SumBackward0>) tensor([0.7040], grad_fn=<AddBackward0>)
(False, True, True, True, True)
x.is_leaf, w.is_leaf, b.is_leaf, y.is_leaf, z.is_leaf
输出:
(True, True, True, False, False)
z.backward(retain_graph=True)#如果不清空会累加起来
w.grad
b.grad
输出:
tensor([0.9209])
tensor([1.])
4.实例
做一个线性回归试试水
1).使用CPU模式训练
构造一组输入数据X和其对应的标签y。
import numpy as np
x_values = [i for i in range(11)]
x_train = np.array(x_values, dtype=np.float32)
x_train = x_train.reshape(-1, 1)
x_train.shape
print(x_train)
输出:
[[ 0.]
[ 1.]
[ 2.]
[ 3.]
[ 4.]
[ 5.]
[ 6.]
[ 7.]
[ 8.]
[ 9.]
[10.]]
y_values = [2*i + 1 for i in x_values]
y_train = np.array(y_values, dtype=np.float32)
y_train = y_train.reshape(-1, 1)
y_train.shape
print(y_train)
输出:
[[ 1.]
[ 3.]
[ 5.]
[ 7.]
[ 9.]
[11.]
[13.]
[15.]
[17.]
[19.]
[21.]]
创建线性回归模型。
import torch
import torch.nn as nn
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
input_dim = 1
output_dim = 1
model = LinearRegressionModel(input_dim, output_dim)
model
输出:
LinearRegressionModel(
(linear): Linear(in_features=1, out_features=1, bias=True)
)
指定好参数和损失函数。
epochs = 1000
learning_rate = 0.001
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
criterion = nn.MSELoss()
训练模型。
for epoch in range(epochs):
epoch += 1
# 注意转行成tensor
inputs = torch.from_numpy(x_train)
labels = torch.from_numpy(y_train)
# 梯度要清零每一次迭代
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 返向传播
loss.backward()
# 更新权重参数
optimizer.step()
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))
输出:
epoch 50, loss 0.36789652705192566
epoch 100, loss 0.17626219987869263
epoch 150, loss 0.1665581613779068
epoch 200, loss 0.1574861854314804
epoch 250, loss 0.1489083617925644
epoch 300, loss 0.1407976746559143
epoch 350, loss 0.1331288069486618
epoch 400, loss 0.1258777379989624
epoch 450, loss 0.11902154237031937
epoch 500, loss 0.11253876984119415
epoch 550, loss 0.10640916228294373
epoch 600, loss 0.10061350464820862
epoch 650, loss 0.09513318538665771
epoch 700, loss 0.08995172381401062
epoch 750, loss 0.08505230396986008
epoch 800, loss 0.0804198682308197
epoch 850, loss 0.07603952288627625
epoch 900, loss 0.07189801335334778
epoch 950, loss 0.06798188388347626
epoch 1000, loss 0.06427895277738571
测试模型预测结果。
predicted = model(torch.from_numpy(x_train).requires_grad_()).data.numpy()
predicted
输出:
array([[ 0.5259869],
[ 2.5942492],
[ 4.662512 ],
[ 6.730774 ],
[ 8.799036 ],
[10.867298 ],
[12.935561 ],
[15.003823 ],
[17.072086 ],
[19.140348 ],
[21.20861 ]], dtype=float32)
模型的保存与读取。
torch.save(model.state_dict(), 'model.pkl')
model.load_state_dict(torch.load('model.pkl'))
2).使用GPU进行训练
只需要把数据和模型传入到cuda里面就可以了。
import torch
import torch.nn as nn
import numpy as np
x_values = [i for i in range(11)]
x_train = np.array(x_values, dtype=np.float32)
x_train = x_train.reshape(-1, 1)
x_train.shape
print(x_train)
y_values = [2*i + 1 for i in x_values]
y_train = np.array(y_values, dtype=np.float32)
y_train = y_train.reshape(-1, 1)
y_train.shape
print(y_train)
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
input_dim = 1
output_dim = 1
model = LinearRegressionModel(input_dim, output_dim)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = nn.MSELoss()
learning_rate = 0.001
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs = 1000
for epoch in range(epochs):
epoch += 1
inputs = torch.from_numpy(x_train).to(device)
labels = torch.from_numpy(y_train).to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))
predicted = model(inputs.requires_grad_()).data.cpu().numpy()
predicted
输出结果同上,这里省略。