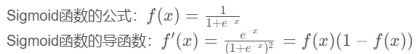在深度学习中,我们经常需要对函数求梯度(gradient)。PyTorch提供的autograd包能够根据输入和前向传播过程自动构建计算图,并执行反向传播。
1.自动计算梯度概念
如果将Tensor其属性.requires_grad设置为True,它将开始追踪(track)在其上的所有操作(这样就可以利用链式法则进行梯度传播了)。完成计算后,可以调用.backward()来完成所有梯度计算。此Tensor的梯度将累积到.grad属性中。
Function是另外一个很重要的类。Tensor和Function互相结合就可以构建一个记录有整个计算过程的有向无环图(DAG)。每个Tensor都有一个.grad_fn属性,该属性即创建该Tensor的Function, 就是说该Tensor是不是通过某些运算得到的,若是,则grad_fn返回一个与这些运算相关的对象,否则是None。
为了更好的计算梯度,torch提供了一个名为的tensor的数据结构,专门用于深度学习中计算梯度。但并不是每一个tensor都被赋予自动计算梯度的功能,需要同时满足以下两个条件:
- is_leaf:True;
- requires_grad:True.
import torch
# is_leaf: True, requires_grad: False
a = torch.tensor([1.0])
print(a.is_leaf,a.requires_grad)
# is_leaf: True, requires_grad: True
b = torch.tensor([2.0], requires_grad=True)
print(b.is_leaf,b.requires_grad)
# 以下语句会报错,因为torch只会给float类型的tensor计算梯度
b = torch.tensor([2], requires_grad=True) # int
运行结果:
True False
True True
...
RuntimeError: Only Tensors of floating point and complex dtype can require gradients
但是非用户创建的变量z只会继承requires_grad,不会继承is_leaf;
x = torch.tensor([1.0], requires_grad=True)
y = torch.tensor([2.0])
print(x.is_leaf,x.requires_grad)
print(y.is_leaf,y.requires_grad)
# is_leaf: False, requires_grad: True
# grad_fn: MulBackward (计算梯度的后向函数)
z = x * y
print(z.is_leaf,z.requires_grad)
z.backward() # 计算并储存梯度值
print(x.grad) # tensor([2.])
print(y.grad) # None
运行结果:
True True
True False
False True
tensor([2.])
None
根据上述代码,已知z = xy,可以分别计算这两个变量的梯度:
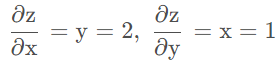
这里需要注意一点,torch反向传播过一次梯度后,计算图就会被释放。如果再次执行backward(),程序就会报错;如果需要多次反向传播梯度,可在第一次使用backward()时加上retain_graph=True。
x = torch.tensor([1.0], requires_grad=True)
y = torch.tensor([2.0])
z = x * y
z.backward()
z.backward() # 报错: RuntimeError: Trying to backward through the graph a second time, but the saved intermediate results have already been freed.
x = torch.tensor([1.0], requires_grad=True)
y = torch.tensor([2.0])
z = x * y
# retain_graph=True只能保持一次,如果要一直保持,则每次都需要添加
z.backward(retain_graph=True)
print(x.grad) # tensor([2.])
z.backward(retain_graph=True) # 多次反向传播后的梯度会累积
print(x.grad) # tensor([4.])
运行结果:
tensor([2.])
tensor([4.])
我们发现grad在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,我们可以使用.grad.data.zero_()清零。
x = torch.tensor([1.0], requires_grad=True)
y = torch.tensor([2.0])
z = x * y
# retain_graph=True只能保持一次,如果要一直保持,则每次都需要添加
z.backward(retain_graph=True)
print(x.grad) # tensor([2.])
x.grad.data.zero_()
z.backward(retain_graph=True) # 多次反向传播后的梯度会累积
print(x.grad) # tensor([4.])
输出:
tensor([2.])
tensor([2.])
需要注意的是,pytorch不允许tensor对tensor的求导呢,大概原因就是这会导致计算会很复杂。例如下面的代码:
x = torch.tensor([2., 3., 1.], requires_grad=True)
# y1 = x1 ** 2; y2 = x2 ** 2; y3 = x3 ** 2
y = x ** 2
y.backward()
# 报错(不允许tensor对tensor的求导)
# RuntimeError: grad can be implicitly created only for scalar outputs
必须在backward()时传入尺寸大小一样的参数。
x = torch.tensor([2., 3., 1.], requires_grad=True)
y = x ** 2
y.backward(torch.ones_like(x))
print(x.grad) # [4, 6, 2]
输出:
tensor([4., 6., 2.])
x = torch.tensor([2., 3., 1.], requires_grad=True)
y = x ** 2
y.backward(torch.tensor([1, 3, 2]))
print(x.grad) # [4, 18, 4]
输出:
tensor([ 4., 18., 4.])
下面通过一些例子来加深理解这些概念。
1).创建Tensor并设置requires_grad
import torch
x = torch.ones(2, 2, requires_grad=True)
print(x)
print(x.grad_fn)
运行结果:
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
None
再做一下运算操作:
y = x + 2
print(y)
print(y.grad_fn)
运行结果:
tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward0>)
<AddBackward0 object at 0x000001B16EDD27A0>
注意x是直接创建的,所以它没有grad_fn, 而y是通过一个加法操作创建的,所以它有一个为
print(x.is_leaf, y.is_leaf) # True False
再来点复杂度运算操作:
z = y * y * 3
out = z.mean()
print(z, out)
运行结果:
tensor([[27., 27.],
[27., 27.]], grad_fn=<MulBackward0>) tensor(27., grad_fn=<MeanBackward0>)
通过.requires_grad_()来用in-place的方式改变requires_grad属性:
a = torch.randn(2, 2) # 缺失情况下默认 requires_grad = False
a = ((a * 3) / (a - 1))
print(a.requires_grad) # False
a.requires_grad_(True)
print(a.requires_grad) # True
b = (a * a).sum()
print(b.grad_fn)
print(b)
运行结果:
False
True
<SumBackward0 object at 0x118f50cc0>
2.梯度计算
通过用.backward()来完成梯度的自动计算,并且Tensor的梯度将累积到.grad属性中。
执行反向传播backward()时要遵循以下原则:
- 如果是标量,可以直接backward或者等价backward(torch.tensor(1.))
- 如果是向量,那么参数的大小尺寸必须要保持一致。
接上面的案例,因为out是一个标量,所以调用backward()时不需要指定求导变量:
out.backward() # 等价于 out.backward(torch.tensor(1.))
print(x.grad)
输出结果:
tensor([[4.5000, 4.5000],
[4.5000, 4.5000]])
我们来看看out关于x的梯度,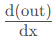
我们令out为 o , 因为:
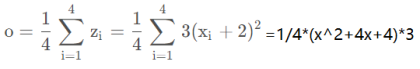
所以:
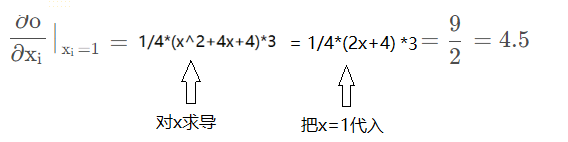
注意:grad在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零。
# 再来反向传播一次,注意grad是累加的
print(x)
out2 = x.sum()
out2.backward()
print(x.grad)
out3 = x.sum()
x.grad.data.zero_()
out3.backward()
print(x.grad)
输出:
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
tensor([[5.5000, 5.5000],
[5.5000, 5.5000]])
tensor([[1., 1.],
[1., 1.]])
因为计算梯度的最后一步,是要和这个backward的参数做点积的,所以必须要保证backward的参数必须要和out的大小一致。
来看一些实际例子。
x = torch.tensor([1.0, 2.0, 3.0, 4.0], requires_grad=True)
y = 2 * x
print(y)
z = y.view(2, 2) #变形为2*2的矩阵
print(z)
输出:
tensor([2., 4., 6., 8.], grad_fn=<MulBackward0>)
tensor([[2., 4.],
[6., 8.]], grad_fn=<ViewBackward0>)
现在 z 不是一个标量,所以在调用backward时需要传入一个和z同形的权重向量进行加权求和得到一个标量。
v = torch.tensor([[1.0, 0.1], [0.01, 0.001]], dtype=torch.float)
# 保证参数大小一致,至于传入什么参数值无所谓。
z.backward(v)
print(x.grad)
输出:
tensor([2.0000, 0.2000, 0.0200, 0.0020])
注意,x.grad是和x同形的张量。
3.梯度跟踪
如果不想要被继续追踪,可以调用.detach()将其从追踪记录中分离出来,这样就可以防止将来的计算被追踪,这样梯度就传不过去了。此外,还可以用with torch.no_grad()将不想被追踪的操作代码块包裹起来,这种方法在评估模型的时候很常用,因为在评估模型时,我们并不需要计算可训练参数(requires_grad=True)的梯度。
下面是中断梯度追踪的例子:
x = torch.tensor(1.0, requires_grad=True)
y1 = x ** 2
with torch.no_grad():
y2 = x ** 3
y3 = y1 + y2
print(x.requires_grad)
print(y1, y1.requires_grad) # True
print(y2, y2.requires_grad) # False
print(y3, y3.requires_grad) # True
运行结果:
tensor(1., grad_fn=<PowBackward0>)
True
tensor(1., grad_fn=<PowBackward0>) True
tensor(1.) False
tensor(2., grad_fn=<AddBackward0>) True
可以看到,上面的y2是没有grad_fn而且y2.requires_grad=False的,而y3是有grad_fn的。如果我们将y3对x求梯度的话会是多少呢?
y3.backward()
print(x.grad)
输出:
tensor(2.)
为什么是2呢?y3 = y1 + y2 = x^2 + x^3,当 x = 1 时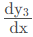 不应该是5吗?事实上,由于y2的定义是被torch.no_grad():包裹的,所以与y2有关的梯度是不会回传的,只有与y1有关的梯度才会回传,即x^2的梯度。
不应该是5吗?事实上,由于y2的定义是被torch.no_grad():包裹的,所以与y2有关的梯度是不会回传的,只有与y1有关的梯度才会回传,即x^2的梯度。
上面提到,y2.requires_grad=False,所以不能调用 y2.backward(),会报错:
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
此外,如果我们想要修改tensor的数值,但是又不希望被autograd记录(即不会影响反向传播),那么我么可以对tensor.data进行操作。
x = torch.ones(1,requires_grad=True)
print(x.data) # 还是一个tensor
print(x.data.requires_grad) # 但是已经是独立于计算图之外
y = 2 * x
x.data *= 100 # 只改变了值,不会记录在计算图,所以不会影响梯度传播
y.backward()
print(x) # 更改data的值也会影响tensor的值
print(x.grad)
输出:
tensor([1.])
False
tensor([100.], requires_grad=True)
tensor([2.])
4.tensor.data和tensor.detach()对比
相同点:
tensor.data和tensor.detach() 都是变量从图中分离,但而这都是“原位操作 inplace operation”。
不同点:
- .data 是一个属性,而.detach()是一个方法;
- .data 是不安全的,.detach()是安全的。
代码实例:
import torch
print("-----------------测试data-----------------------------")
a = torch.tensor([1.,2.,3.], requires_grad = True)
out = a.sigmoid()
c = out.data # 需要走注意的是,通过.data “分离”得到的的变量会和原来的变量共用同样的数据,而且新分离得到的张量是不可求导的,c发生了变化,原来的张量也会发生变化
c.zero_() # 改变c的值,原来的out也会改变
print(c.requires_grad)
print(c)
print(out.requires_grad)
print(out)
print("----------------------------------------------")
out=out.sum()
print(out)
out.backward()
print(a.grad) # 不会报错,但是结果却并不正确
print("-----------------测试detach()-----------------------------")
a = torch.tensor([1,2,3.], requires_grad = True)
out = a.sigmoid()
c = out.detach() # 需要走注意的是,通过.detach() “分离”得到的的变量会和原来的变量共用同样的数据,而且新分离得到的张量是不可求导的,c发生了变化,原来的张量也会发生变化
c.zero_() # 改变c的值,原来的out也会改变
print(c.requires_grad)
print(c)
print(out.requires_grad)
print(out)
print("----------------------------------------------")
out.sum().backward() # 对原来的out求导,
print(a.grad) # 此时会报错,错误结果参考下面,显示梯度计算所需要的张量已经被“原位操作inplace”所更改了。
附录:
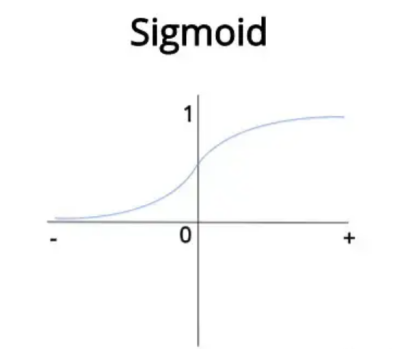
Sigmoid函数介绍。Sigmoid函数是一个逻辑函数,它可以将任何实数映射到0和1之间。值得注意的是,由于sigmoid函数的性质,当x为负值时,输出趋近于0;而当x为正值时,输出趋近于1。