1.常见随机变量分布
- 均匀分布
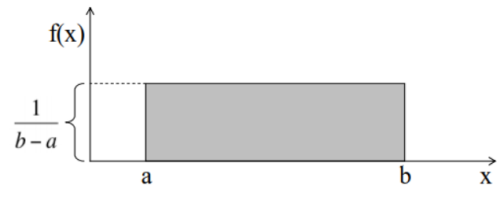
所有可能的结果都有相同的概率密度,如在一个范围内随机选择一个数。即a 和 b 这个区内取任意一个值的概率相等。
- 正态分布
为什么叫“正态分布”,也有地方叫“常态分布”,这两个名字都不太直观,但如果我们各取一字变为“正常分布”,就很白话了,所谓“正态分布”的本质含义就是Normal Distribution(正常分布)。正态分布基本上能描述所有常见的事物和现象:正常人群的身高、体重、考试成绩、家庭收入等等。
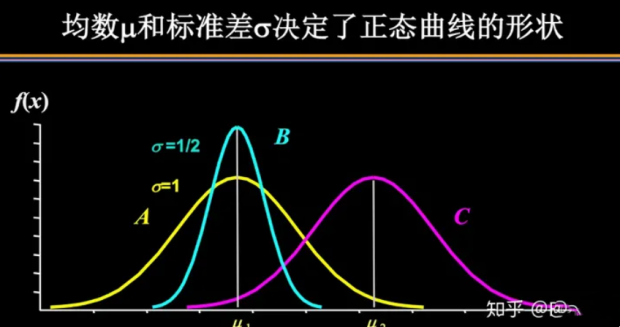
谈及正态分布,我们首先要想到它的两个参数:均数是多少和标准差是多少。标准差越小,意味着大多数变量值离均数的距离越短,因此大多数值都紧密地聚集在均数周围,图形上呈现瘦高型。相反,标准差越大,数据跨度就比较大,分散程度大,所覆盖的变量值就越多,图形呈现“矮胖型”。
三个百分数:68%,95%,99.7%的含义。即68%的数值是在离平均值1个标差范围之内,95%的数值是在离平均值2个标差范围之内,97%的数值是在离平均值3个标差范围之内。
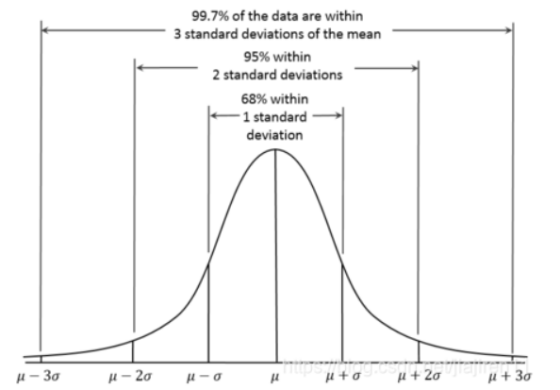
也被称为三西格马定律(three-sigma rule of thumb),是一个简单的推论,内容是“几乎所有”的值都在平均值正负三个标准差的范围内,也就是在实验上可以将99.7%的机率视为“几乎一定”。
代码示例:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 设定正态分布的参数
mu = 0 # 均值
sigma = 1 # 标准差
# 生成一组随机变量
data = np.random.normal(mu, sigma, 1000)
# 绘制直方图
plt.hist(data, bins=50, density=True, alpha=0.6, color='g')
# 生成正态分布的概率密度函数曲线
x = np.linspace(-5, 5, 1000)
pdf = norm.pdf(x, mu, sigma)
plt.plot(x, pdf, 'k', linewidth=2)
# 生成正态分布的累积分布函数曲线
cdf = norm.cdf(x, mu, sigma)
plt.plot(x, cdf, 'r--', linewidth=2)
# 显示图例
plt.legend(['PDF', 'CDF', 'Histogram'])
# 显示图形
plt.show()
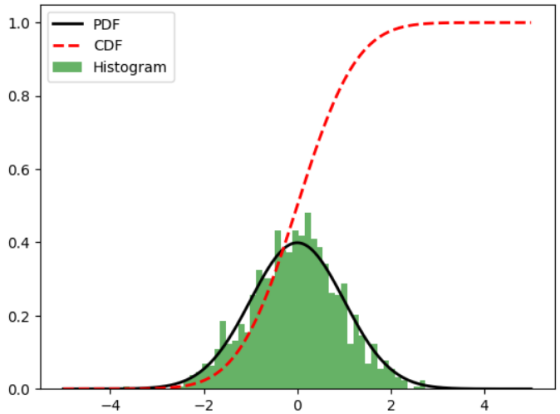
运行结果:
- 二项分布
二项分布是一种用来描述在一系列独立重复的伯努利试验中成功次数的概率分布。伯努利试验是一种只有两种结果的随机试验,比如抛硬币、投骰子,文章是否点赞等等。比如下图是一位作者的博文阅读数量与点赞数量的统计截图。

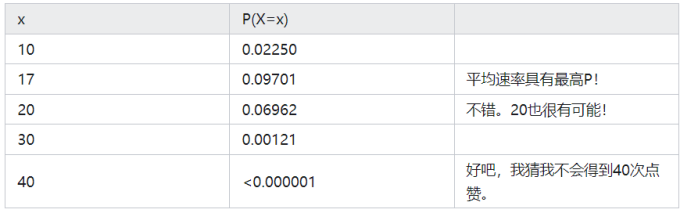
以上这些是1年的统计数据。共有59k人阅读了作者的文章。在59k人中,有888人点赞。
因此,每周阅读作者的文章的人数(n)为59k/52 = 1134。每周点赞的人数(x)为888/52 = 17。
每周阅读人数(n)= 59k/52 = 1134 每周点赞人数(x)= 888/52 = 17 成功概率(p):888/59k = 0.015 = 1.5%
不同x的二项概率,如下表所示:
- 泊松分布
泊松分布最常用于描述那些在一段时间或空间内以相对稀少的频率发生的事件,比如电话呼叫的次数、交通事故的发生次数、或者在一个固定区域内的自然灾害的数量等。泊松分布的出现是为了近似二项分布,因为二项分布的问题在于,它不能在单位时间内包含多于1个事件。泊松分布的思想就是让单位时间现在是无穷小的。我们不再需要担心在相同的单位时间内发生多个事件。
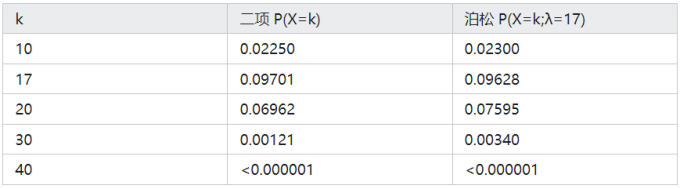
上面的案例,我们重新使用泊松分布计算之后,二项式与泊松之间的概率统计比较如下:
泊松分布需要注意的几点:
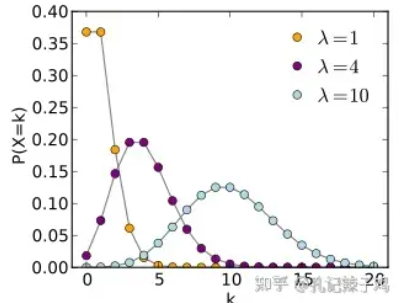
- 尽管泊松分布常用于对小概率事件进行建模,但速率 λ 可以是任意数字。它并不总是很小。
- 泊松分布是非对称的——它总是向右倾斜。因为它在左边受到零发生障碍的抑制(没有“负一次”点赞这样的事情),而在另一边是无限的。
- 随着λ变大,图形看起来越来越像正态分布。
我们还需要注意泊松模型的假设条件: 1. 每单位时间的事件平均速率是恒定的。 这意味着你的文章每小时访问人数可能不会遵循泊松分布,因为每小时的速率不是恒定的(白天速率较高,晚上速率较低)。对于消费者/生物学数据使用月度速率也仅仅是一个近似,因为该领域的季节性效应是无法忽略的。 2. 事件是独立的。 你的文章访问者的到达可能并不总是独立的。例如,有时候大量访问者会成群结队地来访,因为某个知名人士提到了你的文章,或者你的文章被首页推荐等。一个国家每年的地震次数也可能不遵循泊松分布,因为一次大地震可能会增加余震的概率。
2.随机向量
随机向量是一个概率论和统计学中常见的概念,它其实就是一组随机变量的集合。这些随机变量可以表示为一个向量,因此称为随机向量。比如,考虑一个抛硬币的实验,我们可以定义两个随机变量,一个表示第一次抛到正面的次数,另一个表示第一次抛到反面的次数。这两个随机变量构成了一个随机向量,可以用一个二维向量来表示。
总之,有些随机现象需要同时用多个随机变量来描述。例如 ,子弹着点的位置需要两个坐标才能确定,它是一个二维随机变量。类似地,需要n个随机变量来描述的随机现象,这n个随机变量就组成n维随机向量。
3.最大似然估计
最大似然估计(maximum likelihood estimation,MLE),也称极大似然估计,是用来估计一个概率模型的参数的一种方法。最大似然估计在统计学和机器学习中具有重要的价值,常用于根据观测数据推断最可能的模型参数值。
概率和似然是统计学中的两个重要概念,它们虽然在表达方式上有些相似,但在含义和应用上有明显的区别。可以考虑以下几点:
- 概率关注的是在已知参数情况下事件的发生概率,而似然关注的是在已知数据情况下参数的取值可能性。
- 概率常用于从模型到数据的推断,而似然常用于从数据到模型参数的推断。
- 在统计推断中,概率通常与贝叶斯统计方法相关联,而似然通常与频率派统计方法相关联。
总的来说,概率和似然是两个不同但相关的概念,它们在统计学中起着不同的作用,但都是描述随机现象的重要工具。
为了更好的理解最大似然估计的原理,我们来看一个例子。
假设有一个盒子里边有很多很多红色和蓝色的小球,而我们想估计抽到红色和蓝色小球的概率。
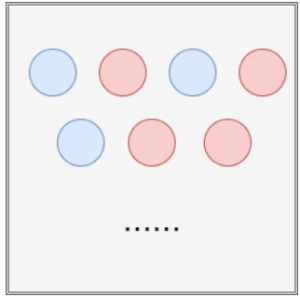
这里我们设抽到红色小球的概率为θ ,而我们抽到蓝色小球的概率即为1 − θ 。如下表格所示:
| 红色 | 蓝色 |
|---|---|
| θ | 1 − θ |
我们分别从盒子中抽出了五个球,得到了以下的结果:
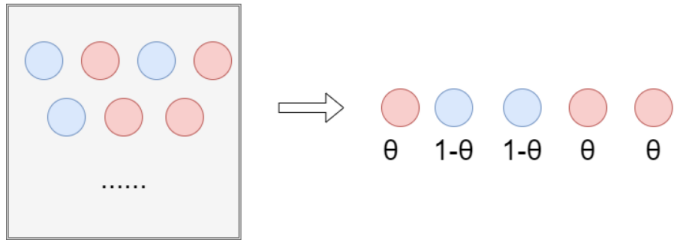
我们就能够得到这组样本的概率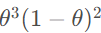 ,这就是似然函数即
,这就是似然函数即 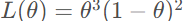
最大似然估计基于这样一个假设,即目前我们观测到的样本所呈现的状态已经是其最大可能出现的状态。
所以我们只需要看似然函数什么时候能达到最大,其取得最大值的时候的θ就是我们希望得到的θ。
因此,我们的问题就转换为了对求最大值的问题。
求最大似然估计的一般步骤如下:
- 写出似然函数;
- 对似然函数取对数;
- 求导数;
- 解似然方程
求解过程如下:

伯努利分布最大似然估计案例:
假设我们有一组来自伯努利分布的观测数据,目标是估计参数 p(成功的概率)。
步骤说明: - 生成模拟数据:设定真实参数 p=0.7,生成100个样本。 - 定义负对数似然函数:对数似然函数取负值以便使用优化器最小化。 - 数值优化求解:使用 scipy.optimize.minimize 找到使似然函数最大的p。 - 解析解验证:伯努利分布的MLE解析解是样本均值,用于验证数值解的正确性。
代码实现:
import numpy as np
from scipy.optimize import minimize
# 生成模拟数据
np.random.seed(42)
p_true = 0.7 # 真实概率
n_samples = 100
data = np.random.binomial(n=1, p=p_true, size=n_samples) # 生成伯努利样本(0或1)
print("----------样本数据----------")
print(data)
print("--------------------------")
# 定义负对数似然函数
def neg_log_likelihood(p, data):
# 避免log(0)导致数值问题,限制p的范围
epsilon = 1e-6
p = np.clip(p, epsilon, 1 - epsilon)
return -np.sum(data * np.log(p) + (1 - data) * np.log(1 - p))
# 使用优化器求解最大似然估计
result = minimize(neg_log_likelihood, x0=0.5, args=(data,), bounds=[(1e-6, 1 - 1e-6)])
# 解析解(样本均值)
p_mle_analytical = data.mean()
# 输出结果
print("数值解得到的MLE估计值:", round(result.x[0], 4))
print("解析解得到的MLE估计值:", round(p_mle_analytical, 4))
运行结果:
----------样本数据----------
[1 0 0 1 1 1 1 0 1 0 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 0 0 0 1
1 1 1 1 1 1 0 1 1 1 1 1 1 0 0 0 0 1 0 1 1 1 1 1 1 0 1 1 1 1 0 1 0 0 1 1 0
0 0 0 1 1 1 0 1 1 1 1 1 0 1 0 1 1 0 0 1 0 1 1 1 1 1]
--------------------------
数值解得到的MLE估计值: 0.7
解析解得到的MLE估计值: 0.7