1.方差
随机变量(Random variable):随着实验结果变化而变化的变量,称为随机变量。
数学期望(Mathematic expectation):它反映了随机变量的平均值。掌握每件事情发生的概率,让相应结果和概率相乘,再让这些所有结果都相加,就可以知道最后发生这件事情的期望。
方差(Variance):方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。方差等于各个数据与其算术平均数的离差平方和的平均数。
2.偏差与方差
方差和偏差都是统计学中常用的概念,但它们描述的是不同的概念:
方差(Variance): 1. 方差是描述数据分布或样本的离散程度或波动程度的统计量。 2. 在数学上,方差是各个数据点与其平均值之间的差的平方的平均值。方差越大,表示数据点之间的分散程度越大。 3. 方差是一个描述分散程度的量,通常用于衡量数据集内部的波动性。
偏差(Bias):
- 偏差是估计量(如样本平均值)的期望值与被估计参数的真实值之间的差异。
- 在统计学中,偏差表示估计值与真实值之间的差异,即估计值的平均偏离程度。
- 偏差用于衡量估计值的准确性,一个没有偏差的估计是一个无偏估计。
举个生活中的例子,用打靶来解释,bias描述的是瞄得准不准;varience描述的是手稳不稳。
光瞄得准没用,如果手抖,那么打出去的子弹会分散。这种情况也就是 low-bias、high-varience; 同理,光手稳也没用,如果瞄的不准,打出去的子弹就不在靶心。这种情况也就是 high-bias、low-varience。 放两张图(图片来自网络),一图胜千言。
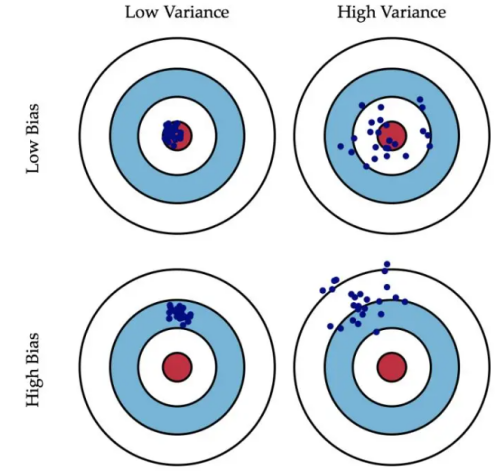
3.方差与标准差
我们知道方差是用来度量随机变量和其数学期望(即均值)之间的偏离程度。假设小明期末考试考了6门课,他的成绩分别是60,78,77,90,92,83。那么小明成绩的方差该怎么算呢?
我们需要先算出小明的平均成绩:
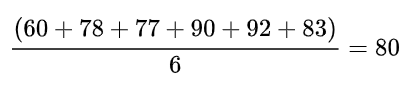
然后,分别用小明每一门课的成绩减去平均成绩,求出差的平方,再算出这些平方的平均值。即:
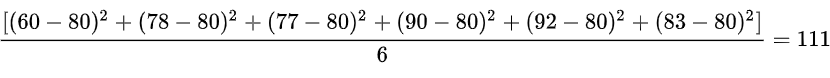
我们把这个结果就叫做方差。把它一般化, 假设有x_1、x_2...x_n一共n个数据,它们的均值是μ,那么方差就可以表示为:
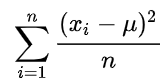
那么方差有什么意义呢?它所表示的是数据的波动程度,更具体的说,它表示的是数据与均值之间的离散程度。方差越大,表明数据越分散,离均值的平均距离远;方差越小,表明数据大多集中在均值周围。
标准差就是方差开方得到的结果,即:
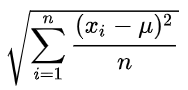
那这么做有什么意义呢?注意到,我们的方差是求了平方的,如果我们的数据是有单位的话,最后的结果将是单位的平方,对这个结果不是很好解释。比如上面小明成绩的方差是111,单位是“分”的平方。我们就会感到很奇怪。
将方差开方后,单位就变成了原来的单位,那么结果就很好解释了。可以得出,小明成绩的标准差约为10.5分。也就是说,小明的成绩与均值的差距平均在10.5分。
小结:
方差与标准差同样用来描述数据的离散程度,由于方差较标准差少了一次开方的运算,所以如果只是用来比较离散程度的情况下,我们可以直接使用方差。但由于方差是平方后的结果,所以在单位上与原来数据单位不一致,并不能直接进行运算。标准差直接衡量了数据的平均分散程度,它的值与原始数据的单位相同,更容易理解和比较。
代码示例:
小明期末考试成绩数组为:[87,56,78,90,76,88],计算考试成绩的方差和标准差。
import numpy as np # 导入NumPy库
import sympy as sp
from sympy import *
# 假设有一个考试分数的数值列表
scores = [87, 56, 78, 90, 76, 88]
# 将列表转换为NumPy数组
score_array = np.array(scores)
# 计算平均分
avg_score = np.mean(score_array)
# 计算方差
# 默认是总体方差(计算时除以样本数 N)
variance = np.var(score_array)
# 计算标准差
std_deviation = np.std(score_array)
print("---------numpy统计的结果----------")
print(f"平均分: {avg_score}")
print(f"方差: {variance}")
print(f"标准差: {std_deviation}")
运行结果:
---------numpy统计的结果----------
平均分: 79.16666666666667
方差: 134.13888888888889
标准差: 11.581834435394459
也可以自己实现求方差的算法。
import numpy as np # 导入NumPy库
import sympy as sp
from sympy import *
# 假设有一个考试分数的数值列表
scores = [87, 56, 78, 90, 76, 88]
#计算平均值的函数
def cal_avg(arr):
n = len(arr)
sum = 0
for i in range(n):
sum += arr[i]
avg= sum / n
return avg
#计算方差的函数
def cal_var(arr):
n = len(arr)
avg_temp = cal_avg(arr)
total = 0
for i in range(n):
total += (arr[i] - avg_temp) ** 2
total = total / n
return total
avg_score = cal_avg(scores)
variance_score = cal_var(scores)
print(f"平均分: {avg_score}")
print('样本方差:', variance_score)
print('样本标准差:', sqrt(variance_score))
4.协方差
协方差是用来衡量两个随机变量之间关系的统计量。通俗地说,它告诉我们两个变量是如何一起变化的。
想象你有两个变量,比如说体重和身高。如果这两个变量之间存在某种关系,比如身高增加时体重也会增加,那么它们的协方差可能会是正值。反之,如果身高增加时体重减少,那么协方差可能会是负值。如果它们之间没有关系,协方差则可能接近于零。
协方差可以用以下公式表示:
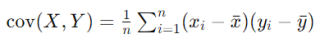
其中:

简单来说,协方差是通过计算每一对观测值与其均值之间的乘积,然后取平均得到的。如果乘积为正,表示 X 和 Y 呈正相关关系;如果乘积为负,表示呈负相关关系;如果接近于零,则表示两者之间无线性相关性。
代码示例:
import numpy as np
# 示例数据
X = np.array([1, 2, 3, 4, 5]) # 变量 X 的观测值
Y = np.array([5, 4, 3, 2, 1]) # 变量 Y 的观测值
# 计算协方差
covariance = np.cov(X, Y)[0, 1]
print("协方差:", covariance)
运行结果:
协方差: -2.5
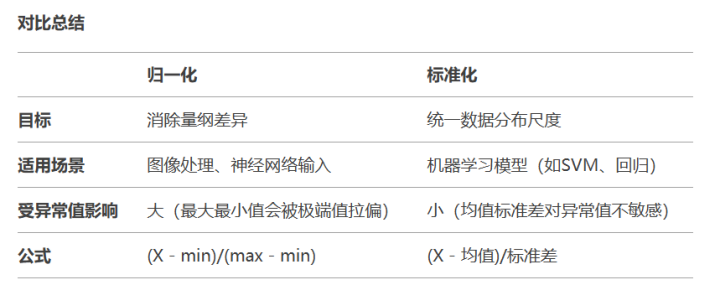
5.归一化与标准化
归一化与标准化是机器学习中数据预处理的重要手段。
1. 归一化(Normalization)
场景:假设你要比较三个人的考试成绩,但考试科目不同: 小明:数学90分(满分100) 小红:物理48分(满分50) 小刚:化学90分(满分200)
直接比较分数不公平,因为满分不同。这时候可以把所有分数都压缩到0~1之间: 小明:90/100 = 0.9 小红:48/50 = 0.96 小刚:90/200 = 0.45 这样就能直观看出:小红其实考得最好。归一化的本质:把数据按比例缩放到一个固定范围(比如0-1),消除量纲差异。
归一化计算公式:
Min-max normalization(最大最小归一化)
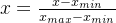
- 线性函数将原始数据线性化的方法转换到[0 1]的范围, 计算结果为归一化后的数据,X为原始数据
- 本归一化方法比较适用在数值比较集中的情况;
- 缺陷:如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量来替代max和min。
2. 标准化(Standardization)
场景:全班身高测量,大部分人身高在160cm-180cm之间,但有个篮球运动员身高220cm。直接计算平均身高会被这个"巨人"拉高,失去代表性。
标准化要做的是:
- 先计算全班平均身高(比如170cm)
- 再计算标准差(比如10cm)
- 把所有人的身高转换为:(原始身高 - 170)/10 160cm → (160-170)/10 = -1 180cm → (180-170)/10 = +1 220cm → (220-170)/10 = +5
这样数据就变成以0为中心,标准差为1的分布,极端值(+5)会被凸显出来。标准化的本质:把数据转换为均值为0、标准差为1的分布,保留原始数据分布形状。
标准化计算公式:
Zero-mean normalization(z-score标准化)
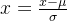 - 将原始数据集归一化为均值为0、方差1的数据集。
- 该种归一化方式要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕。
- 将原始数据集归一化为均值为0、方差1的数据集。
- 该种归一化方式要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕。
归一化代码实现:
from sklearn import preprocessing
import numpy as np
# 构造训练样本
X_train =[[28, 2], [27, 25], [29, 15], [37, 80], [25, 35]]
# 归一化
min_max_scaler = preprocessing.MinMaxScaler()
X_train_minmax = min_max_scaler.fit_transform(X_train)
np.set_printoptions(precision=2)
print(f'The scaled training data is \n {X_train_minmax}.')
# 构造测试样本
X_test = np.array([[29, 40]])
# 进行与训练样本一样的归一化操作
X_test_minmax = min_max_scaler.transform(X_test)
print(f'The scaled test data is \n {X_test_minmax}.')
注意:训练样本与测试样本的归一化操作需要保持一致。
标准化代码实现:
from sklearn import preprocessing
import numpy as np
# 构造训练样本
X_train = [[28, 2], [27, 25], [29, 15], [37, 80], [25, 35]]
# 标准化
standard_scaler = preprocessing.StandardScaler()
X_train_standard = standard_scaler.fit_transform(X_train)
np.set_printoptions(precision=2)
print(f'The scaled training data is \n {X_train_standard}.')
# 构造测试样本
X_test = np.array([[29, 40]])
# 进行与训练样本一样的标准化操作
X_test_standard = standard_scaler.transform(X_test)
print(f'The scaled test data is \n {X_test_standard}.')
# 打印均值和标准差
print(f'The mean is {standard_scaler.mean_}.')
print(f'The std is {standard_scaler.scale_}')