1.常见的矩阵形式
- 行矩阵(Row Matrix):只有一行的矩阵
例如: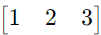 - 列矩阵(Column Matrix):只有一列的矩阵
例如:
- 列矩阵(Column Matrix):只有一列的矩阵
例如: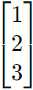 - 方阵(Column Matrix):行数和列数相等的矩阵
例如:
- 方阵(Column Matrix):行数和列数相等的矩阵
例如: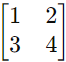 - 对角矩阵(Diagonal Matrix):除了对角线上的元素外,其它元素均为零的方阵。
例如:
- 对角矩阵(Diagonal Matrix):除了对角线上的元素外,其它元素均为零的方阵。
例如: - 单位矩阵(Identity Matrix):对角线上的元素均为1,其它元素为零的对角阵。
例如:
- 单位矩阵(Identity Matrix):对角线上的元素均为1,其它元素为零的对角阵。
例如: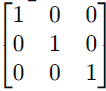 - 零矩阵(Zero Matrix):所有元素都是零的矩阵。
- 上三角阵(Upper Triangular Matrix):主对角线以下的元素全为零的方阵。
例如:
- 零矩阵(Zero Matrix):所有元素都是零的矩阵。
- 上三角阵(Upper Triangular Matrix):主对角线以下的元素全为零的方阵。
例如: - 下三角阵(Lower Triangular Matrix):主对角线以上的元素全为零的方阵。
例如:
- 下三角阵(Lower Triangular Matrix):主对角线以上的元素全为零的方阵。
例如: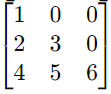
代码实现:
import numpy as np
#创建零矩阵
print('使用zeros函数创建的数组为:\n', np.zeros((2,3)))
#创建单位矩阵
print('使用eye函数创建的数组为:\n', np.eye(4))
#创建对角矩阵
print('使用diag函数创建的数组为:\n', np.diag([1,2,3,4]))
运行结果:
使用zeros函数创建的数组为:
[[0. 0. 0.]
[0. 0. 0.]]
使用eye函数创建的数组为:
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]
使用diag函数创建的数组为:
[[1 0 0 0]
[0 2 0 0]
[0 0 3 0]
[0 0 0 4]]
2.矩阵的秩
矩阵的秩是一个描述矩阵“维度”的概念,它告诉我们矩阵中的行或列的独立数量。通俗地说,秩可以理解为矩阵中非零行(或列)的最大个数。矩阵的秩在很多数学和工程问题中都有重要应用,例如在线性代数、信号处理、图像处理和优化问题中。
例如:
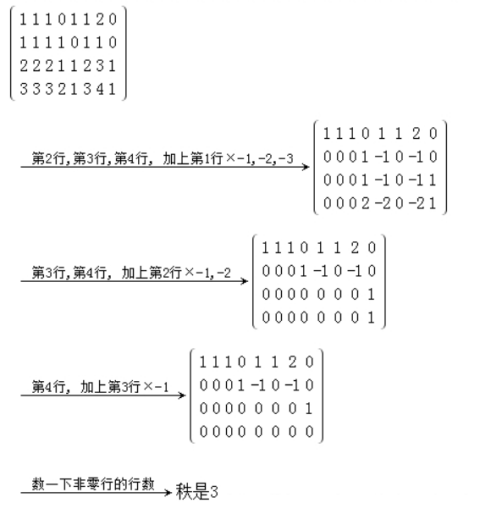
将矩阵做初等行变换后,非零行的个数叫行秩。 将其进行初等列变换后,非零列的个数叫列秩。
代码示例:
使用numpy实现求矩阵的秩:
import numpy as np
# 定义一个矩阵
matrix = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 计算矩阵的秩
rank = np.linalg.matrix_rank(matrix)
print("矩阵的秩为:", rank)
运行结果:
矩阵的秩为: 2
使用sympy实现求矩阵的置:
import sympy as sp
matrix_b = sp.Matrix([[1, 1, 1, 0, 1, 1, 2, 0],
[1, 1, 1, 1, 0, 1, 1, 0],
[2, 2, 2, 1, 1, 2, 3, 1],
[3, 3, 3, 2, 1, 3, 4, 1]])
rank = matrix_b.rank()
print("矩阵的秩为:", rank)
手工计算求解过程如下图所示:

3.线性相关与线性无关
线性相关和线性无关是描述向量或者集合中向量之间关系的概念。
- 线性相关:
如果一组向量中的某个向量可以用其他向量的线性组合(加减乘除)来表示,那么这组向量就是线性相关的。换句话说,至少有一个向量可以表示成其他向量的某种组合。举个例子,我们知道三原色是RGB,我们发现白色是由红、绿、蓝混合而成,那么我们就称:白色是红、绿、蓝的线性组合,换句话说由红、绿、蓝、白组成的向量组,就是线性相关的。
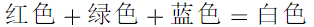

- 线性无关:
相反地,如果一组向量中的每个向量都不能表示为其他向量的线性组合,那么这组向量就是线性无关的。换句话说,没有一个向量可以通过其他向量的组合来表示。例如,三维空间中的三个不共线的向量就是线性无关的。
总的来说,线性相关意味着存在冗余信息,而线性无关意味着向量之间的信息是独立的。在许多数学和工程问题中,我们希望使用线性无关的向量,因为它们提供了更多的信息,更容易处理和理解。
4.相似矩阵
想象你有两幅画,它们可能是同一个主题的不同版本,但是可能有些微的变化,比如颜色略有不同、线条略微调整等。这就是相似矩阵的概念在数学上的类比。
在线性代数中,两个矩阵如果它们之间存在一个可逆矩阵(通常称为变换矩阵),通过这个变换矩阵对其中一个矩阵进行线性变换后能够得到另一个矩阵,那么这两个矩阵就被称为相似矩阵。
相似矩阵的数学定义如下:
设A,B都是n阶矩阵,若存在可逆矩阵P,使P^(-1)AP=B,则称B是A的相似矩阵, 并称矩阵A与B相似,记为A~B。
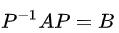
相似矩阵的几何意义在于它们描述了同一个线性变换在不同基下的不同形式。
代码示例:
import numpy as np
# 定义两个相似矩阵
matrix1 = np.array([[1, 2],
[3, 4]])
# 定义一个可逆矩阵作为变换矩阵
transform_matrix = np.array([[2, 0],
[0, 1]])
# 通过变换矩阵对一个矩阵进行线性变换,即公式使P^(-1)AP=B
matrix2 = np.dot(np.dot(np.linalg.inv(transform_matrix), matrix1), transform_matrix)
print("矩阵1:")
print(matrix1)
print("\n变换矩阵:")
print(transform_matrix)
print("\n矩阵2:")
print(matrix2)
运行结果:
矩阵1:
[[1 2]
[3 4]]
变换矩阵:
[[2 0]
[0 1]]
矩阵2:
[[1. 1.]
[6. 4.]]
5.特征值与特征向量
假设你在一片沙漠中行走,你的步伐可以看作是一个向量,它有一个特定的方向和长度。现在,假设有一个巨大的沙丘在你前面,你的每一步都是朝着沙丘的方向前进。在这种情况下,你的步伐的方向并没有改变,只是长度在不断地增加。这个方向就是特征向量,而增长的速度就是特征值。
- 特征向量:
特征向量是一个方向,表示一个线性变换后方向不改变的向量。在数学上,一个矩阵对一个向量进行变换,如果这个向量的方向不变,那么这个向量就是这个矩阵的特征向量。
- 特征值:
特征值是一个标量,它告诉我们特征向量在变换中拉伸或压缩的程度。如果特征值是正数,那么特征向量会被拉伸;如果是负数,那么特征向量会被压缩;如果是零,那么特征向量在变换后会落在同一条直线上,但长度可能会改变。
总之,特征向量和特征值描述了矩阵对空间的变换,它们可以帮助我们理解线性变换后的空间结构,以及找到那些在变换中保持不变的方向和程度。可以用一个生动的比喻来理解:矩阵就像一种“变换”,而特征向量是在这种变换下“方向不变”的向量,特征值则是这个向量被拉伸或压缩的比例。
特征值与特征向量的求解公式:Ax=λx ,其中x就是特征向量,λ是特征值。其几何意义是在A的作用下,向量方向不变或者反方向,拉伸的比例。
乘以矩阵A对某些向量仅仅有拉伸作用,如下图的向量v
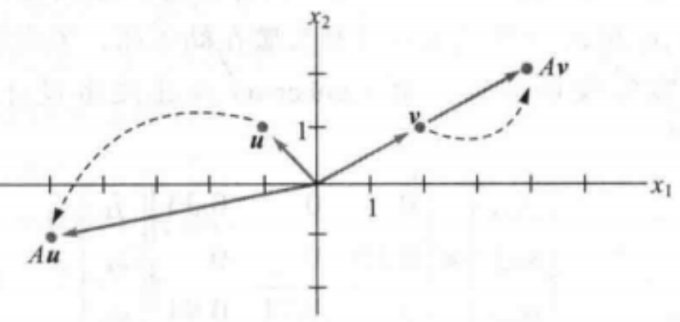
注意:只有方阵才能求特征值和特征向量。换句话说只能对n阶矩阵求特征值和特征向量。
代码示例:
import numpy as np
from sympy import Matrix, symbols
def find_eigenvalues_and_eigenvectors(matrix):
eigenvalues, eigenvectors = np.linalg.eig(matrix)
return eigenvalues, eigenvectors
def symbolic_eigenvalues_and_eigenvectors(matrix):
m = Matrix(matrix)
eigenvalues, eigenvectors = m.eigenvects()
return eigenvalues, eigenvectors
print("-------------------numpy求解特征值与特征向量----------------------")
matrix = np.array([[3, 1], [0, 2]])
eigenvalues, eigenvectors = find_eigenvalues_and_eigenvectors(matrix)
print("特征值:", eigenvalues)
print("特征向量:", eigenvectors)
print("-------------------sympy求解特征值与特征向量----------------------")
matrix = [[symbols('a'), symbols('b')], [symbols('c'), symbols('d')]]
eigenvalues, eigenvectors = symbolic_eigenvalues_and_eigenvectors(matrix)
print("特征值:", eigenvalues)
print("特征向量:", eigenvectors)
运行结果:
-------------------numpy求解特征值与特征向量----------------------
特征值: [3. 2.]
特征向量: [[ 1. -0.70710678]
[ 0. 0.70710678]]
-------------------sympy求解特征值与特征向量----------------------
特征值: (a/2 + d/2 - sqrt(a**2 - 2*a*d + 4*b*c + d**2)/2, 1, [Matrix([
[-d/c + (a/2 + d/2 - sqrt(a**2 - 2*a*d + 4*b*c + d**2)/2)/c],
[ 1]])])
特征向量: (a/2 + d/2 + sqrt(a**2 - 2*a*d + 4*b*c + d**2)/2, 1, [Matrix([
[-d/c + (a/2 + d/2 + sqrt(a**2 - 2*a*d + 4*b*c + d**2)/2)/c],
[ 1]])])
手工计算求解过程如下图所示:

另一种求解方法。

我们发现numpy计算的特征向量与手工计算的有偏差。

这是由于numpy.linalg.eig返回的特征向量是单位化的。简单说就是特征向量最大长度是1。
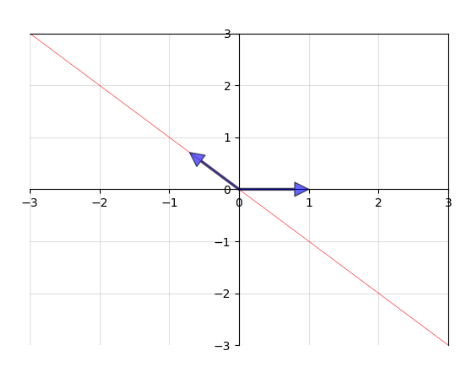
以下代码是上例更形象的表示,使用matplotlib画出特征向量。
import numpy as np
from scipy.linalg import eig
import matplotlib.pyplot as plt
A = [
[3, 1],
[0, 2]
]
evals, evacs = eig(A)
print(evals, "\n", evacs) # [ 3.+0.j -1.+0.j] [[ 0.70710678 -0.70710678] [ 0.70710678 0.70710678]]
evacs = evacs[:, 0], evacs[:, 1] # 转换成了tuple 类型的 array
print(evacs, type(evacs)) # (array([0.70710678, 0.70710678]), array([-0.70710678, 0.70710678])) <class 'tuple'>
fig, ax = plt.subplots() # 返回fig 整个图像 ax 坐标轴和所画的图 对象
for spine in ['left', 'bottom']: # 让坐标轴经过原点
ax.spines[spine].set_position('zero')
ax.grid(alpha=0.4) # 画出网格
xmin, xmax = -3, 3
ymin, ymax = -3, 3
ax.set(xlim=(xmin, xmax), ylim=(ymin, ymax)) # 设置坐标轴范围
for v in evacs: # 画出特征向量
ax.annotate("", xy=v, xytext=(0, 0), arrowprops=dict(facecolor='blue', shrink=0, alpha=0.6, width=1.5))
x = np.linspace(xmin, xmax, 2) # 画出特征空间
for v in evacs:
print(v, type(v))
a = v[1] / v[0] # 延特征向量方向的单位向量
print(a)
ax.plot(x, a * x, 'r-', linewidth=0.4)
plt.show()
运行效果:
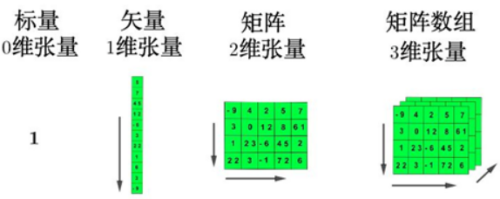
6.张量
张量(tensor)是多维数组,目的是把向量、矩阵推向更高的维度。
如下图所示:
7.克莱姆法则
7.1 线性方程组
方程中所有未知数次数都为一次时叫做线性方程,只要有一个未知数的次数大于一就叫非线性方程;当方程组中仅有线性方程时叫做线性方程组,而只要包含非线性方程的方程组都叫非线性方程组。
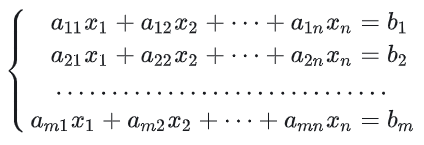
7.2 齐次线性方程组
常数项全部为零的线性方程组称为齐次线性方程组。 齐次线性方程组表达式 :Ax=0;非齐次方程组程度常数项不全为零: Ax=b。
7.3 线性方程组求解
克莱姆法则是线性代数中一个关于求解线性方程组的定理。但是克莱姆法则有两个局限性:
- 它只适用于未知数个数与方程数目相等的线性方程组。也就是适用于n*n的矩阵,即n个未知数、n个方程。
- 它要求方程组系数行列式的值不等于零。
对于齐次线性方程组:
- 若系数行列式不为0,则方程只有0解
- 若方程有非0解,则系数行列式一定为0
对于非齐次线性方程组:
- 若系数行列式不为0,则方程有唯一解。
- 若方程无解或有两个不同的解,则系数行列式一定为0。
实例:
有以下非齐次线性方程组。
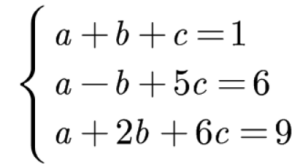
系数行列式为:
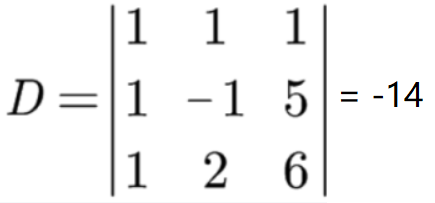
Di 表示把常数项代替后得到的n阶行列式。

那么其中一个未知量m的值为: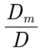 ,得到解为 a=-1 ;b=0.5; c=1.5 ,把 a ,b, c三个解代入原方程验证完全正确!
,得到解为 a=-1 ;b=0.5; c=1.5 ,把 a ,b, c三个解代入原方程验证完全正确!
使用克莱姆法则求解齐次线性方程组。
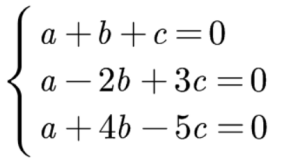
首先计算系数行列式的值:

python实现求解非齐次线性方程组。
import numpy as np
# 定义系数矩阵 A 和常数向量 b
A = np.array([[3, 2], [1, 4]])
b = np.array([5, 6])
# 求解方程组A
x = np.linalg.solve(A, b)
# 输出结果
print("方程组的解为:", x)
python求解齐次线性方程组。
import numpy as np
# 定义系数矩阵 A
A = np.array([[1, 2, 3], [2, 4, 6], [3, 6, 9]])
# 对 A 进行奇异值分解
U, s, Vh = np.linalg.svd(A)
# 找到零空间的基向量
# 奇异值分解的 Vh 矩阵的最后一列(对应最小奇异值)是零空间的基向量
null_space = Vh[-1]
# 输出结果
print("零空间的基向量为:", null_space)