yolov8的训练模式和任务类型参数
yolov8的训练模式和任务类型参数
1.训练模式和任务类型参数

这些参数主要用于定义模型的基本运行模式和任务类型。在实际应用中,应根据具体需求和场景选择合适的 task 和 mode。
注意:如果目的是在一个新的数据集上训练一个目标检测模型,那么 task 应设置为 detect,而 mode 应设置为 train。
实例:
from ultralytics import YOLO
model = YOLO("./yolov8n.pt")
result1 = model(mode='predict',task='detect',source="./imgs/dance_girl_001.jpg", save=True)
model = YOLO("./yolov8n-seg.pt")
result2 = model(mode='predict', task='segment',source="./imgs/dance_girl_001.jpg", save=True)
model = YOLO("./yolov8n-cls.pt")
result3 = model(mode='predict',task='classify',source="./imgs/dance_girl_001.jpg", save=True)
model = YOLO("./yolov8n-pose.pt")
result4 = model(mode='predict', task='pose',source="./imgs/dance_girl_001.jpg", save=True)
也可以使用yolo cli命令测试不同的任务。
#目标检查模型
yolo task=detect mode=predict model=yolov8n.pt source='./imgs/dance_girl_001.jpg'
#目标分割模型
yolo task=segment mode=predict model=yolov8n-seg.pt source = './imgs/dance_girl_001.jpg'
#目标分类模型
yolo task=classify mode=predict model=yolov8n-cls.pt source = './imgs/dance_girl_001.jpg'
#目标姿态模型
yolo task=pose mode=predict model=yolov8n-pose.pt source = './imgs/dance_girl_001.jpg'
2.模型预测参数
YOLOv8现在可以接受输入很多,如下表所示。包括图像、URL、PIL图像、OpenCV、NumPy数组、Torch张量、CSV文件、视频、目录、通配符、YouTube视频和视频流。表格✅指示了每个输入源是否可以在流模式下使用,并给出了每个输入源使用流模式的示例参数。
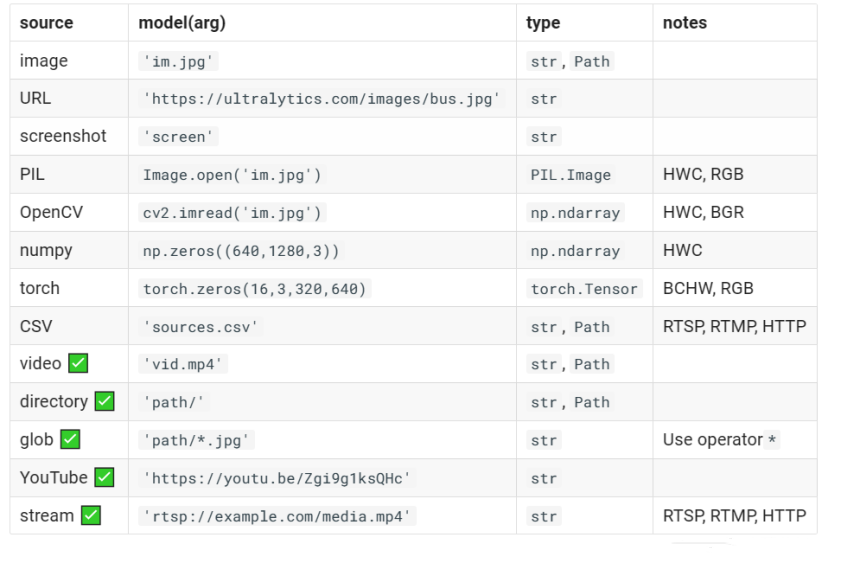
下面是每个参数的解释:
- source:输入源的目录,可以是图像或视频文件。
- conf:目标检测的对象置信度阈值。只有置信度高于此阈值的对象才会被检测出来。默认值为0.25。
- iou:非极大值抑制(NMS)的交并比(IoU)阈值。用于在重叠较大的候选框中选择最佳的检测结果。默认值为0.7。
- half:是否使用半精度(FP16)进行推理。半精度可以减少计算量,但可能会牺牲一些精度。默认值为False。
- device:模型运行的设备,可以是cuda设备(cuda device=0/1/2/3)或CPU(device=cpu)。
- show:是否显示检测结果。如果设置为True,则会在屏幕上显示检测到的对象。默认值为False。
- save:是否保存带有检测结果的图像。如果设置为True,则会将检测结果保存为图像文件。默认值为False。
- save_txt:是否将检测结果保存为文本文件(.txt)。默认值为False。
- save_conf:是否将检测结果与置信度分数一起保存。默认值为False。
- save_crop:是否保存裁剪后的带有检测结果的图像。默认值为False。
- hide_labels:是否隐藏标签。如果设置为True,则在显示检测结果时不显示对象标签。默认值为False。
- hide_conf:是否隐藏置信度分数。如果设置为True,则在显示检测结果时不显示置信度分数。默认值为False。
- max_det:每张图像的最大检测数。如果检测到的对象数超过此值,将保留置信度高低来保留。默认值为300。
- vid_stride:视频帧率步长。默认值为False,表示使用默认的帧率。
- line_width:边界框的线宽。如果设置为None,则根据图像大小进行自动缩放。默认值为None。
- visualize:是否可视化模型特征。默认值为False。
- augment:是否对预测源应用图像增强。默认值为False。
- agnostic_nms:是否使用类别无关的NMS。默认值为False。
- retina_masks:是否使用高分辨率的分割掩膜。默认值为False。
- classes:按类别过滤结果。可以指定单个类别(例如class=0)或多个类别(例如class=[0,2,3])。默认值为None,表示不进行类别过滤。
- boxes:在分割预测中显示边界框。默认值为True。
实例:
import ultralytics
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('./model/predict/yolov8n.pt')
print(model.names)
# 预测图片里的人
# model.predict('./images/xian_power001.jpg', classes=[0,5], conf=0.1, save=True)
# model.predict('./images/xian_power001.jpg', classes=[0, 5], conf=0.1, save=True, save_txt=True, device='0')
# model.predict('./images/girl001.jpg', classes=[0, 5], conf=0.1, save=True, save_txt=True, device='0',line_width=1)
#model.predict('./images/girl001.jpg', classes=[0, 5], conf=0.1, show=True, save=True, save_txt=True, device='0',line_width=1)
results = model(['./images/girl001.jpg','./images/bus001.png','https://img.simoniu.com/yolov8%E6%B5%8B%E8%AF%95%E5%9B%BE%E7%89%87001.png'])
print(len(results)) #2
icount=0
for result in results:
filename = f'dest{icount}.jpg'
result.show()
#把预测结果保存到指定的目录。
result.save(f'./output/{filename}')
icount+=1