yolov8训练自己的数据集。
1.准备原始数据集
这里我们准备一些训练图片,进行标注,作为我们的数据模型,我选择了两百张图片、可以使用 potplayer 连续截图功能将视频分割为图片,再从图片中剪切出不相似的人物。
为了方便训练,我们已经把这些原始图片进行目标信息的标注,并且已经转换为yolo的txt格式。
原始数据集目录结构图如下:

2.创建yolov8项目
把下载下来的ultralytics-main.zip源码解压缩后作为yolov8的项目目录。项目结构图如下所示:
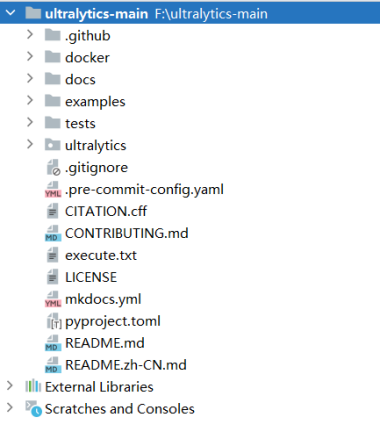
3.创建训练用的数据集目录
在项目根路径下创建 dataset 文件夹,然后在 dataset 目录下再创建(test,train,valid)三个子文件夹,分别在每个子文件夹下再创建名字为images和labels的子目录。在dataset目录下创建data.yaml配置文档。
再把原数据集的images里的图片放到(test,train,valid)三个子文件夹的images目录,labels_all里的标注文件放到(test,train,valid)三个子文件夹的labels目录。这里我们 train 目录里放入编号1-100的图片,test 目录放入编号101-180的图片,valid目录放入编号181-200的图片。 标注文件放入labels目录,训练图片放入 images内,并且文件名要一一对应起来。
dataset 目录结构如下图所示:
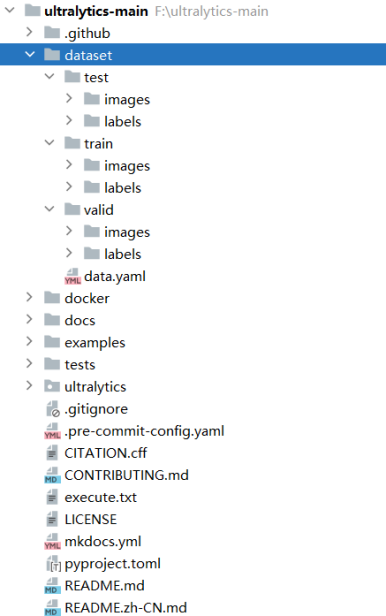
data.yaml 的内容如下:
# 用来分多少类,指定各个文件夹的位置
train: F:\ultralytics-main\dataset\train\images
val: F:\ultralytics-main\dataset\valid\images
test: F:\ultralytics-main\dataset\test\images
nc: 6
names:
0: e-bike
1: bike
2: human
3: 3bike
4: casque
5: bike-card
data.yaml 文件包含以下配置信息:
- 分别为三个文件夹的地址
- 标注的类型个数 nc
- 标注的类型的名称
根据自身需求修改,我项目路径就是F:\ultralytics-main,因此就不用修改了。
4.训练数据集
为了加快训练速度,我们提前下载好对应的yolov8模型文件,把模型文件复制到项目根目录下。如下图所示:
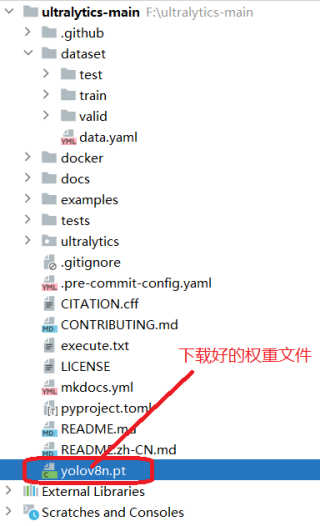
执行以下命令开始训练。
#训练自己的数据集
yolo task=detect mode=train model=F:\ultralytics-main\ultralytics\cfg\models\v8\yolov8.yaml data=F:\ultralytics-main\dataset\data.yaml epochs=30 imgsz=640 resume=True workers=4
也可以使用代码方式训练数据集。
# 导入YOLO模块
from ultralytics import YOLO
if __name__ == '__main__':
# 使用YOLO的预训练模型,这个模型使用了coco数据集训练是通用的目标检测模型
model = YOLO('yolov8n.pt')
# 训练数据集
model.train(data='./dataset/data.yaml',epochs=30, batch=4, workers=8)
# 使用验证集验证效果
model.val()
其中 epochs 为训练次数,如果是 10 代的中端 cpu 大概是四十秒一轮,3060ti 则为 2 秒一轮根据自身情况选择训练次数,建议不低于三十次。最后结果集会保存至 ultralytics-main\runs\detect 内,效果图为 val_batch0_pred.jpg
训练过程截图如下:
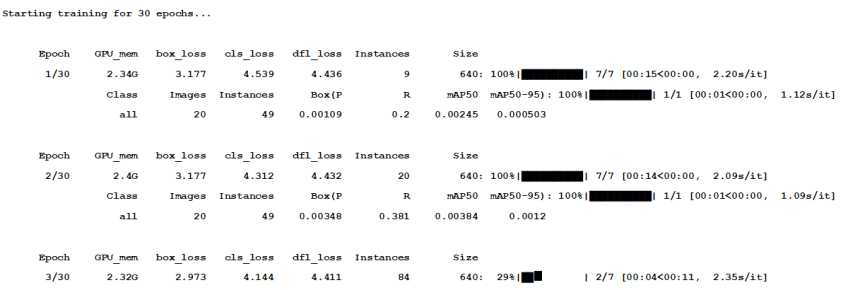
对编号181-200图片目标检测预测结果如下:

如果训练时报cuda内存溢出,报错如下:
RuntimeError: CUDA out of memory. Tried to allocate ... MiB
尝试以下解决方案:
import torch, gc
gc.collect()
torch.cuda.empty_cache()
或者添加batch 参数:
batch=4
5.YOLO模型中best.pt和last.pt的区别
- best.pt:保存的是训练过程中在验证集上表现最好的模型权重。在训练过程中,每个epoch结束后都会对验证集进行一次评估,并记录下表现最好的模型的权重。这个文件通常用于推理和部署阶段,因为它包含了在验证集上表现最好的模型的权重,可以获得最佳的性能。
- last.pt:保存的是最后一次训练迭代结束后的模型权重。这个文件通常用于继续训练模型,因为它包含了最后一次训练迭代结束时的模型权重,可以继续从上一次训练结束的地方继续训练模型。
小结:当需要在之前的训练基础上继续训练时,应该使用last.pt作为起点进行训练;当需要使用训练后的模型进行推理和部署时,应该使用best.pt。