DataFrame的常用操作。
1.查看DataFrame的常用属性
DataFrame的基础属性如下。 - values,可以获取元素; - index,可以获取索引; - column,可以获取列名; - dtypes,可以获取类型。
除了上述4个基本属性外,还可以通过size、ndim和shape属性获取DataFrame的元素个数、维度数和数据形状(行列数目)。
T属性能够实现DataFrame的转置(行列转换)。在某些特殊场景下,某些函数方法只能作用于列或行,此时即可试着用转置来解决这一问题。
2.查改增删DataFrame数据
数据库中最常使用的操作就是CRUD。DataFrame作为一种二维数据表结构,能够像数据库一样实现查改增删操作,如添加一行、删除一行、添加一列、删除一列、修改某一个值、某个区间的值替换等。
1).查看访问DataFrame中的数据
查看访问DataFrame中的数据主要有以下两种方式:
- DataFrame数据的基本查看方式。
- DataFrame的loc、iloc访问方式
DataFrame的单列数据为一个Series。以字典访问某一个key的值的方式使用对应的列名,即可实现单列数据的访问,以字典访问某一个key的值的方式使用对应的列名,即可实现单列数据的访问。
DataFrame提供的方法head()和tail()也可以得到前5行和后5行数据,head()方法和tail()方法使用的都是默认参数,所以访问的是前、后5行。在方法后的“()”中输入访问行数,即可实现目标行数的查看。
DataFrame的数据查看与访问基本方法虽然能够基本满足数据查看要求,但是终究还是不够灵活。pandas提供了loc()和iloc()两种更加灵活的方法来实现数据访问。
- loc()方法是针对DataFrame索引名称的切片方法,如果传入的不是索引名称,那么切片操作将无法执行。利用loc()方法,能够实现所有单层索引切片操作。
- iloc()方法接收的必须是行索引和列索引的位置。
loc()方法和iloc()方法基本使用格式如下:
DataFrame.loc[行索引名称或条件, 列索引名称]
DataFrame.iloc[行索引位置, 列索引位置]
2).更改DataFrame中的数据
- 更改DataFrame中的数据的原理是将这部分数据提取出来,重新赋值为新的数据。
- 需要注意的是,数据更改是直接对DataFrame原数据更改,操作无法撤销。
- 如果不希望直接对原数据做出更改,那么需要对更改条件进行确认或对数据进行备份。
3).DataFrame增添数据
为DataFrame添加一列的方法非常简单,只需要新建一个列索引,并对该索引下的数据进行赋值操作即可。如果新增的一列值是相同的,那么可以直接为其赋值一个常量。
4).删除某列或某行数据
删除某列或某行数据需要用到pandas提供的方法drop()。 drop()方法的基本使用格式如下:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
3.描述分析DataFrame数据
描述性统计是用于概括、表述事物整体状况,以及事物间关联、类属关系的统计方法。通过几个统计值可简捷地表示一组数据的集中趋势和离散程度等。
1).数值型特征的描述性统计
数值型特征的描述性统计主要包括了计算数值型数据的最小值、均值、中位数、最大值、四分位数、极差、标准差、方差、协方差和变异系数等。
在NumPy库中已经提到了为数不少的统计函数,为方便读者查看,将NumPy库简写为np,部分统计函数如下表。
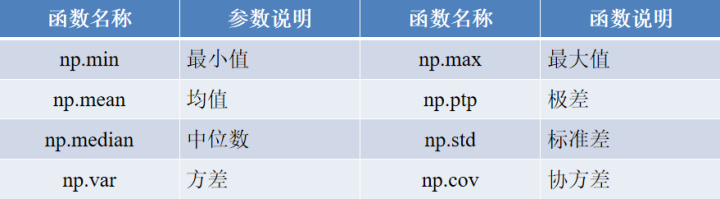
作为专门为数据分析而生的Python库,pandas还提供了一个describe()方法,能够一次性得出数据框中所有数值型特征如下。
- 非空值数目。
- 均值。
- 四分位数。
- 标准差。
- 最大值和最小值。
2).类别型特征的描述性统计
描述类别型特征的分布状况,可以使用频数统计。在pandas库中实现频数统计的方法为value_counts()。
除了使用value_counts()方法分析频率分布外,pandas提供了category类,可以使用astype()方法将目标特征的数据类型转换为category类型。
describe()方法除了支持传统数值型数据以外,还能够支持对category类型的数据进行描述性统计,4个统计量如下:
- count:计数,这一组数据中包含数据的个数
- unique:表示有多少种不同的值
- top:数据中出现次数最高的值
- freq:出现次数最高的那个值(top)的出现频率