pytorch常用工具集
1.visdom 简介
visdom 是Facebook 为PyTorch 打造的一款可视化工具,在2017年开源,代码地址: https://github.com/fossasia/visdom,
国内也可以使用其代码镜像: https://gitee.com/mirrors/Visdom?_from=gitee_search
1).安装
pip install visdom
2).启动
'''方式1'''
python -m visdom.server
'''方式2'''
直接visdom
打开浏览器输入:http://localhost:8097
- env被保存在$USER_HOME/.visdom/ 这里,里面保存的是.json文件,如果json被删除,相应保存的env也就没了。
- 浏览器界面中environment右边可以选择env,默认是main,点击哪个env就会显示对应的绘制。
- clear旁边的可以保存env,再右边哪个manage只能保存view,为了将数据保存到本地,只能使用clear旁边将env保存下来。
3).Visdom可视化函数及其参数一览
#visdom基本可视化函数
vis.image : #图片
vis.line: #曲线
vis.images : #图片列表
vis.text : #抽象HTML 输出文字
vis.properties : #属性网格
vis.audio : #音频
vis.video : #视频
vis.svg : #SVG对象
vis.matplot : #matplotlib图
vis.save : #序列化状态服务端
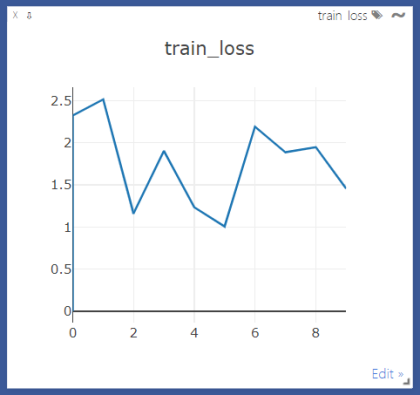
实例:监听train_loss的变化
Visdom可视化神经网络的训练过程大致分为3步:
- 实例化一个窗口
- 初始化窗口的信息
- 更新监听的信息
from visdom import Visdom
import numpy as np
import time
# 实例化一个窗口
wind = Visdom()
# 初始化窗口信息
wind.line([0.], # Y的第一个点的坐标
[0.], # X的第一个点的坐标
win='train_loss', # 窗口的名称
opts=dict(title='train_loss') # 图像的标例
)
# 更新数据
for step in range(10):
# 随机获取loss,这里只是模拟实现
loss = np.random.randn() * 0.5 + 2
wind.line([loss], [step], win='train_loss', update='append')
time.sleep(0.5)
运行结果:此时打开visdom的主界面,会发现窗口train_loss已经显示出来了。
2.tensorboardX
Tensorboard 是 TensorFlow 的一个附加工具,可以记录训练过程的数字、图像等内容,以方便研究人员观察神经网络训练过程。但是对于 PyTorch 等其他神经网络训练框架并没有功能像 Tensorboard 一样全面的类似工具,一些已有的工具功能有限或使用起来比较困难 (tensorboard_logger, visdom等) 。TensorboardX 这个工具使得 TensorFlow 外的其他神经网络框架也可以使用到 Tensorboard 的便捷功能。安装了tensorflow会自动安装tensorboard。
3.torchvision
torchvision独立于pytorch,专门用来处理图像,通常用于计算机视觉领域。
torchvision包由流行的数据集、模型体系结构和通用的计算机视觉图像转换组成。简单地说就是常用数据集+常见模型+常见图像增强方法。
Torchvision 数据集列表: - MNIST //手写数字识别 - CIFAR-10 //包含 10 个类别的 60,000 张 32x32 彩色图像,每个类别有 6,000 张图像。 - CIFAR-100 //CIFAR-100 数据集有 60,000 张(50,000 张训练图像和 10,000 张测试图像)32x32 彩色图像,分为 100 个类别,每个类别有 600 张图像。 - ImageNet //包含大约 120 万张训练图像、50,000 张验证图像和 100,000 张测试图像。数据集中的每张图像都标有 1,000 个类别之一,例如“猫”、“狗”、“汽车”、“飞机”等。 - COCO //包含 328,000 张日常物体和人类的高质量视觉图像,通常用作比较实时物体检测算法性能的标准。 - Fashion-MNIST //由 70,000 张灰度图像(训练集 60,000 张和测试集 10,000 张)组成。代表 10 种不同类别的服装,包括 T 恤/上衣、裤子、套头衫、连衣裙、外套、凉鞋、衬衫、运动鞋、包和踝靴。 - SVHN //从 Google 的街景图像派生的图像数据集,它由从街道图像中截取的门牌号裁剪图像组成。它以包含所有门牌号及其边界框的完整格式和仅包含门牌号的裁剪格式提供。完整格式通常用于对象检测任务,而裁剪格式通常用于分类任务。 - STL-10 //是一个图像识别数据集,由 10 个类组成,总共约有 6,000+ 张图像。这10 个类别是:飞机、鸟、车、猫、鹿、狗、马、猴、船、卡车 - CelebA //一个流行的大规模人脸属性数据集,包含超过 200,000 张名人图像。CelebA 中的图像包含 40 种面部属性,例如年龄、头发颜色、面部表情和性别。 - Pascal VOC //由 20 个不同对象类别的图像组成,包括动物、车辆和常见的家居用品。这些图像中的每一个都用图像中对象的位置和分类进行了注释。注释包括边界框和像素级分割掩码。 - Places365 //是一个大规模的场景识别数据集,拥有超过 180 万张图像,涵盖 365 个场景类别。
重点介绍torchvision最常用的三个包:
- models:提供了很多常用的训练好的网络模型,我们可以直接加载并使用,如Alexnet、ResNet等。
- datasets:提供了(1)一些常用的图片数据集,如MNIST、COCO等(2)加载自己的数据集的常用方法,目前只有DatasetFolder、ImageFolder、VisionDataset三个方法。
- transforms:提供了一些常用的图像转换处理操作,主要针对Tensor或PIL Image进行操作。
下载数据集实例:
import torchvision
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)