通用函数
通用函数
通用函数
1.一元函数
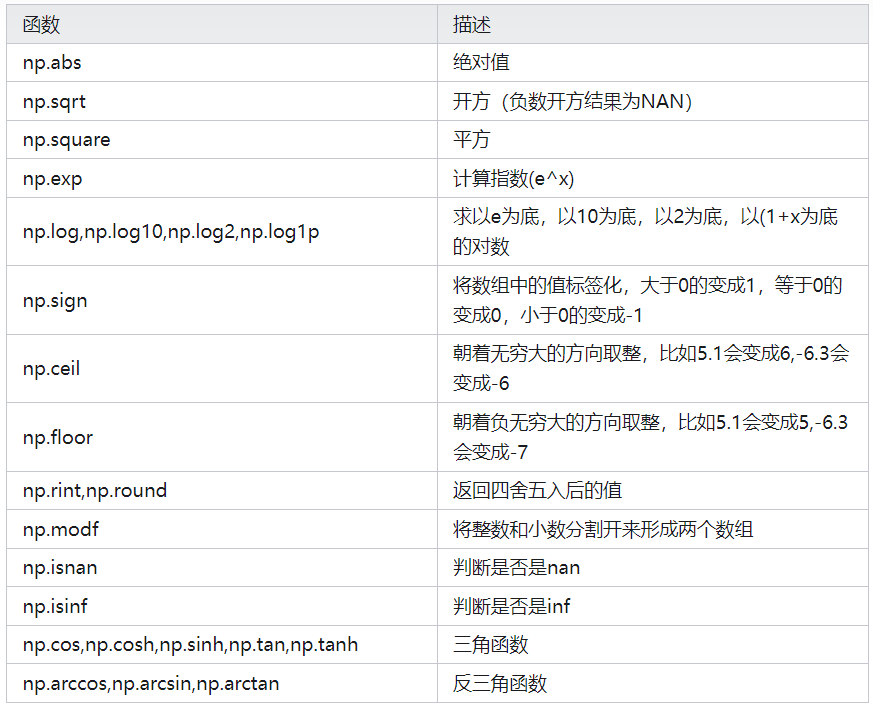
2.二元函数
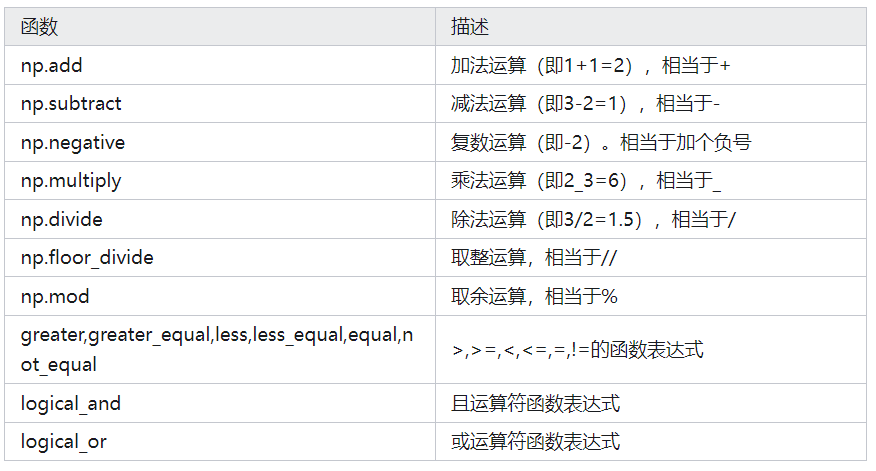
3.聚合函数
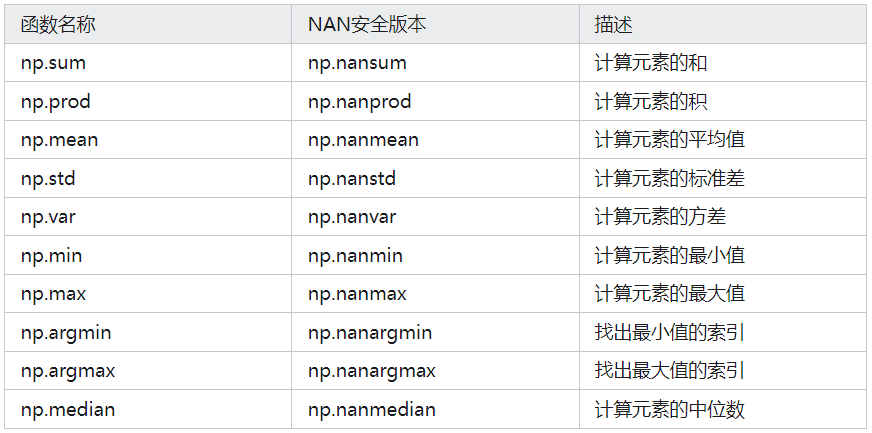
补充:使用np.sum或者是a.sum即可实现。并且在使用的时候,可以指定具体哪个轴。同样python中也内置了sum函数,但是python内置的sum函数执行效率没有np.sum那么高。
4.布尔数组的函数

5.排序函数
- np.sort
- np.argsort
- np.sort (降序)
6.其他函数
- np.apply_along_axis
- np.linspace
- np.unique
import numpy as np
a=np.array([12,3,56,7,0,21,9,38,19])
print(a)
#查看数组中是不是所有元素都为0
#方式一
print(np.all(a==0))
#方式二
print((a==0).all())
#查看数组中是否有等于0的数
#方式一
print(np.any(a==0))
#方式二
print((a==0).any())
[12 3 56 7 0 21 9 38 19]
False
False
True
True
#生成数组
a = np.random.randint(0,10,size=(5,5))
print(a)
#按照行进行排序,因为最后一个轴是1,那么就是将最里面的元素进行排序
print(np.sort(a))
#按照列进行排序,因为指定了axis=0
print(np.sort(a,axis=0))
#不会影响原数组的内容
print(a)
[[1 5 5 4 8]
[2 9 6 2 6]
[4 0 5 1 5]
[1 8 6 1 9]
[4 2 2 5 8]]
[[1 4 5 5 8]
[2 2 6 6 9]
[0 1 4 5 5]
[1 1 6 8 9]
[2 2 4 5 8]]
[[1 0 2 1 5]
[1 2 5 1 6]
[2 5 5 2 8]
[4 8 6 4 8]
[4 9 6 5 9]]
[[1 5 5 4 8]
[2 9 6 2 6]
[4 0 5 1 5]
[1 8 6 1 9]
[4 2 2 5 8]]
#返回排序后的下标值
print(np.argsort(a))
[[0 3 1 2 4]
[0 3 2 4 1]
[1 3 0 2 4]
[0 3 2 1 4]
[1 2 0 3 4]]
#np.sort()默认会采用升序排序,用一下方案来实现降序排序
#方式一:使用负号
print(-np.sort(-a))
#方式二:使用sort和argsort以及take
#排序后的结果就是降序的
indexes = np.argsort(-a)
#从a中根据下标提取相应的元素
print(np.take(a,indexes))
[[8 5 5 4 1]
[9 6 6 2 2]
[5 5 4 1 0]
[9 8 6 1 1]
[8 5 4 2 2]]
[[8 5 5 4 1]
[5 5 8 1 4]
[5 8 1 4 5]
[8 5 5 1 4]
[8 4 1 5 5]]
#np.apply_along_axis沿着某个轴执行指定的函数
#求数组a按行求平均值,并且要去掉最大值和最小值
#函数
def get_mean(x):
#排除最大值和最小值后求平均值
y=x[np.logical_and(x!=x.max,x!=x.min)].mean()
return y
#方式一:调用函数,求每一行的平均值
print(np.apply_along_axis(get_mean,axis=1,arr=a))
#方式二:lambda表达式,求每一行的平均值
print(np.apply_along_axis(lambda x:x[np.logical_and(x!=x.max,x!=x.min)].mean(),axis=1,arr=a))
[4.6 5. 3. 5. 4.2]
[4.6 5. 3. 5. 4.2]
#函数说明:np.linspace用来将指定区间内的值平均分成多少份
#将0-10分成5份,生成一个数组
arr = np.linspace(0,10,5)
print(arr)
[ 0. 2.5 5. 7.5 10. ]
#返回数组a中的元素,去除重复的元素
d=np.array([34,12,9,45,9,0,12,34,9])
print(np.unique(d))
#返回数组a中的唯一值,并且会返回每个唯一值出现的次数
print(np.unique(d,return_counts=True))
[ 0 9 12 34 45]
(array([ 0, 9, 12, 34, 45]), array([1, 3, 2, 2, 1], dtype=int64))