ElasticsearchSearch查询。
1.Search查询
在ES中查询单条数据可以使用Get,想要查询一批满足条件的数据的话,就需要使用Search了。 下面来看一个案例,查询索引库中的所有数据,代码如下:
1).初始化一个名字叫myschool的索引,插入15条记录。
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/1' -d '{"name":"tom","age":20}'
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/2' -d '{"name":"tom","age":15}'
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/3' -d '{"name":"jack","age":17}'
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/4' -d '{"name":"jess","age":19}'
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/5' -d '{"name":"mick","age":23}'
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/6' -d '{"name":"lili","age":12}'
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/7' -d '{"name":"john","age":28}'
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/8' -d '{"name":"jojo","age":30}'
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/9' -d '{"name":"bubu","age":16}'
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/10' -d '{"name":"pig","age":21}'
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/11' -d '{"name":"mary","age":19}'
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/12' -d '{"name":"johnson","age":19}'
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/13' -d '{"name":"niuniu","age":22}'
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/14' -d '{"name":"antoni","age":19}'
curl -H "Content-Type: application/json" -XPOST 'http://master:9200/myschool/_doc/15' -d '{"name":"simoni","age":17}'
使用RestfulAPI查询所有数据。
http://master:9200/myschool/_search?pretty
注意:Elasticsearch默认只返回十条数据以减轻ES的负载压力。
2).Java API实现
package com.simoniu.db_elasticsearch.search;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
/**
* Search详解
* Created by simoniu
*/
public class EsSearchOperateDemo {
public static void main(String[] args) throws Exception{
//获取RestClient连接
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("master", 9200, "http"),
new HttpHost("slave1", 9200, "http"),
new HttpHost("slave2", 9200, "http")));
SearchRequest searchRequest = new SearchRequest();
//指定索引库,支持指定一个或者多个,也支持通配符,例如:user*
searchRequest.indices("myschool");
//执行查询操作
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//获取查询返回的结果
SearchHits hits = searchResponse.getHits();
//获取数据总量
long numHits = hits.getTotalHits().value;
System.out.println("数据总数:"+numHits);
//获取具体内容
SearchHit[] searchHits = hits.getHits();
//迭代解析具体内容
for (SearchHit hit : searchHits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
//关闭连接
client.close();
}
}
运行结果:
数据总数:15
{"name":"jess","age":19}
{"name":"tom","age":20}
{"name":"tom","age":15}
{"name":"jack","age":17}
{"name":"mick","age":23}
{"name":"lili","age":12}
{"name":"john","age":28}
{"name":"jojo","age":30}
{"name":"bubu","age":16}
{"name":"pig","age":21}
2.searchType详解
ES在查询数据的时候可以指定searchType,也就是搜索类型。
//指定searchType
searchRequest.searchType(SearchType.QUERY_THEN_FETCH);

其中QUERY AND FETCH和DFS QUERY AND FETCH这两种searchType现在已经不支持了。
这4种搜索类型到底有什么区别,下面我们来详细分析一下。 在具体分析这4种搜索类型的区别之前,我们先分析一下分布式搜索的背景: ES天生就是为分布式而生的,但分布式有分布式的缺点,比如要搜索某个单词,但是数据却分别在5个分片(Shard)上面,这5个分片可能在5台主机上面。因为全文搜索天生就要排序(按照匹配度进行排名),但数据却在5个分片上,如何得到最后正确的排序呢?ES是这样做的,大概分两步。
- ES客户端将会同时向5个分片发起搜索请求。
- 这5个分片基于本分片的内容独立完成搜索,然后将符合条件的结果全部返回。
大致流程如下图所示:
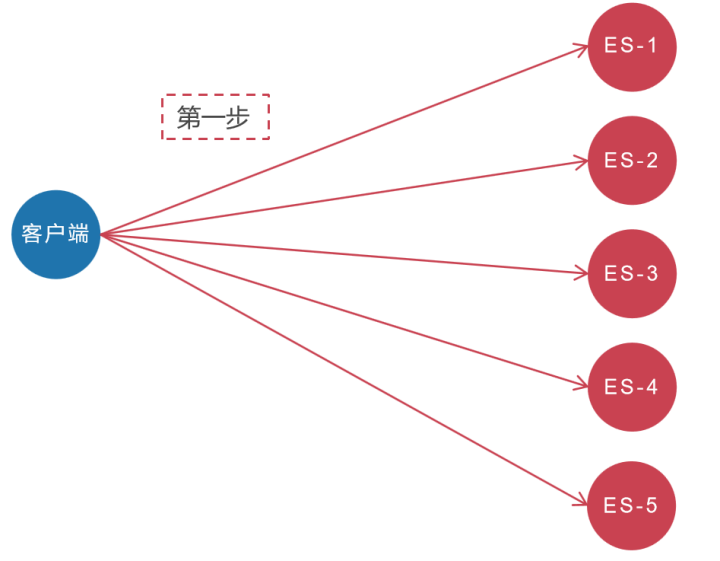
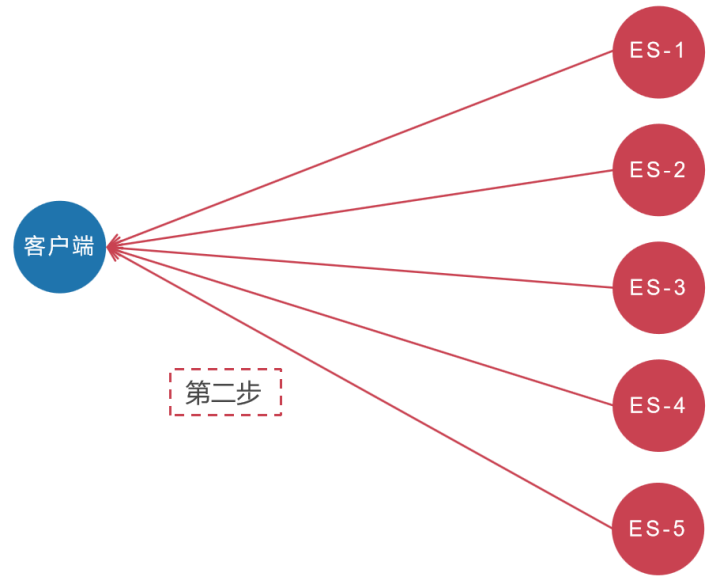
然而这其中有两个问题。
第一:数量问题。比如,用户需要搜索"衣服",要求返回符合条件的前10条。但在5个分片中,可能都存储着衣服相关的数据。所以ES会向这5个分片都发出查询请求,并且要求每个分片都返回符合条件的10条记录。这种情况,ES中5个分片最多会收到10*5=50条记录,这样返回给用户的结果数量会多于用户请求的数量。 第二:排名问题。上面说的搜索,每个分片计算符合条件的前10条数据都是基于自己分片的数据进行打分计算的。计算分值使用的词频和文档频率等信息都是基于自己分片的数据进行的,而ES进行整体排名是基于每个分片计算后的分值进行排序的(相当于打分依据就不一样,最终对这些数据统一排名的时候就不准确了),这就可能会导致排名不准确的问题。如果我们想更精确的控制排序,应该先将计算排序和排名相关的信息(词频和文档频率等打分依据)从5个分片收集上来,进行统一计算,然后使用整体的词频和文档频率为每个分片中的数据进行打分,这样打分依据就一样了。
这两个问题,ES也没有什么较好的解决方法,最终把选择的权利交给用户,方法就是在搜索的时候指定searchType。
-
QUERY AND FETCH 向索引的所有分片都发出查询请求,各分片返回的时候把元素文档(document)和计算后的排名信息一起返回。 这种搜索方式是最快的。因为相比下面的几种搜索方式,这种查询方法只需要去分片查询一次。但是各个分片返回的结果的数量之和可能是用户要求的数据量的N倍。 优点: 只需要查询一次 缺点: 返回的数据量不准确,可能返回(N*分片数量)的数据 并且数据排名也不准确
-
QUERY THEN FETCH(ES默认的搜索方式) 如果你搜索时,没有指定搜索方式,就是使用的这种搜索方式。这种搜索方式,大概分两个步骤, 第一步,先向所有的分片发出请求,各分片只返回文档id(注意,不包括文档document)和排名相关的信息(也就是文档对应的分值),然后按照各分片返回的文档的分数进行重新排序和排名,取前size个文档。 第二步,根据文档id去相关的分片取文档。这种方式返回的文档数量与用户要求的数量是相等的。 优点: 返回的数据量是准确的 缺点: 性能一般, 并且数据排名不准确
-
DFS QUERY AND FETCH 这种方式比第一种方式多了一个DFS步骤,有这一步,可以更精确控制搜索打分和排名。 也就是在进行查询之前,先对所有分片发送请求,把所有分片中的词频和文档频率等打分依据全部汇总到一块,再执行后面的操作、 优点: 数据排名准确 缺点: 性能一般 返回的数据量不准确,可能返回(N*分片数量)的数据
-
DFS QUERY THEN FETCH 比第2种方式多了一个DFS步骤。 也就是在进行查询之前,先对所有分片发送请求,把所有分片中的词频和文档频率等打分依据全部汇总到一块,再执行后面的操作、 优点: 返回的数据量是准确的 数据排名准确 缺点: 性能最差【这个最差只是表示在这四种查询方式中性能最慢,也不至于不能忍受,如果对查询性能要求不是非常高,而对查询准确度要求比较高的时候可以考虑这个】
总结一下,从性能考虑QUERY_AND_FETCH是最快的,DFS_QUERY_THEN_FETCH是最慢的。从搜索的准确度来说,DFS要比非DFS的准确度更高。
目前官方舍弃了QUERY AND FETCH和DFS QUERY AND FETCH这两种类型,保留了QUERY THEN FETCH和DFS QUERY THEN FETCH,这两种都是可以保证数据量是准确的。如果对查询的精确度要求没那么高,就使用QUERY THEN FETCH,如果对查询数据的精确度要求非常高,就使用DFS QUERY THEN FETCH。