使用RestAPI的方式操作ES的索引库。
1.Elasticsearch操作方式
从Elasticsearch官网查询得知Es提供了很多种操作方式。
在实际工作中使用ES的时候,如果想屏蔽语言的差异,建议使用REST API,这种兼容性比较好,但是这种操作使用起来比较麻烦,需要拼接组装各种数据字符串。
针对Java程序员而言,还有一种选择是使用Java API,这种方式相对于REST API而言,代码量会大一些,但是代码层面看起来是比较清晰的。
下来咱们就主要针对RestAPI和JavaAPI两种方式探讨。
2.使用REST API的方式操作ES
如果想要在Linux命令行中使用REST API操作ES,需要借助于CURL工具。CURL是利用URL语法在命令行下工作的开源文件传输工具,使用CURL可以简单实现常见的get/post请求。
curl后面通过-X参数指定请求类型,通过-d指定要传递的参数。
- 索引库的操作(创建、删除)
#创建索引库:
curl -XPUT 'http://master:9200/test/'
#这里使用PUT或者POST都可以。
注意:索引库名称必须要全部小写,不能以_、 -、 +开头,也不能包含逗号。
- 删除索引库
[es@master elasticsearch]$ curl -XDELETE 'http://master:9200/test'
{"acknowledged":true}
注意:索引库可以提前创建,也可以在后期添加数据的时候直接指定一个不存在的索引库,ES默认会自动创建这个索引库。
手工创建索引库和自动创建索引库的区别就是,手工创建可以自定义索引库的分片数量。
下面的命令就是创建一个具有3个分片的索引库。
[es@master elasticsearch]$ curl -H "Content-Type: application/json" -XPUT 'http://master:9200/test/' -d'{"settings":{"index.number_of_shards":3}}'
{"acknowledged":true,"shards_acknowledged":true,"index":"test"}
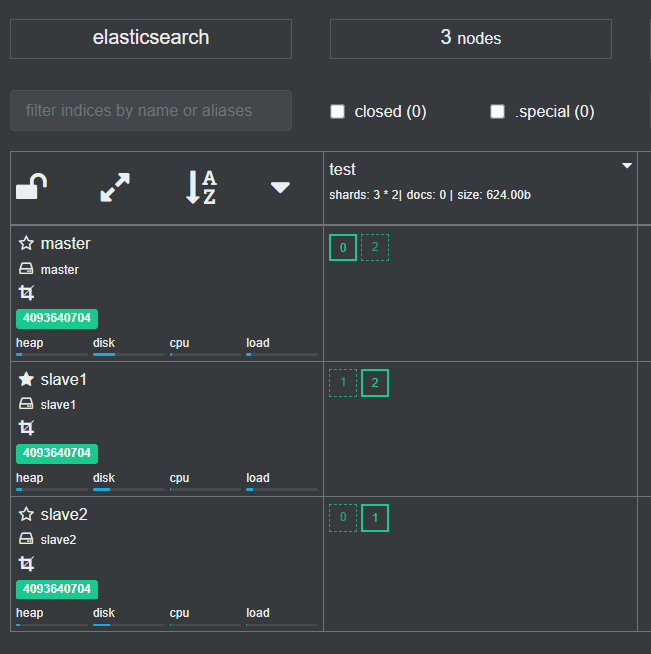
其中实线的框表示是主分片,虚线框是副本分片。 索引分片编号是从0开始的,并且索引分片在物理层面是存在的,可以到集群中查看一下,从界面中也看到test索引库的1号和2号分片是在slave1和slave2节点上的。
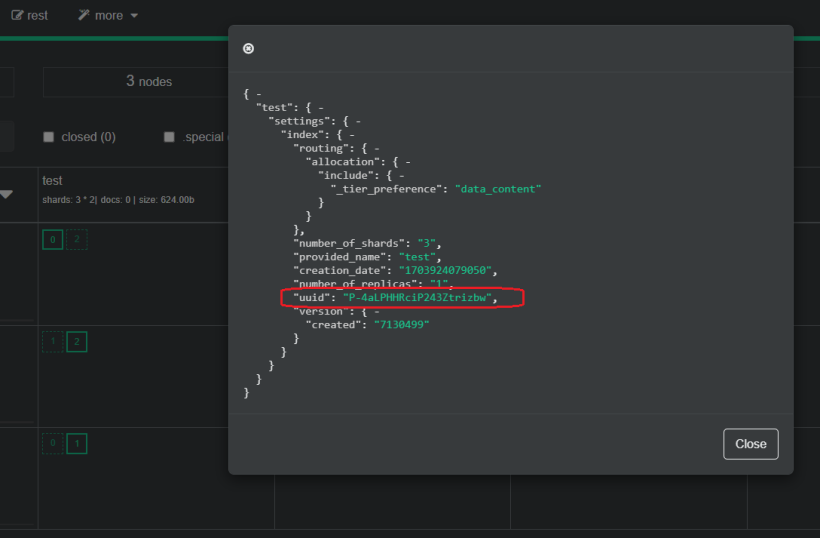
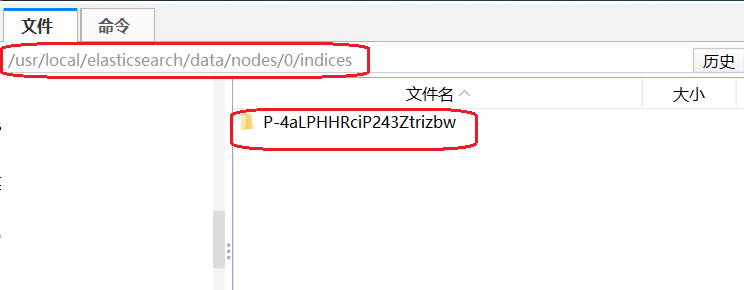
选择test的show settings选项,里面可以查看这里面的P-4aLPHHRciP243Ztrizbw表示的是索引库的UUID。我们也可以到master节点中看一下,ES中的所有数据都在ES的数据存储目录中,默认是在ES_HOME下的data目录里面。
- 索引的操作(增、删、改、查、Bulk批量操作)
添加索引:
[root@master ~]# curl -H "Content-Type: application/json" -XPOST 'http://master:9200/test/_doc/1' -d '{"name":"tom","age":20,"gender":"male"}'
{"_index":"test","_type":"_doc","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":2,"failed":0},"_seq_no":0,"_primary_term":1}
注意:为了兼容之前的API,虽然ES现在取消了Type,但是API中Type的位置还是预留出来了,官方建议统一使用_doc 。在添加索引的时候,如果没有指定数据的ID,那么ES会自动生成一个随机的唯一ID。
[root@master ~]# curl -H "Content-Type: application/json" -XPOST 'http://master:9200/test/_doc' -d '{"name":"jack","age":18,"gender":"female"}'
{"_index":"test","_type":"_doc","_id":"Ir83u4wBdrgv2d8H3aCW","_version":1,"result":"created","_shards":{"total":2,"successful":2,"failed":0},"_seq_no":0,"_primary_term":1}
查询索引: 查看id=1的索引数据。
[root@master ~]# curl -XGET 'http://master:9200/test/_doc/1?pretty'
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "tom",
"age" : 20,
"gender" : "male"
}
}
只查询获取部分字段内容。
[root@master ~]# curl -XGET 'http://master:9200/test/_doc/1?_source=name,age&pretty'
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "tom",
"age" : 20
}
}
查询指定索引库中所有数据。
[root@master ~]# curl -XGET 'http://master:9200/test/_search?pretty'
{
"took" : 91,
"timed_out" : false,
"_shards" : {
"total" : 3,
"successful" : 3,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "Ir83u4wBdrgv2d8H3aCW",
"_score" : 1.0,
"_source" : {
"name" : "jack",
"age" : 18,
"gender" : "female"
}
},
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "tom",
"age" : 20,
"gender" : "male"
}
}
]
}
}
注意:针对这种查询操作,可以在浏览器里面执行,或者在cerebo中查询都是可以的,这样看起来更加清晰。
更新索引: 可以分为全部更新和局部更新
- 全部更新:同添加索引,如果指定id的索引数据(文档)已经存在,则执行更新操作。
注意:执行更新操作的时候,ES首先将旧的文标记为删除状态,然后添加新的文档。旧的文档不会立即消失,但是你也无法访问,ES会在你继续添加更多数据的时候在后台清理已经标记为删除状态的文档。
- 局部更新:可以添加新字段或者更新已有字段,必须使用POST请求。
[root@master ~]# curl -H "Content-Type: application/json" -XPOST 'http://master:9200/test/_doc/1/_update' -d '{"doc":{"gender":"female"}}'
{"_index":"test","_type":"_doc","_id":"1","_version":2,"result":"updated","_shards":{"total":2,"successful":2,"failed":0},"_seq_no":1,"_primary_term":1}
删除索引: 删除id=1的索引数据。
[root@master ~]# curl -XDELETE 'http://master:9200/test/_doc/1'
{"_index":"test","_type":"_doc","_id":"1","_version":3,"result":"deleted","_shards":{"total":2,"successful":2,"failed":0},"_seq_no":2,"_primary_term":1}
如果索引数据(文档)存在,ES返回的数据中,result属性值为deleted,_version(版本)属性的值+1。 如果索引数据不存在,ES返回的数据中,result属性值为not_found,但是_version属性的值依然会+1,这属于ES的版本控制系统,它保证了我们在多个节点间的不同操作的顺序都被正确标记了。 对于索引数据的每次写操作,无论是 index,update 还是 delete,ES都会将_version增加 1。该增加是原子的,并且保证在操作成功返回时会发生。
#再次执行删除
[root@master ~]# curl -XDELETE 'http://master:9200/test/_doc/1'
{"_index":"test","_type":"_doc","_id":"1","_version":4,"result":"not_found","_shards":{"total":2,"successful":2,"failed":0},"_seq_no":3,"_primary_term":1}
注意:删除一条索引数据(文档)也不会立即生效,它只是被标记成已删除状态。ES将会在你之后添加更多索引数据的时候才会在后台清理标记为删除状态的内容。
Bulk批量操作:
Bulk API可以帮助我们同时执行多个请求,提高效率。 格式:
{ action: { metadata }}
{ request body }
解释:
- action:index/create/update/delete
- metadata:_index,_type,_id
- request body:_source(删除操作不需要)
create 和index的区别:如果数据存在,使用create操作失败,会提示文档已经存在,使用index则可以成功执行。
下面来看一个案例,假设在MySQL中有一批数据,首先需要从MySQL中把数据读取出来,然后将数据转化为Bulk需要的数据格式。 在这直接手工生成Bulk需要的数据格式。
[root@master elasticsearch]# vim request
{ "index" : { "_index" : "test", "_type" : "_doc", "_id" : "1" } }
{ "name" : "messi","age":37,"gender":"male" }
{ "index" : { "_index" : "test", "_type" : "_doc", "_id" : "2" } }
{ "name" : "ronaldo" }
{ "delete" : { "_index" : "test", "_type" : "_doc", "_id" : "2" } }
{ "create" : { "_index" : "test", "_type" : "_doc", "_id" : "3" } }
{ "name" : "backham","age":45,"gender":"male" }
{ "update" : {"_index" : "test", "_type" : "_doc","_id" : "1" } }
{ "doc" : {"age" : 40} }
执行Bulk API。
[root@master ~]# curl -H "Content-Type: application/json" -XPUT 'http://master:9200/test/_doc/_bulk' --data-binary @request
{"took":24,"errors":false,"items":[{"index":{"_index":"test","_type":"_doc","_id":"1","_version":5,"result":"updated","_shards":{"total":2,"successful":2,"failed":0},"_seq_no":8,"_primary_term":1,"status":200}},{"index":{"_index":"test","_type":"_doc","_id":"2","_version":1,"result":"created","_shards":{"total":2,"successful":2,"failed":0},"_seq_no":9,"_primary_term":1,"status":201}},{"delete":{"_index":"test","_type":"_doc","_id":"2","_version":2,"result":"deleted","_shards":{"total":2,"successful":2,"failed":0},"_seq_no":10,"_primary_term":1,"status":200}},{"create":{"_index":"test","_type":"_doc","_id":"3","_version":3,"result":"created","_shards":{"total":2,"successful":2,"failed":0},"_seq_no":11,"_primary_term":1,"status":201}},{"update":{"_index":"test","_type":"_doc","_id":"1","_version":6,"result":"updated","_shards":{"total":2,"successful":2,"failed":0},"_seq_no":9,"_primary_term":1,"status":200}}]}
查看结果:
{ -
"took": 4,
"timed_out": false,
"_shards": { -
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": { -
"total": { -
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [ -
{ -
"_index": "test",
"_type": "_doc",
"_id": "Ir83u4wBdrgv2d8H3aCW",
"_score": 1,
"_source": { -
"name": "jack",
"age": 18,
"gender": "female"
}
},
{ -
"_index": "test",
"_type": "_doc",
"_id": "3",
"_score": 1,
"_source": { -
"name": "backham",
"age": 45,
"gender": "male"
}
},
{ -
"_index": "test",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": { -
"name": "messi",
"age": 40,
"gender": "male"
}
}
]
}
}
Bulk一次最大可以处理多少数据量?
Bulk会把将要处理的数据加载到内存中,所以数据量是有限制的,最佳的数据量不是一个确定的数值,它取决于集群硬件,文档大小、文档复杂性,索引以及ES集群的负载。 一般建议是1000-5000个文档,如果文档很大,可以适当减少,文档总大小建议是5-15MB,默认不能超过100M。 如果想要修改最大限制大小,可以在ES的配置文件中修改http.max_content_length: 100mb,但是不建议,因为太大的话Bulk操作也会慢。