SparkStreaming入门
SparkStreaming入门
SparkStreaming入门
1.Spark Streaming
Spark Streaming是Spark Core API的一种扩展,它可以用于进行大规模、高吞吐量、容错的实时数据流的处理。 注意:这个实时属于近实时,最小可以支持秒级别的实时处理。
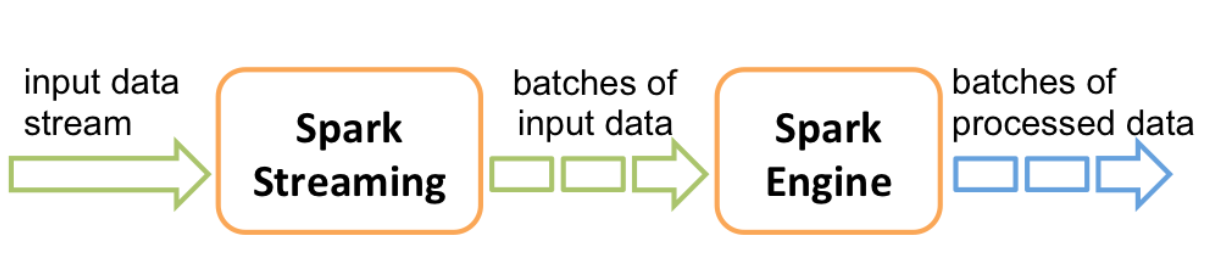
2.SparkStreaming工作原理
Spark Streaming的工作原理是这样的: 接收实时输入数据流,然后将数据拆分成多个batch,比如每收集1秒的数据封装为一个batch,然后将每个batch交给Spark计算引擎进行处理,最后会生产出一个结果数据流,其中的数据,也是由一个一个的batch所组成的。
3.实时WordCount程序开发
下面我们来开发一个Spark Streaming的实时WordCount程序感受一下SparkStreaming的魅力。
在spark基础教程的工程里,我们添加Spark Streaming的依赖。
<dependencies>
...
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark-version}</version>
<!--
<scope>provided</scope>
-->
</dependency>
</dependencies>
开发实时WordCount程序。 需求:通过socket模拟产生数据,实时计算数据中单词出现的次数。
scala代码实现:
package com.simoniu.scalademo
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 需求:通过socket模拟产生数据,实时计算数据中单词出现的次数
* Created by simoniu
*/
object StreamWordCountScalaDemo {
def main(args: Array[String]): Unit = {
//创建SparkConf配置对象
val conf = new SparkConf()
//注意:此处的local[2]表示启动2个进程,一个进程负责读取数据源的数据,一个进程负责处理数据
.setMaster("local[2]")
.setAppName("StreamWordCountScala")
//创建StreamingContext,指定数据处理间隔为5秒
val ssc = new StreamingContext(conf, Seconds(5))
//通过socket获取实时产生的数据
val linesRDD = ssc.socketTextStream("master", 9002)
//对接收到的数据使用空格进行切割,转换成单个单词
val wordsRDD = linesRDD.flatMap(_.split(" "))
//把每个单词转换成tuple2的形式
val tupRDD = wordsRDD.map((_, 1))
//执行reduceByKey操作
val wordcountRDD = tupRDD.reduceByKey(_ + _)
//将结果数据打印到控制台
wordcountRDD.print()
//启动任务
ssc.start()
//等待任务停止
ssc.awaitTermination()
}
}
在master主机,开启socket,输入测试数据:
[root@master kafka]# nc -l 9002
hello you
hello me
hello java
hello spark
在控制台查看输出结果如下:
-------------------------------------------
Time: 1703132640000 ms
-------------------------------------------
(hello,4)
(java,1)
(me,1)
(spark,1)
(you,1)
java代码实现:
package com.simoniu.sparkdemo.javademo;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* 需求:通过socket模拟产生数据,实时计算数据中单词出现的次数
* Created by simoniu
*/
public class StreamWordCountJavaDemo {
public static void main(String[] args) throws Exception {
//创建SparkConf配置对象
SparkConf conf = new SparkConf()
.setMaster("local[2]")
.setAppName("StreamWordCountJava");
//创建StreamingContext,指定数据处理间隔为5秒
JavaStreamingContext ssc = new JavaStreamingContext(conf, Durations.seconds(5));
//通过socket获取实时产生的数据
JavaReceiverInputDStream<String> linesRDD = ssc.socketTextStream("master", 9002);
//对接收到的数据使用空格进行切割,转换成单个单词
JavaDStream<String> wordsRDD = linesRDD.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
//把每个单词转换为tuple2的形式
JavaPairDStream<String, Integer> pairRDD = wordsRDD.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
//执行reduceByKey操作
JavaPairDStream<String, Integer> wordCountRDD = pairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
//将结果数据打印到控制台
wordCountRDD.foreachRDD(new VoidFunction<JavaPairRDD<String, Integer>>() {
public void call(JavaPairRDD<String, Integer> pair) throws Exception {
pair.foreach(new VoidFunction<Tuple2<String, Integer>>() {
public void call(Tuple2<String, Integer> tup) throws Exception {
System.out.println(tup._1 + "---" + tup._2);
}
});
}
});
//启动任务
ssc.start();
//等待任务停止
ssc.awaitTermination();
}
}