KafkaProducer的使用
KafkaProducer的使用
KafkaProducer的使用。
1.KafkaProducer的使用
我们来看一下在Flink中如何向Kafka中写数据,此时需要用到Kafka Producer。
scala代码实现如下:
package com.simoniu.flink.scala.kafkaconnector
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer
import org.apache.flink.streaming.connectors.kafka.internals.KafkaSerializationSchemaWrapper
import org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner
/**
* Flink向Kafka中生产数据
* Created by simoniu
*/
object StreamKafkaSinkScalaDemo {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//注意:这里的端口不能使用9001,因为CMAK默认占用了 9001端口。
val text = env.socketTextStream("master", 9002)
//指定FlinkKafkaProducer的相关配置
val topic = "t2"
val prop = new Properties()
prop.setProperty("bootstrap.servers","master:9092,slave1:9092,slave2:9092")
//指定kafka作为sink
/*
KafkaSerializationSchemaWrapper的几个参数
1:topic:指定需要写入的topic名称即可
2:partitioner,通过自定义分区器实现将数据写入到指定topic的具体分区中
默认会使用FlinkFixedPartitioner,它表示会将所有的数据都写入指定topic的一个分区里面
如果不想自定义分区器,也不想使用默认的,可以直接使用null即可
3:writeTimeStamp,向topic中写入数据的时候,是否写入时间戳
如果写入了,那么在watermark的案例中,使用extractTimestamp()提起时间戳的时候
就可以直接使用recordTimestamp即可,它表示的就是我们在这里写入的数据对应的timestamp
*/
val kafkaProducer = new FlinkKafkaProducer[String](topic, new KafkaSerializationSchemaWrapper[String](topic, new FlinkFixedPartitioner[String](), false, new SimpleStringSchema()), prop, FlinkKafkaProducer.Semantic.EXACTLY_ONCE)
//val kafkaProducer = new FlinkKafkaProducer[String](topic, new KafkaSerializationSchemaWrapper[String](topic, null, false, new SimpleStringSchema()), prop, FlinkKafkaProducer.Semantic.EXACTLY_ONCE)
text.addSink(kafkaProducer)
env.execute("StreamKafkaSinkScala")
}
}
在执行代码之前,需要创建topic:t2
[root@master kafka]# cd $KAFKA_HOME
[root@master kafka]# bin/kafka-topics.sh --create --zookeeper master:2181 --partitions 5 --replication-factor 2 --topic t2
在master上开启socket,产生数据:
[root@master cmak-3.0.0.4]# nc -l 9002
启动程序后输入测试数据。
[root@master cmak-3.0.0.4]# nc -l 9002
hello
haha
xixi
hehe
java
win
back
ok
sql
这里一共输入了9条测试数据。打开CMAK WEB界面观察。
http://master:9001/clusters/kafka2.4.1/topics/t2
我们发现所有数据都在一个分区中。
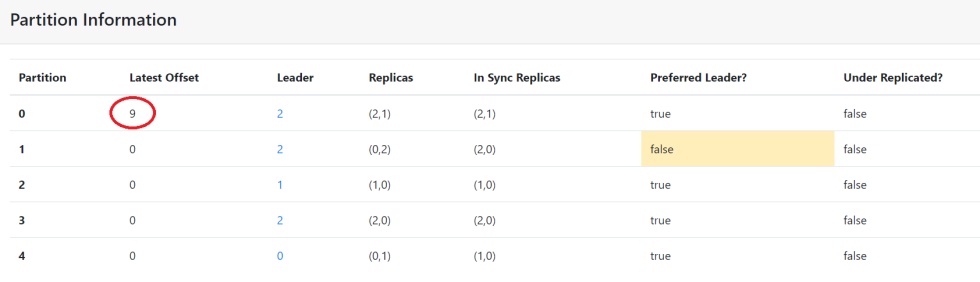
如果我们不需要自定义分区器的时候,直接传递为null即可,不要使用FlinkFixedPartitioner,它会将数据都写入到topic的一个分区中。将FlinkFixedPartitioner设置为null,重新验证一次,创建一个新的topic,t3
[root@master cmak-3.0.0.4]# cd $KAFKA_HOME
[root@master kafka]# bin/kafka-topics.sh --create --zookeeper master:2181 --partitions 5 --replication-factor 2 --topic t3
代码修改如下:
package com.simoniu.flink.scala.kafkaconnector
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer
import org.apache.flink.streaming.connectors.kafka.internals.KafkaSerializationSchemaWrapper
import org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner
/**
* Flink向Kafka中生产数据
* Created by simoniu
*/
object StreamKafkaSinkScalaDemo {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//注意:这里的端口不能使用9001,因为CMAK默认占用了 9001端口。
val text = env.socketTextStream("master", 9002)
//指定FlinkKafkaProducer的相关配置
val topic = "t3"
val prop = new Properties()
prop.setProperty("bootstrap.servers","master:9092,slave1:9092,slave2:9092")
//指定kafka作为sink
/*
KafkaSerializationSchemaWrapper的几个参数
1:topic:指定需要写入的topic名称即可
2:partitioner,通过自定义分区器实现将数据写入到指定topic的具体分区中
默认会使用FlinkFixedPartitioner,它表示会将所有的数据都写入指定topic的一个分区里面
如果不想自定义分区器,也不想使用默认的,可以直接使用null即可
3:writeTimeStamp,向topic中写入数据的时候,是否写入时间戳
如果写入了,那么在watermark的案例中,使用extractTimestamp()提起时间戳的时候
就可以直接使用recordTimestamp即可,它表示的就是我们在这里写入的数据对应的timestamp
*/
//val kafkaProducer = new FlinkKafkaProducer[String](topic, new KafkaSerializationSchemaWrapper[String](topic, new FlinkFixedPartitioner[String](), false, new SimpleStringSchema()), prop, FlinkKafkaProducer.Semantic.EXACTLY_ONCE)
val kafkaProducer = new FlinkKafkaProducer[String](topic, new KafkaSerializationSchemaWrapper[String](topic, null, false, new SimpleStringSchema()), prop, FlinkKafkaProducer.Semantic.EXACTLY_ONCE)
text.addSink(kafkaProducer)
env.execute("StreamKafkaSinkScala")
}
}
重新启动程序,验证效果。在master上开启socket,产生数据:
[root@master kafka]# nc -l 9002
hee
ik
java
world
python
linux
welcome
you
me
china
这里一共产生了10条测试数据,打开CMAK WEB界面观察。
http://master:9001/clusters/kafka2.4.1/topics/t3
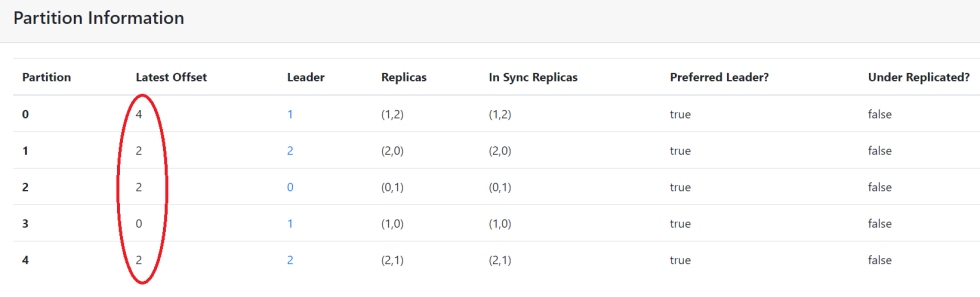
此时我们发现所有数据分配在不同分区上了。
java代码实现:
package com.simoniu.flink.java.kafkaconnector;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.internals.KafkaSerializationSchemaWrapper;
import java.util.Properties;
/**
* Flink向Kafka中生产数据
* Created by simoniu
*/
public class StreamKafkaSinkJavaDemo {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> text = env.socketTextStream("master", 9002);
//指定FlinkKafkaProducer相关配置
String topic = "t3";
Properties prop = new Properties();
prop.setProperty("bootstrap.servers","master:9092,slave1:9092,slave2:9092");
//指定kafka作为sink
FlinkKafkaProducer<String> kafkaProducer = new FlinkKafkaProducer<>(topic, new KafkaSerializationSchemaWrapper<String>(topic, null, false, new SimpleStringSchema()), prop, FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
text.addSink(kafkaProducer);
env.execute("StreamKafkaSinkJava");
}
}