Watermark的分析。
1.Watermark
当我们使用EventTime处理流数据的时候会遇到数据乱序的问题,流处理从数据产生,到流经Source,再到具体的算子,中间是有一个过程和时间的。虽然大部分情况下,传输到算子的数据都是按照数据产生的时间顺序来的,但是也不排除由于网络延迟等原因,导致乱序现象的产生,特别是使用Kafka的时候,多个分区之间的数据无法保证有序。所以在进行Window计算的时候,我们又不能无限期地等下去,必须要有一个机制来保证一个特定的时间,必须触发Window去进行计算了,这个特别的机制就是Watermark。
2.有序数据流的Watermark
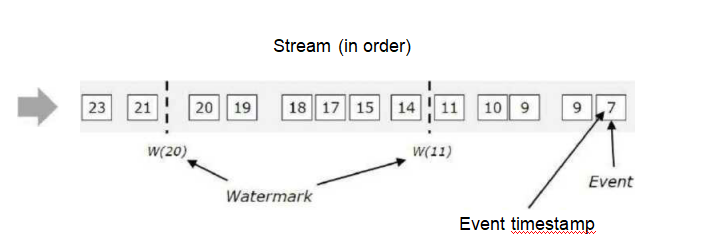
in order :有序的数据流,从左往右。
w(11):表示watermark的值为11,此时表示11之前的数据都到了,可以进行计算了。 w(20):表示watermark的值为20,此时表示20之前的数据都到了,可以进行计算了。
3.无序数据流的Watermark
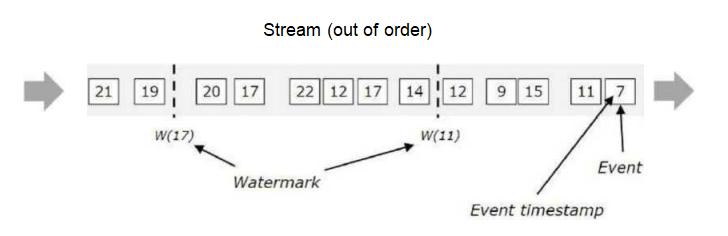
out of order:无序的数据流。
w(11):此时表示11之前的数据都到了,可以对11之前的数据进行计算了,大于11的数据暂时不计算。 w(17):此时表示17之前的数据都到了,可以对17之前的数据进行计算了,大于17的数据暂时不计算。
4.多并行度数据流的Watermark
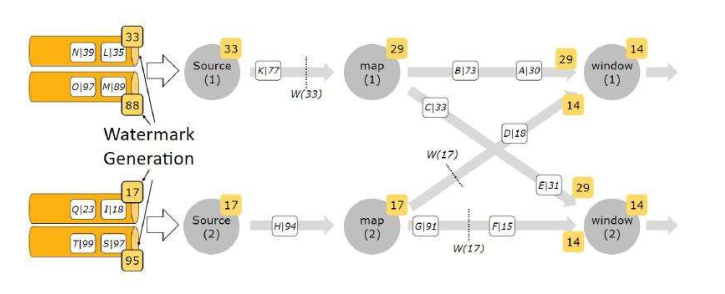
注意:在多并行度的情况下,Watermark会有一个对齐机制,这个对齐机制会取所有Channel中最小的Watermark,图中的14和29这两个Watermark,最终取值为14。这样才不会漏掉数据。
5.Watermark的生成方式
通常情况下,在接收到Source的数据后,应该立刻生成Watermark,但是也可以在使用Map或者Filter操作之后,再生成Watermark。
Watermark的生成方式有两种: - With Periodic Watermarks:周期性触发Watermark的生成和发送。 - With Punctuated Watermarks:基于事件向流里面注入一个Watermark,每一个元素都有机会判断是否生成一个Watermark.