DataStreamAPI之分区算子
DataStreamAPI之分区算子
DataStreamAPI之分区算子。
1.DataStreamAPI之分区算子

针对以上这几种分区的解释,下面来通过几个图总结一下,加深理解。
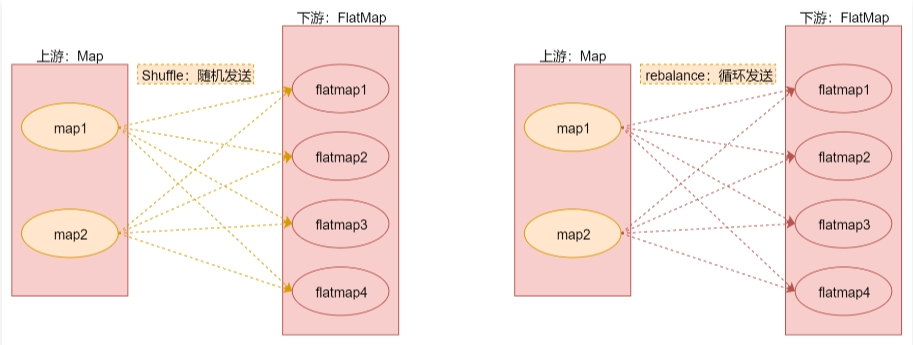 random + rebalance
random + rebalance
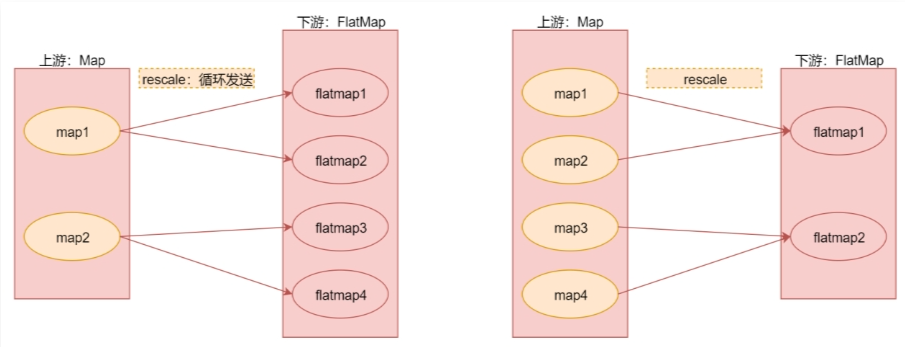 rescala
注意:rescale与rebalance的区别是rebalance会产生全量重分区,而rescale不会。
rescala
注意:rescale与rebalance的区别是rebalance会产生全量重分区,而rescale不会。
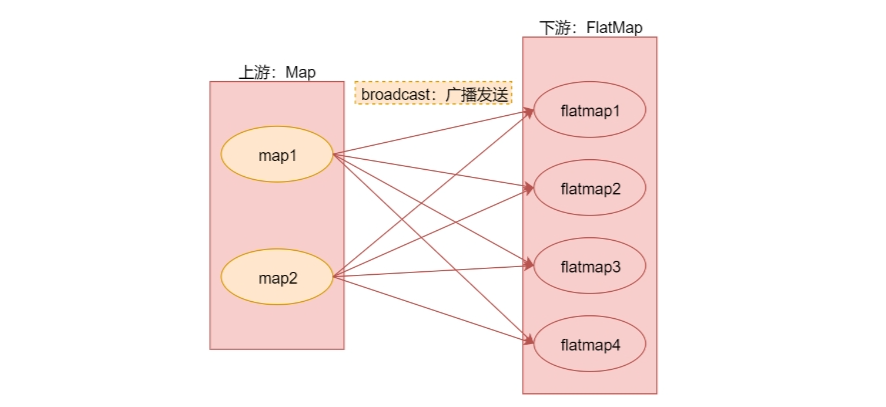 broadcast
broadcast
1).scala代码如下
package com.simoniu.flink.scala.stream.transformation
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.api.scala._
/**
* 分区规则的使用
* Created by simoniu
*/
object StreamPartitionOpScalaDemo {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//注意:默认情况下Fink任务中算子的并行度会读取当前机器的CPU个数
//fromCollection的并行度为1,由源码可知
val text = env.fromCollection(Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20))
//注意:在这里建议将这个隐式转换代码放到类上面
//因为默认它只在main函数生效,针对下面提取的shuffleOp是无效的,否则也需要在shuffleOp添加这行代码
//import org.apache.flink.api.scala._
//使用shuffle分区规则
//shuffleOp(text)
//使用rebalance分区规则
//rebalanceOp(text)
//使用rescale分区规则
//rescaleOp(text)
//使用broadcast分区规则,此代码一共会打印40条数据,因为print的并行度为4
//broadcastOp(text)
//自定义分区规则:根据数据的奇偶性进行分区
//注意:此时虽然print算子的并行度是4,但是自定义的分区规则只会把数据分发给2个并行度,所以有2个是不干活的
custormPartitionOp(text)
env.execute("StreamPartitionOpScala");
}
private def custormPartitionOp(text: DataStream[Int]) = {
text.map(num => num)
.setParallelism(2) //设置map算子的并行度为2
//.partitionCustom(new MyPartitionerScala,0)//这种写法已经过期
.partitionCustom(new MyPartitionerScala, num => num) //官方建议使用keyselector
.print()
.setParallelism(4) //设置print算子的并行度为4
}
private def broadcastOp(text: DataStream[Int]) = {
text.map(num => num)
.setParallelism(2) //设置map算子的并行度为2
.broadcast
.print()
.setParallelism(4) //设置print算子的并行度为4
}
private def rescaleOp(text: DataStream[Int]) = {
text.map(num => num)
.setParallelism(8) //设置map算子的并行度为8
.rescale
.print()
.setParallelism(4) //设置print算子的并行度为4
}
private def rebalanceOp(text: DataStream[Int]) = {
text.map(num => num)
.setParallelism(2) //设置map算子的并行度为2
.rebalance
.print()
.setParallelism(4) //设置print算子的并行度为4
}
private def shuffleOp(text: DataStream[Int]) = {
//由于fromCollection已经设置了并行度为1,所以需要再接一个算子之后才能修改并行度,在这使用map算子
text.map(num => num)
.setParallelism(2) //设置map算子的并行度为2
.shuffle
.print()
.setParallelism(4) //设置print算子的并行度为4
}
}
package com.simoniu.flink.scala.stream.transformation
import org.apache.flink.api.common.functions.Partitioner
/**
* 自定义分区规则:按照数字的奇偶性进行分区
* Created by simoniu
*/
class MyPartitionerScala extends Partitioner[Int]{
override def partition(key: Int, numPartitions: Int): Int = {
println("分区总数:"+numPartitions)
if(key % 2 == 0){//偶数分到0号分区
0
}else{//奇数分到1号分区
1
}
}
}
2).java实现
package com.simoniu.flink.java.stream.transformation;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* 分区规则的使用
* Created by simoniu
*/
public class StreamPartitionOpJavaDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> text = env.fromCollection(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20));
//使用shuffle分区规则
//shuffleOp(text);
//使用rebalance分区规则
//rebalanceOp(text);
//使用rescale分区规则
//rescaleOp(text);
//使用broadcast分区规则
//broadcastOp(text);
//自定义分区规则
//custormPartitionOp(text);
env.execute("StreamPartitionOpJava");
}
private static void custormPartitionOp(DataStreamSource<Integer> text) {
text.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer integer) throws Exception {
return integer;
}
}).setParallelism(2)
.partitionCustom(new MyPartitionerJava(), new KeySelector<Integer, Integer>() {
@Override
public Integer getKey(Integer integer) throws Exception {
return integer;
}
})
.print()
.setParallelism(4);
}
private static void broadcastOp(DataStreamSource<Integer> text) {
text.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer integer) throws Exception {
return integer;
}
}).setParallelism(2)
.broadcast()
.print()
.setParallelism(4);
}
private static void rescaleOp(DataStreamSource<Integer> text) {
text.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer integer) throws Exception {
return integer;
}
}).setParallelism(2)
.rescale()
.print()
.setParallelism(4);
}
private static void rebalanceOp(DataStreamSource<Integer> text) {
text.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer integer) throws Exception {
return integer;
}
}).setParallelism(2)
.rebalance()
.print()
.setParallelism(4);
}
private static void shuffleOp(DataStreamSource<Integer> text) {
text.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer integer) throws Exception {
return integer;
}
}).setParallelism(2)
.shuffle()
.print()
.setParallelism(4);
}
}
package com.simoniu.flink.java.stream.transformation;
import org.apache.flink.api.common.functions.Partitioner;
/**
* 自定义分区规则:按照数字的奇偶性进行分区
* Created by simoniu
*/
public class MyPartitionerJava implements Partitioner<Integer> {
@Override
public int partition(Integer key, int numPartitions) {
System.out.println("分区总数:"+numPartitions);
if(key % 2 == 0){
return 0;
}else{
return 1;
}
}
}