DataStreamAPI之DataSource
DataStreamAPI之DataSource
DataStreamAPI之DataSource。
1.DataStream API
DataStream API主要分为3块:DataSource、Transformation、DataSink。
- DataSource是程序的输入数据源。
- Transformation是具体的操作,它对一个或多个输入数据源进行计算处理,例如map、flatMap和filter等操作。
- DataSink是程序的输出,它可以把Transformation处理之后的数据输出到指定的存储介质中。
2.DataStream API之DataSoure
DataSource是程序的输入数据源,Flink提供了大量内置的DataSource,也支持自定义DataSource,不过目前Flink提供的这些已经足够我们正常使用了。
Flink提供的内置输入数据源:包括基于socket、基于Collection 还有就是Flink还提供了一批Connectors,可以实现读取第三方数据源。
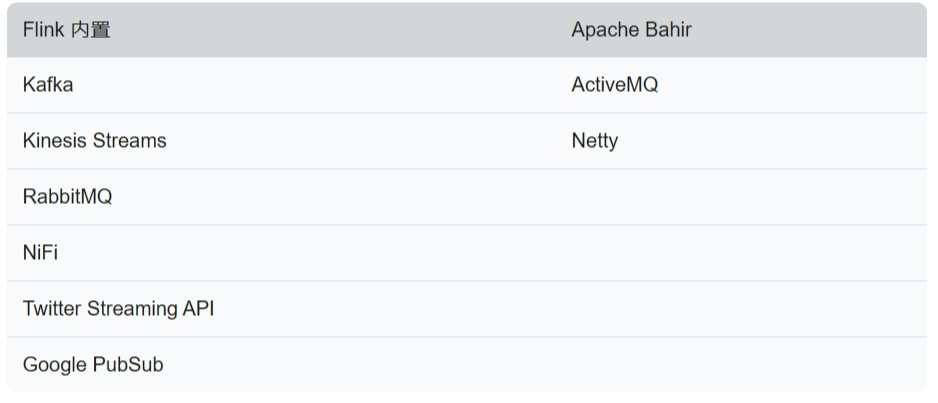
Flink 内置:表示Flink中默认自带的。Apache Bahir:表示需要添加这个依赖包之后才能使用的。实际工作中最常用的就是Kafka。
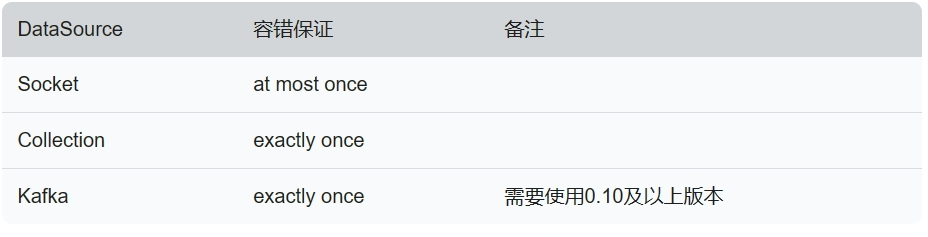
当程序出现错误的时候,Flink的容错机制能恢复并继续运行程序,这种错误包括机器故障、网络故障、程序故障等。针对Flink提供的常用数据源接口,如果程序开启了checkpoint快照机制,Flink可以提供以下容错性保证。
ColllectionDataSource案例:
scala实现:
package com.simoniu.flink.scala.stream.source
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* 基于collection的source的使用
* 注意:这个source的主要应用场景是模拟测试代码流程的时候使用
* Created by simoniu
*/
object StreamCollectionSourceScalaDemo {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
//使用collection集合生成DataStream
val text = env.fromCollection(Array("linux","hadoop","hive","spark","flink"))
text.print().setParallelism(1)
env.execute("StreamCollectionSource")
}
}
运行结果:
linux
hadoop
hive
spark
flink
java实现:
package com.simoniu.flink.java.stream.source;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* 基于collection的source的使用
* Created by simoniu
*/
public class StreamCollectionSourceJavaDemo {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//使用collection集合生成DataStream
DataStreamSource<String> text = env.fromCollection(Arrays.asList("linux","hadoop","hive","spark","flink"));
text.print().setParallelism(1);
env.execute("StreamCollectionSourceJava");
}
}