Flink基础教程
Flink基础教程
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
![]()
1.Flink 简介
在当前的互联网用户,设备,服务等激增的时代下,其产生的数据量已不可同日而语了。各种业务场景都会有着大量的数据产生,如何对这些数据进行有效地处理是很多企业需要考虑的问题。以往我们所熟知的Map Reduce,Storm,Spark等框架可能在某些场景下已经没法完全地满足用户的需求,或者是实现需求所付出的代价,无论是代码量或者架构的复杂程度可能都没法满足预期的需求。新场景的出现催产出新的技术,Flink即为实时流的处理提供了新的选择。Apache Flink就是近些年来在社区中比较活跃的分布式处理框架,加上阿里在中国的推广,相信它在未来的竞争中会更具优势。 Flink的产生背景不过多介绍,感兴趣的可以Google一下。Flink相对简单的编程模型加上其高吞吐、低延迟、高性能以及支持exactly-once语义的特性,让它在工业生产中较为出众。
2.Flink中的数据
Flink中的数据主要分为两类:有界数据流(Bounded streams)和无界数据流(Unbounded streams)。
- 无界数据流就是指有始无终的数据,数据一旦开始生成就会持续不断的产生新的数据,即数据没有时间边界。无界数据流需要持续不断地处理。
- 有界数据流就是指输入的数据有始有终。例如数据可能是一分钟或者一天的交易数据等等。处理这种有界数据流的方式也被称之为批处理。
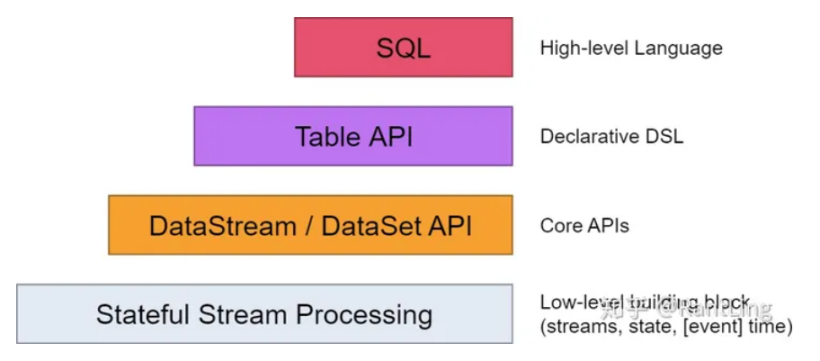
3.Flink中的编程模型
在Flink,编程模型的抽象层级主要分为以下4种,越往下抽象度越低,编程越复杂,灵活度越高。