Flume集成Kafka。
1.Flume集成Kafka
在实际工作中flume和kafka会深度结合使用。主要有以下两个应用场景: 1. flume采集数据,将数据实时写入kafka。 2. flume从kafka中消费数据,保存到hdfs,做数据备份。
下面我们就来看一个综合案例。使用flume采集日志文件中产生的实时数据,写入到kafka中,然后再使用flume从kafka中将数据消费出来,保存到hdfs上面。 那为什么不直接使用flume将采集到的日志数据保存到hdfs上面呢?因为中间使用kafka进行缓冲之后,后面既可以实现实时计算,又可以实现离线数据备份,最终实现离线计算,所以这一份数据就可以实现两种应用需求,使用起来很方便。
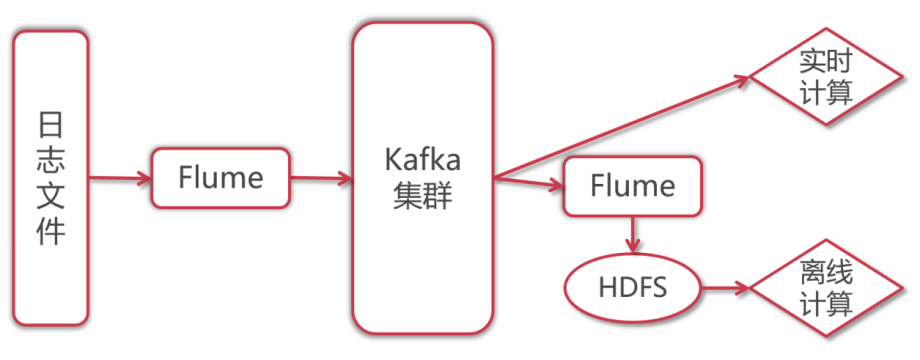
我们来分析一下这个功能如何实现?其实在Flume中,针对Kafka提供的有KafkaSource和KafkaSink。 - KafkaSource是从kafka中读取数据 - KafkaSink是向kafka中写入数据
我们需要配置两个Agent: 第一个Agent负责实时采集日志文件,将采集到的数据写入Kafka中。 第二个Agent负责从Kafka中读取数据,将数据写入HDFS中进行备份。
针对第一个Agent: Source:ExecSource,使用tail -F监控日志文件即可 Channel:MemoryChannel Sink:KafkaSink
针对第二个Agent: Source:KafkaSource Channel:MemoryChannel Sink:HdfsSink
这里面这些组件其实只有KafkaSource和KafkaSink我们之前没有使用过,其它的组件在Flume课程中已经用过了。
配置第一个Agent,文件名为:file-to-kafka.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /data/log/test.log
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
# 指定topic名称
a1.sinks.k1.kafka.topic = test_r2p5
# 指定kafka地址,多个节点地址使用逗号分割
a1.sinks.k1.kafka.bootstrap.servers = master:9092,slave1:9092,slave2:9092
# 一次向kafka中写多少条数据,默认值为100,在这里为了演示方便,改为1
# 在实际工作中这个值具体设置多少需要在传输效率和数据延迟上进行取舍
# 如果kafka后面的实时计算程序对数据的要求是低延迟,那么这个值小一点比较好
# 如果kafka后面的实时计算程序对数据延迟没什么要求,那么就考虑传输性能,一次多传输一些数据,这样吞吐量会有所提升
# 建议这个值的大小和ExecSource每秒钟采集的数据量大致相等,这样不会频繁向kafka中写数据,并且对kafka后面的实时计算程序也没有很大影响,1秒的数据延迟一般是可以接收的
a1.sinks.k1.kafka.flumeBatchSize = 1
a1.sinks.k1.kafka.producer.acks = 1
# 一个Batch被创建之后,最多过多久,不管这个Batch有没有写满,都必须发送出去
# linger.ms和flumeBatchSize,哪个先满足先按哪个规则执行,这个值默认是0,在这设置为1表示每隔1毫秒就将这一个Batch中的数据发送出去
a1.sinks.k1.kafka.producer.linger.ms = 1
# 指定数据传输时的压缩格式,对数据进行压缩,提高传输效率
a1.sinks.k1.kafka.producer.compression.type = snappy
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置第二个Agent,文件名为:kafka-to-hdfs.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
# 一次性向channel中写入的最大数据量,在这为了演示方便,设置为1
# 这个参数的值不要大于MemoryChannel中transactionCapacity的值
a1.sources.r1.batchSize = 1
# 最大多长时间向channel写一次数据
a1.sources.r1.batchDurationMillis = 2000
# kafka地址
a1.sources.r1.kafka.bootstrap.servers = master:9092,slave1:9092,slave2:9092
# topic名称,可以指定一个或者多个,多个topic之间使用逗号隔开
# 也可以使用正则表达式指定一个topic名称规则
a1.sources.r1.kafka.topics = test_r2p5
# 指定消费者组id
a1.sources.r1.kafka.consumer.group.id = flume-con1
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://master:9000/kafkaout
a1.sinks.k1.hdfs.filePrefix = data-
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
在master机器的flume目录下复制两个目录:
[root@master kafka]# cd $FLUME_HOME
[root@master flume]# cp -r conf conf-file-to-kafka
[root@master flume]# cp -r conf conf-kafka-to-hdfs
修改 conf_file_to_kafka和conf_kafka_to_hdfs中log4j的配置
#conf_file_to_kafka目录下的log4j的配置
flume.root.logger=ERROR,LOGFILE
flume.log.file=flume-file-to-kafka.log
#conf_kafka_to_hdfs中log4j的配置
flume.root.logger=ERROR,LOGFILE
flume.log.file=flume-kafka-to-hdfs.log
把上面配置的两个Agent的配置文件复制到这两个目录下。
下来准备启动这两个Flume Agent,在启动之前要确保zookeeper集群、kafka集群和Hadoop集群是正常运行的,以及Kafka中的topic需要提前创建好。
创建topic。
[root@master kafka]# bin/kafka-topics.sh --create --zookeeper master:2181 --partitions 5 --replication-factor 2 --topic test_r2p5
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic test_r2p5.
先启动第二个Agent,再启动第一个Agent。
#启动第二个Agent
[root@master flume]# cd $FLUME_HOME
[root@master flume]# bin/flume-ng agent --name a1 --conf conf-kafka-to-hdfs --conf-file conf-kafka-to-hdfs/kafka-to-hdfs.conf
#启动第一个Agent
[root@master flume]# cd $FLUME_HOME
[root@master flume]# bin/flume-ng agent --name a1 --conf conf-file-to-kafka --conf-file conf-file-to-kafka/file-to-kafka.conf
模拟产生日志数据。
[root@master ~]# cd /data/log
[root@master log]# echo welcome to kafka >> /data/log/test.log
到HDFS上查看数据,验证结果:
[root@master log]# hdfs dfs -cat /kafkaout/data-.1699196248822.tmp
2023-11-05 22:59:37,420 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
welcome to kafka
welcome to kafka
welcome to kafka