Producer和Consumer扩展。
1.Producer扩展
Producer默认是随机将数据发送到topic的不同分区中,也可以根据用户设置的算法来根据消息的key来计算输入到哪个partition里面,此时需要通过partitioner来控制,这个知道就行了,通常在实际工作中一般在向kafka中生产数据的都是不带key的,只有数据内容,所以一般都是使用随机的方式发送数据。
producer的数据通讯方式有同步发送和异步发送两种。
- 同步发送:生产者发出数据后,等接收方发回响应以后再发送下个数据的通讯方式。
- 异步异步:生产者发出数据后,不等接收方发回响应,接着发送下个数据的通讯方式。
具体的数据通讯策略是由acks参数控制的,其取值含义如下:
- acks默认为1,表示需要Leader节点回复收到消息,这样生产者才会发送下一条数据。
- acks:all,表示需要所有Leader+副本节点回复收到消息(acks=-1),这样生产者才会发送下一条数据。
- acks:0,表示不需要任何节点回复,生产者会继续发送下一条数据。
看一下这个图:
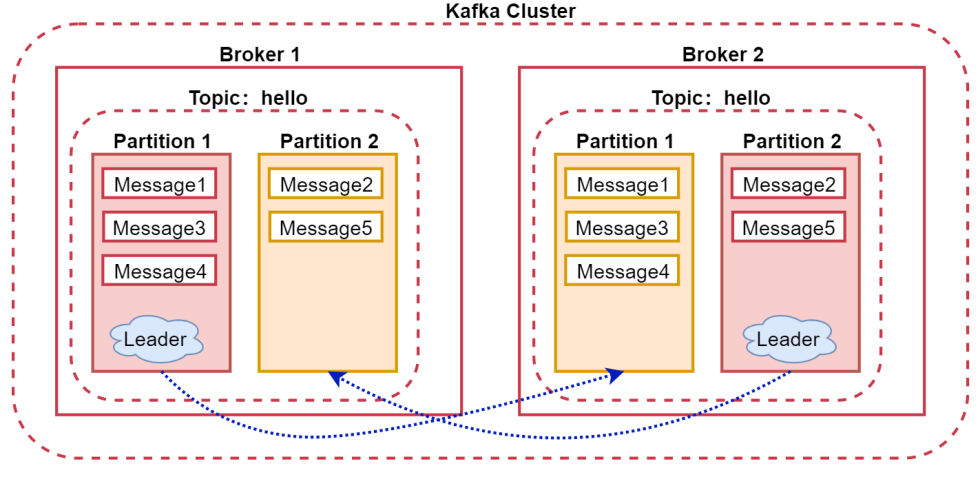
针对这块在面试的时候会有一个面试题:Kafka如何保证数据不丢?
其实就是通过acks机制保证的,如果设置acks为all,则可以保证数据不丢,因为此时把数据发送给kafka之后,会等待对应partition所在的所有leader和副本节点都确认收到消息之后才会认为数据发送成功了,所以在这种策略下,只要把数据发送给kafka之后就不会丢了。
如果acks设置为1,则当我们把数据发送给partition之后,partition的leader节点也确认收到了,但是leader回复完确认消息之后,leader对应的节点就宕机了,副本partition还没来得及将数据同步过去,所以会存在丢失的可能性。不过如果宕机的是副本partition所在的节点,则数据是不会丢的。
如果acks设置为0的话就表示是顺其自然了,只管发送,不管kafka有没有收到,这种情况表示对数据丢不丢都无所谓了。
2.Consumer扩展
在消费者中还有一个消费者组的概念。每个consumer属于一个消费者组,通过group.id指定消费者组。
那组内消费和组间消费有什么区别吗?
- 组内:消费者组内的所有消费者消费同一份数据;
- 组间:多个消费者组消费相同的数据,互不影响。
注意:在同一个消费者组中,一个partition同时只能有一个消费者消费数据,如果消费者的个数小于分区的个数,一个消费者会消费多个分区的数据。如果消费者的个数大于分区的个数,则多余的消费者不消费数据。
来看下面这个图,加深一下理解:
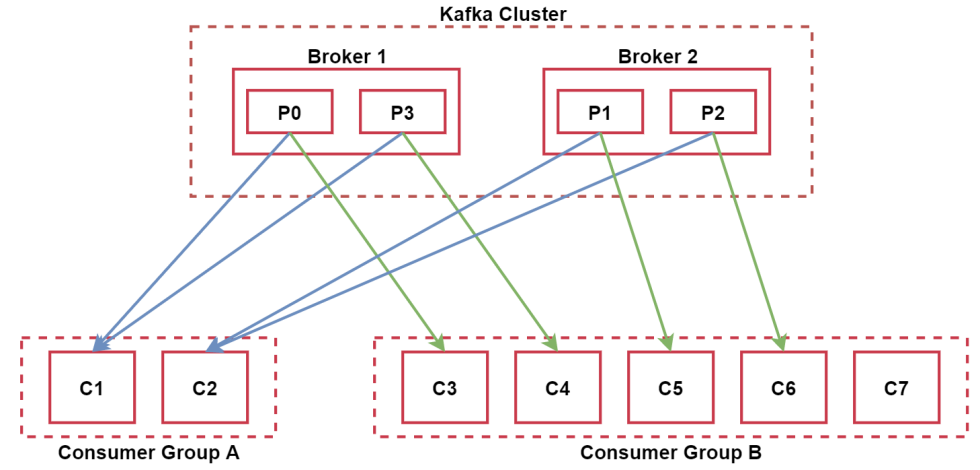
Kafka集群有两个节点,Broker1和Broker2。集群内有一个topic,这个topic有4个分区,P0,P1,P2,P3
下面有两个消费者组:Consumer Group A和Consumer Group B。其中Consumer Group A中有两个消费者 C1和C2,由于这个topic有4个分区,所以,C1负责消费两个分区的数据,C2负责消费两个分区的数据,这个属于组内消费。
Consumer Group B有5个消费者,C3~C7,其中C3,C4,C5,C6分别消费一个分区的数据,而C7就是多余出来的了,因为现在这个消费者组内的消费者的数量比对应的topic的分区数量还多,但是一个分区同时只能被一个消费者消费,所以就会有一个消费者处于空闲状态。这个也属于组内消费
Consumer Group A和Consumer Group B这两个消费者组属于组间消费,互不影响。