load和save操作
load和save操作
load和save操作。
1.load和save
对于Spark SQL的DataFrame来说,无论是从什么数据源创建出来的DataFrame,都有一些共同的load和save操作。
- load操作主要用于加载数据,创建出DataFrame;
- save操作,主要用于将DataFrame中的数据保存到文件中。
前面操作json格式的数据的时候好像没有使用load方法,而是直接使用的json方法,这是什么特殊用法吗?我们通过查看json方法的源码会发现,它底层调用的就是format和load方法。
def json(paths: String*): DataFrame = format("json").load(paths : _*)
如果不指定format,则默认读取的数据源格式是parquet,也可以手动指定数据源格式。Spark SQL内置了一些常见的数据源类型,比如json, parquet, jdbc, orc, csv, text等等。通过这个功能,就可以在不同类型的数据源之间进行转换了。
1).scala代码实现
package com.simoniu.scalademo.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* 需求:load和save的使用
* Created by simoniu
*/
object LoadAndSaveScalaDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local")
//创建SparkSession对象,里面包含SparkContext和SqlContext
val sparkSession = SparkSession.builder()
.appName("LoadAndSaveOpScala")
.config(conf)
.getOrCreate()
//读取数据
val stuDf = sparkSession.read
.format("json")
.load("D:\\uploadFiles\\students.json")
//保存数据
stuDf.select("name", "age", "gender")
.write
.format("csv")
.save("hdfs://master:9000/out-save001")
sparkSession.stop()
}
}
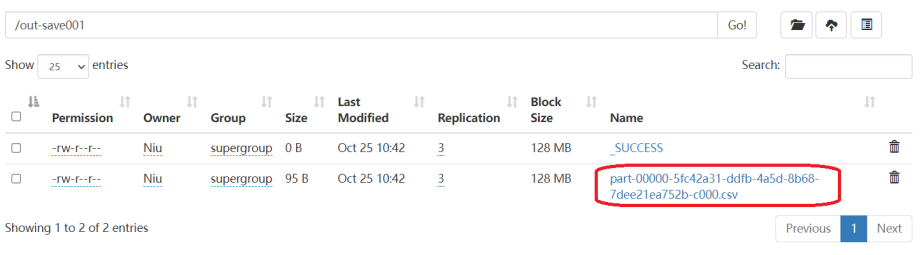
我们在HDFS的WEB-UI上查看保存到HDFS的csv文件。
2).java实现
package com.simoniu.sparkdemo.javademo.sql;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
/**
* 需求:load和save的使用
* Created by simoniu
*/
public class LoadAndSaveJavaDemo {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
//创建SparkSession对象,里面包含SparkContext和SqlContext
SparkSession sparkSession = SparkSession.builder()
.appName("LoadAndSaveOpJava")
.config(conf)
.getOrCreate();
//读取数据
Dataset<Row> stuDf = sparkSession.read()
.format("json")
.load("D:\\uploadFiles\\students.json");
//保存数据
stuDf.select("name","age","gender")
.write()
.format("csv")
.save("hdfs://master:9000/out-save002");
sparkSession.stop();
}
}