算子优化。
1.map vs mapPartitions
map与mapPartitions的区别:
- map 操作:对 RDD 中的每个元素进行操作,一次处理一条数据。
- mapPartitions 操作:对 RDD 中每个 partition 进行操作,一次处理一个分区的数据。
一般情况下,mapPartitions 的性能更高;初始化操作、数据库链接等操作适合使用 mapPartitions 操作。 这是因为:假设需要将 RDD 中的每个元素写入数据库中,这时候就应该把创建数据库链接的操作放置在 mapPartitions 中,创建数据库链接这个操作本身就是个比较耗时的,如果该操作放在 map 中执行,将会频繁执行,比较耗时且影响数据库的稳定性。
mapPartitions案例:
1).scala代码实现如下
package com.simoniu.scalademo
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ArrayBuffer
/**
* 需求:mapPartitons的使用
* Created by simoniu
*/
object MapPartitionsScalaDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("MapPartitionsOpScala")
.setMaster("local")
val sc = new SparkContext(conf)
//设置分区数量为2
val dataRDD = sc.parallelize(Array(1, 2, 3, 4, 5, 6, 7, 8, 9), 2)
//map算子一次处理一条数据
/*val sum = dataRDD.map(item=>{
println("==============")
item * 2
}).reduce( _ + _)*/
//mapPartitions算子一次处理一个分区的数据
val sum = dataRDD.mapPartitions(it => {
//建议针对初始化链接之类的操作,使用mapPartitions,放在mapPartitions内部
//例如:创建数据库链接,使用mapPartitions可以减少链接创建的次数,提高性能
//注意:创建数据库链接的代码建议放在次数,不要放在Driver端或者it.foreach内部
//数据库链接放在Driver端会导致链接无法序列化,无法传递到对应的task中执行,所以算子在执行的时候会报错
//数据库链接放在it.foreach()内部还是会创建多个链接,和使用map算子的效果是一样的
println("==================")
val result = new ArrayBuffer[Int]()
//这个foreach是调用的scala里面的函数
it.foreach(item => {
result.+=(item * 2)
})
//关闭数据库链接
result.toIterator
}).reduce(_ + _)
println("sum:" + sum)
sc.stop()
}
}
2).Java代码实现
package com.simoniu.sparkdemo.javademo;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
/**
* 需求:mapPartitons的使用
* Created by simoniu
*/
public class MapPartitionsJavaDemo {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("MapPartitionsOpJava")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9), 2);
Integer sum = dataRDD.mapPartitions(new FlatMapFunction<Iterator<Integer>, Integer>() {
@Override
public Iterator<Integer> call(Iterator<Integer> it) throws Exception {
//数据库链接的代码需要放在这个位置
System.out.println("=========数据库链接的代码=============");
ArrayList<Integer> list = new ArrayList<>();
while (it.hasNext()) {
list.add(it.next() * 2);
}
//关闭数据库链接
return list.iterator();
}
}).reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
System.out.println("sum:" + sum);
}
}
2.foreach vs foreachPartition
foreach 与 foreachPartition的区别:
- foreach:一次处理一条数据
- foreachPartition:一次处理一个分区的数据
foreachPartition的特性和mapPartitions 的特性是一样的,唯一的区别就是mapPartitions 是 transformation 操作(不会立即执行),foreachPartition是 action 操作(会立即执行)。
foreachPartition案例。
1).scala实现
package com.simoniu.scalademo
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:foreachPartition的使用
* Created by simoniu
*/
object ForeachPartitionScalaDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ForeachPartitionOpScala")
.setMaster("local")
val sc = new SparkContext(conf)
//设置分区数量为2
val dataRDD = sc.parallelize(Array(1, 2, 3, 4, 5, 6, 7, 8, 9), 2)
//foreachPartition:一次处理一个分区的数据,作用和mapPartitions类似
//唯一的区是mapPartitions是transformation算子,foreachPartition是action算子
dataRDD.foreachPartition(it => {
//在此处获取数据库链接
println("======获取数据库链接=========")
it.foreach(item => {
//在这里使用数据库链接
println("======使用数据库链接=========")
println(item)
})
//关闭数据库链接
println("======释放数据库链接=========")
})
sc.stop()
}
}
2).Java代码实现
package com.simoniu.sparkdemo.javademo;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import java.util.Arrays;
import java.util.Iterator;
/**
* 需求:foreachPartition的使用
* Created by simoniu
*/
public class ForeachPartitionJavaDemo {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("ForeachPartitionOpJava")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9), 2);
dataRDD.foreachPartition(new VoidFunction<Iterator<Integer>>() {
@Override
public void call(Iterator<Integer> it) throws Exception {
//在此处获取数据库链接
System.out.println("======获取数据库链接=======");
while (it.hasNext()) {
//在这里使用数据库链接
System.out.println(it.next());
}
//关闭数据库链接
}
});
sc.stop();
}
}
3.repartition的使用
对RDD进行重分区,repartition主要有两个应用场景:
- 可以调整RDD的并行度 针对个别RDD,如果感觉分区数量不合适,想要调整,可以通过repartition进行调整,分区调整了之后,对应的并行度也就可以调整了。
- 可以解决RDD中数据倾斜的问题 如果RDD中不同分区之间的数据出现了数据倾斜,可以通过repartition实现数据重新分发,可以均匀分发到不同分区中。
repartition案例。
1).scala实现
package com.simoniu.scalademo
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:repartition的使用
* Created by simoniu
*/
object RepartitionScalaDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("RepartitionOpScala")
.setMaster("local")
val sc = new SparkContext(conf)
//设置分区数量为2
val dataRDD = sc.parallelize(Array(1, 2, 3, 4, 5, 6, 7, 8, 9), 2)
//重新设置RDD的分区数量为3,这个操作会产生shuffle
//也可以解决RDD中数据倾斜的问题
dataRDD.repartition(3)
.foreachPartition(it => {
println("=========")
it.foreach(println(_))
})
//通过repartition可以控制输出数据产生的文件个数
dataRDD.saveAsTextFile("hdfs://master:9000/repartition-demo")
dataRDD.repartition(1).saveAsTextFile("hdfs://master:9000/repartition-demo2")
sc.stop()
}
}
我们在HDFS的WebUI上观察调整分区的效果。
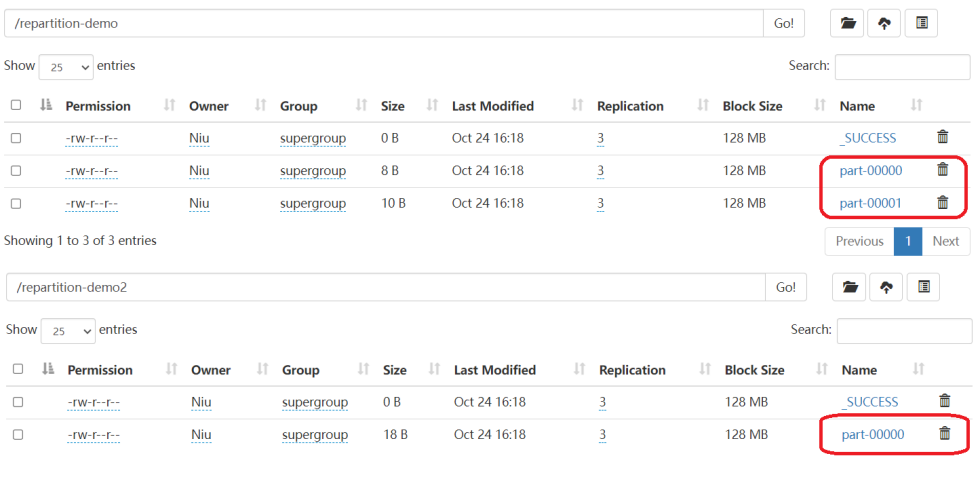
2).Java实现
package com.simoniu.sparkdemo.javademo;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import java.util.Arrays;
import java.util.Iterator;
/**
* 需求:repartition的使用
* Created by simoniu
*/
public class RepartitionJavaDemo {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("RepartitionOpJava")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9), 2);
dataRDD.repartition(3)
.foreachPartition(new VoidFunction<Iterator<Integer>>() {
@Override
public void call(Iterator<Integer> it) throws Exception {
System.out.println("==============");
while (it.hasNext()) {
System.out.println(it.next());
}
}
});
dataRDD.saveAsTextFile("hdfs://master:9000/repartition-demo");
dataRDD.repartition(1).saveAsTextFile("hdfs://master:9000/repartition-demo2");
sc.stop();
}
}
4.reduceByKey和groupByKey的区别
在实现分组聚合功能时这两个算子有什么区别?我们来看下面这这两行代码。
val counts = wordCountRDD.reduceByKey(_ + _)
val counts = wordCountRDD.groupByKey().map(wc => (wc._1, wc._2.sum))
这两行代码的最终效果是一样的,都是对wordCountRDD中每个单词出现的次数进行聚合统计,那么这两种方式在原理层面有什么区别吗?
首先这两个算子在执行的时候都会产生shuffle,但是: 1. 当采用reduceByKey时,数据在进行shuffle之前会先进行局部聚合。 2. 当使用groupByKey时,数据在shuffle之前不会进行局部聚合,会原样进行shuffle。
这样的话reduceByKey就减少了shuffle的数据传送,所以效率会高一些。
下面来看这个图,加深一下理解:
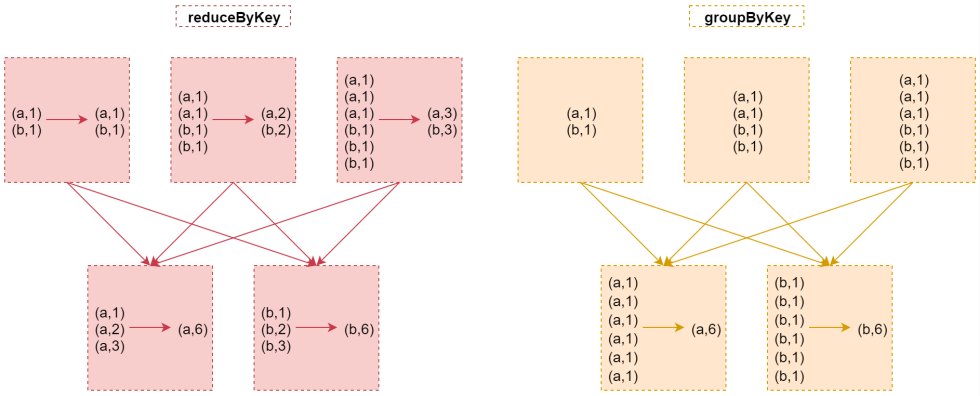
从上图我们可以看出来reduceByKey在shuffle之前会先对数据进行局部聚合,而groupByKey不会,所以在实现分组聚合的需求中,reduceByKey性能略胜一筹。