通常Spark集群的资源并不一定会被充分利用到,所以要尽量设置合理的并行度,来充分地利用集群的资源,这样才能提高Spark程序的性能。
1.提高并行度
上小节我们我们探讨了Spark程序的性能优化,其中四个方案。这里我们单独探讨提高并行度的优化方案。
我来举个例子,我们在spark-submit脚本中给任务设置了5 个executor,每个executor,设置了2个cpu core。
spark-submit \
--master yarn \
--deploy-mode cluster \
--executor-memory 1G \
--num-executors 5 \
--executor-cores 2 \
.....
此时,如果我在代码中设置了默认并行度为5。
conf.set("spark.default.parallelism","5")
但是需要注意的是,我们前面在spark-submit脚本中设置了5个executor,每个executor 2个cpu core,所以这个时候spark其实会向yarn集群申请10个cpu core,但是我们在代码中设置了默认并行度为5,只会产生5个task,一个task使用一个cpu core,那也就意味着有5个cpu core是空闲的,这样申请的资源就浪费了一半。
其实最好的情况,就是每个cpu core都不闲着,一直在运行,这样可以达到资源的最大使用率,其实让一个cpu core运行一个task都是有点浪费的,官方也建议让每个cpu core运行2~3个task,这样可以充分利用CPU的性能。官方推荐的方案是,给每个cpu分配 2~3个task是比较合理的,可以充分利用CPU资源,发挥它最大的价值。
通过一个实际案例演示。
1).scala实现如下:
package com.simoniu.scalademo
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:设置并行度
* 1:可以在textFile或者parallelize等方法的第二个参数中设置并行度
* 2:或者通过spark.default.parallelism参数统一设置并行度
* Created by simoniu
*/
object MoreParallelismScalaDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("MoreParallelismScala")
//设置全局并行度
conf.set("spark.default.parallelism", "5")
val sc = new SparkContext(conf)
val dataRDD = sc.parallelize(Array("hello", "linux", "hello", "java", "hehe", "hello", "hadoop", "hello", "spark", "hehe"))
dataRDD.map((_, 1))
.reduceByKey(_ + _)
.foreach(println(_))
sc.stop()
}
}
2).Java实现如下:
package com.simoniu.sparkdemo.javademo;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
/**
* 需求:提高并行度
* Created by simoniu
*/
public class MoreParallelismJavaDemo {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("MoreParallelismJava");
//设置全局并行度
conf.set("spark.default.parallelism", "5");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> dataRDD = sc.parallelize(Arrays.asList("hello", "you", "hello", "me", "hehe", "hello", "you", "hello", "me", "hehe"));
dataRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
}).foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tup) throws Exception {
System.out.println(tup);
}
});
sc.stop();
}
}
对代码编译打包,spark-submit脚本内容如下:
moreParallelismJob.sh
spark-submit \
--class com.simoniu.scalademo.MoreParallelismScalaDemo \
--master yarn \
--deploy-mode cluster \
--executor-memory 1G \
--num-executors 5 \
--executor-cores 2 \
sparksubmitdemo.jar
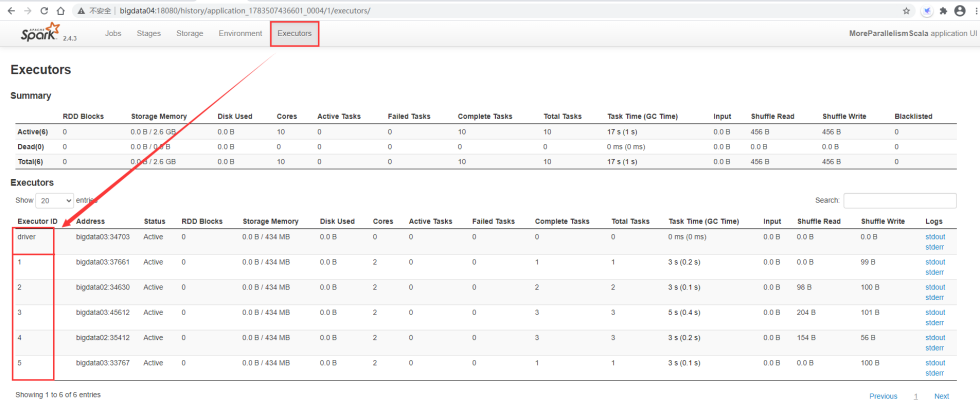
任务提交到集群运行之后,查看spark的任务界面,先看executors,这里显示了5个executor进程和1个driver进程。
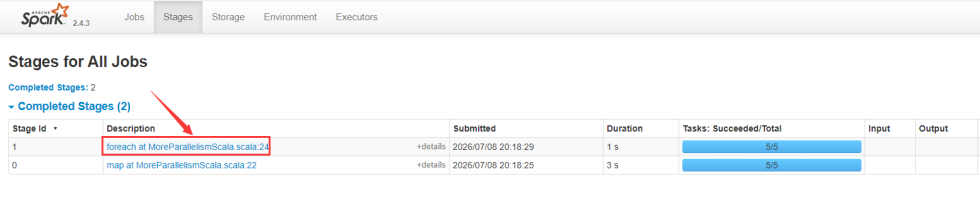
然后去看satges界面,两个Stage都是5个task并行执行,这5个task会使用5个cpu,但是我们给这个任务申请了10个cpu,所以就有5个是空闲的了。
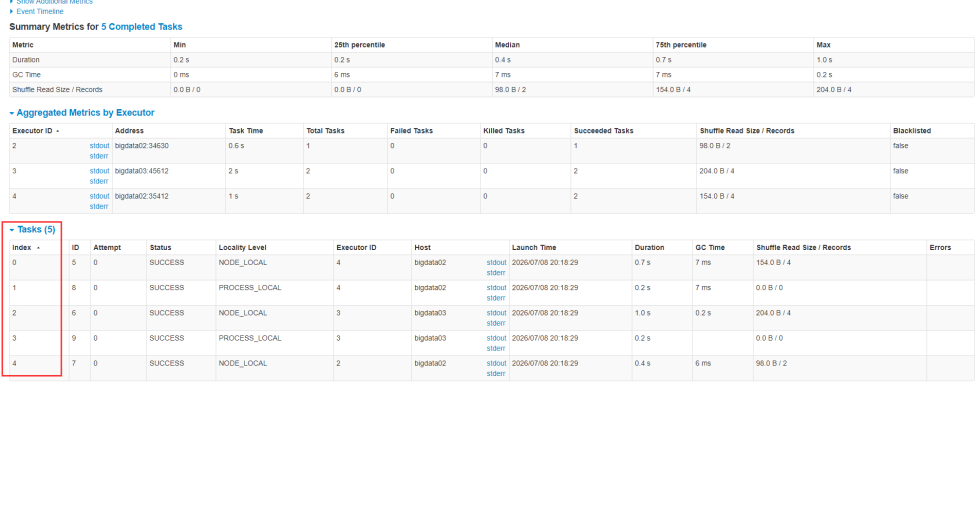
点击某一个Stage进去查看详细的task信息。可以看到确实只有5个task。
如果想要最大限度利用CPU的性能,至少将spark.default.parallelism的值设置为10,这样可以实现一个cpu运行一个task,其实官方推荐是设置为20或者30。
其实这个参数也可以在spark-submit脚本中动态设置,通过--conf参数设置,这样就比较灵活了。 注意:此时需要将代码中设置spark.default.parallelism的配置注释掉。重新打包上传!
//设置全局并行度
//conf.set("spark.default.parallelism", "5")
再封装一个脚本。
moreParallelismJob2.sh
spark-submit \
--class com.simoniu.scalademo.MoreParallelismScalaDemo \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--num-executors 5 \
--executor-cores 2 \
--conf "spark.default.parallelism=10" \
sparksubmitdemo.jar
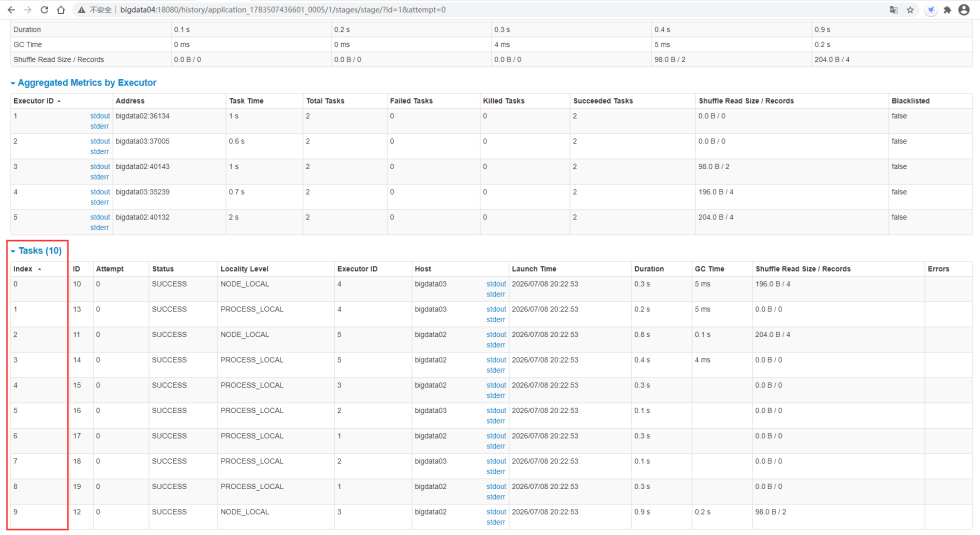
再次执行结束后再来查看spark的任务界面,可以看到此时有10 个task并行执行。

点击某一个Stage进去查看详细的task信息,点进来之后可以看到有10个task。
这就是并行度相关的设置,接下来我们来看一个图,加深一下理解。
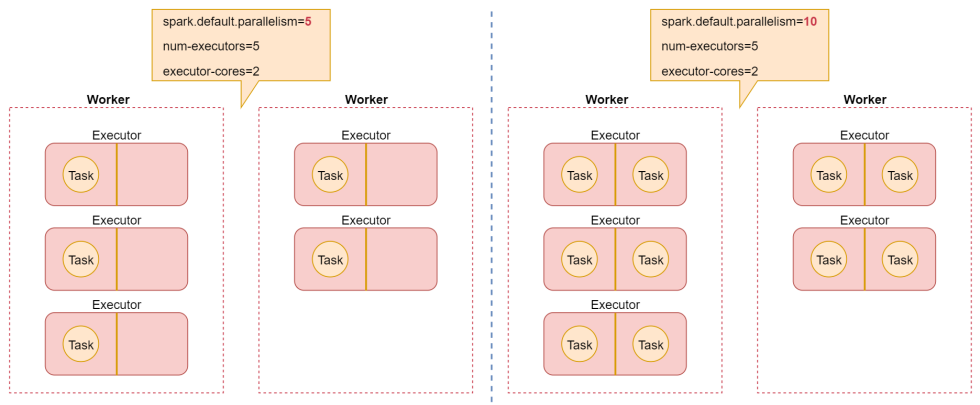
最后我们来分析总结一下spark-submit脚本中经常配置的一些参数。
--name mySparkJobName:指定任务名称
--class com.imooc.scala.xxxxx :指定入口类
--master yarn :指定集群地址,on yarn模式指定yarn
--deploy-mode cluster :client代表yarn-client,cluster代表yarn-cluster
--executor-memory 1G :executor进程的内存大小,实际工作中设置2~4G即可
--num-executors 2 :分配多少个executor进程
--executor-cores 2 : 一个executor进程分配多少个cpu core
--driver-cores 1 :driver进程分配多少cpu core,默认为1即可
--driver-memory 1G:driver进程的内存,如果需要使用类似于collect之类的action算子向driver端拉取数据,则这里可以设置大一些
--jars fastjson.jar,abc.jar 在这里可以设置job依赖的第三方jar包【不建议把第三方依赖jar包整体打包进saprk的job中,那样会导致任务jar包过大,并且也不方便统一管理依赖jar包的版本,这里的jar包路径可以指定本地磁盘路径,或者是hdfs路径,建议使用hdfs路径,因为spark在提交任务的时候会把本地磁盘的依赖jar包也上传到hdfs的一个临时目录中,如果在这里本来指定的就是hdfs的路径,那么spark在提交任务的时候就不会重复提交依赖的这个jar包了,这样其实可以提高任务提交的效率,并且这样可以方便统一管理第三方依赖jar包,所有人都统一使用hdfs中的共享的这些第三方jar包,这样版本就统一了,所以我们可以在hdfs中创建一个类似于commonLib的目录,统一存放第三方依赖的jar包,如果一个Spark job需要依赖多个jar包,在这里可以一次性指定多个,多个jar包之间通过逗号隔开即可】
--conf "spark.default.parallelism=10":可以动态指定一些spark任务的参数,指定多个参数可以通过多个--conf来指定,或者在一个--conf后面的双引号中指定多个,多个参数之间用空格隔开即可
需要注意一点:针对--num-executors 和--executor-cores 的设置,这两种方式设置有什么区别:
第一种方式:
--num-executors 2
--executor-cores 1
第二种方式:
--num-executors 1
--executor-cores 2
第一种方法:多executor模式 由于每个executor只分配了一个cpu core,我们将无法利用在同一个JVM中运行多个任务的优点。 我们假设这两个executor是在两个节点中启动的,那么针对广播变量这种操作,将在两个节点的中都复制1份,最终会复制两份
第二种方法:多core模式 此时一个executor中会有2个cpu core,这样可以利用同一个JVM中运行多个任务的优点,并且针对广播变量的这种操作,只会在这个executor对应的节点中复制1份即可。 那是不是我可以给一个executor分配很多的cpu core,也不是的,因为一个executor的内存大小是固定的,如果在里面运行过多的task可能会导致内存不够用,所以这块一般在工作中我们会给一个executor分配 2~4G内存,对应的分配 2~4个cpu core。