Spark Job的三种提交模式。
1.宽依赖和窄依赖
- 窄依赖(Narrow Dependency):指父RDD的每个分区只被子RDD的一个分区所使用,例如map、filter等这些算子。
- 宽依赖(Shuffle Dependency):父RDD的每个分区都可能被子RDD的多个分区使用,例如groupByKey、reduceByKey,sortBykey等算子,这些算子其实都会产生shuffle操作。
下面来看图具体分析一个案例,以单词计数案例来分析。
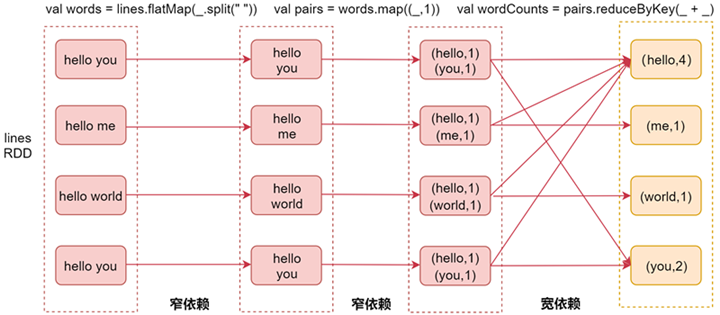
最左侧是linesRDD,这个表示我们通过textFile读取文件中的数据之后获取的RDD。接着是我们使用flatMap算子,对每一行数据按照空格切开,然后可以获取到第二个RDD,这个RDD中包含的是切开的每一个单词。
在这里这两个RDD就属于一个窄依赖,因为父RDD的每个分区只被子RDD的一个分区所使用,也就是说他们的分区是一对一的,这样就不需要经过shuffle了。接着是使用map算子,将每一个单词转换成(单词,1)这种形式, 此时这两个RDD也是一个窄依赖的关系,父RDD的分区和子RDD的分区也是一对一的。
最后我们会调用reduceByKey算子,此时会对相同key的数据进行分组,分到一个分区里面,并且进行聚合操作,此时父RDD的每个分区都可能被子RDD的多个分区使用,那这两个RDD就属于宽依赖了。
2.Stage
Spark job是根据action算子触发的,遇到action算子就会起一个job,Spark Job会被划分为多个Stage,每一个Stage是由一组并行的Task组成的。
注意:stage的划分依据就是看是否产生了shuflle(即宽依赖),遇到一个shuffle操作就划分为前后两个stage stage是由一组并行的task组成,stage会将一批task用TaskSet来封装,提交给TaskScheduler进行分配,最后发送到Executor执行。
通过下面这张图来具体分析一下:
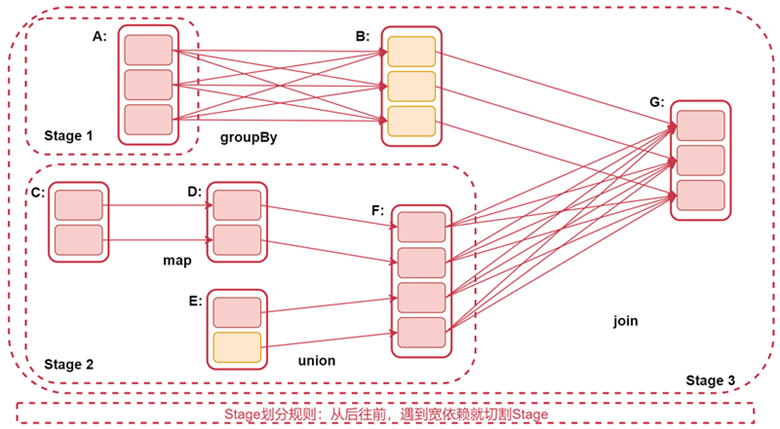
注意:Stage的划分规则:从后往前,遇到宽依赖就划分Stage。Stage划分是从后往前划分,但是stage执行时从前往后的,这就是为什么后面先切割的stage为什么编号是3的原因。
3.Spark Job的三种提交模式
- 第一种,standalone模式,基于Spark自己的standalone集群。 指定–master spark://bigdata01:7077
- 第二种,是基于YARN的client模式。 指定–master yarn --deploy-mode client 这种方式主要用于测试,查看日志方便一些。
- 第三种,是基于YARN的cluster模式。(推荐) 指定–master yarn --deploy-mode cluster 这种方式driver进程运行在集群中的某一台机器上。
看下面这个图,加深一下理解:
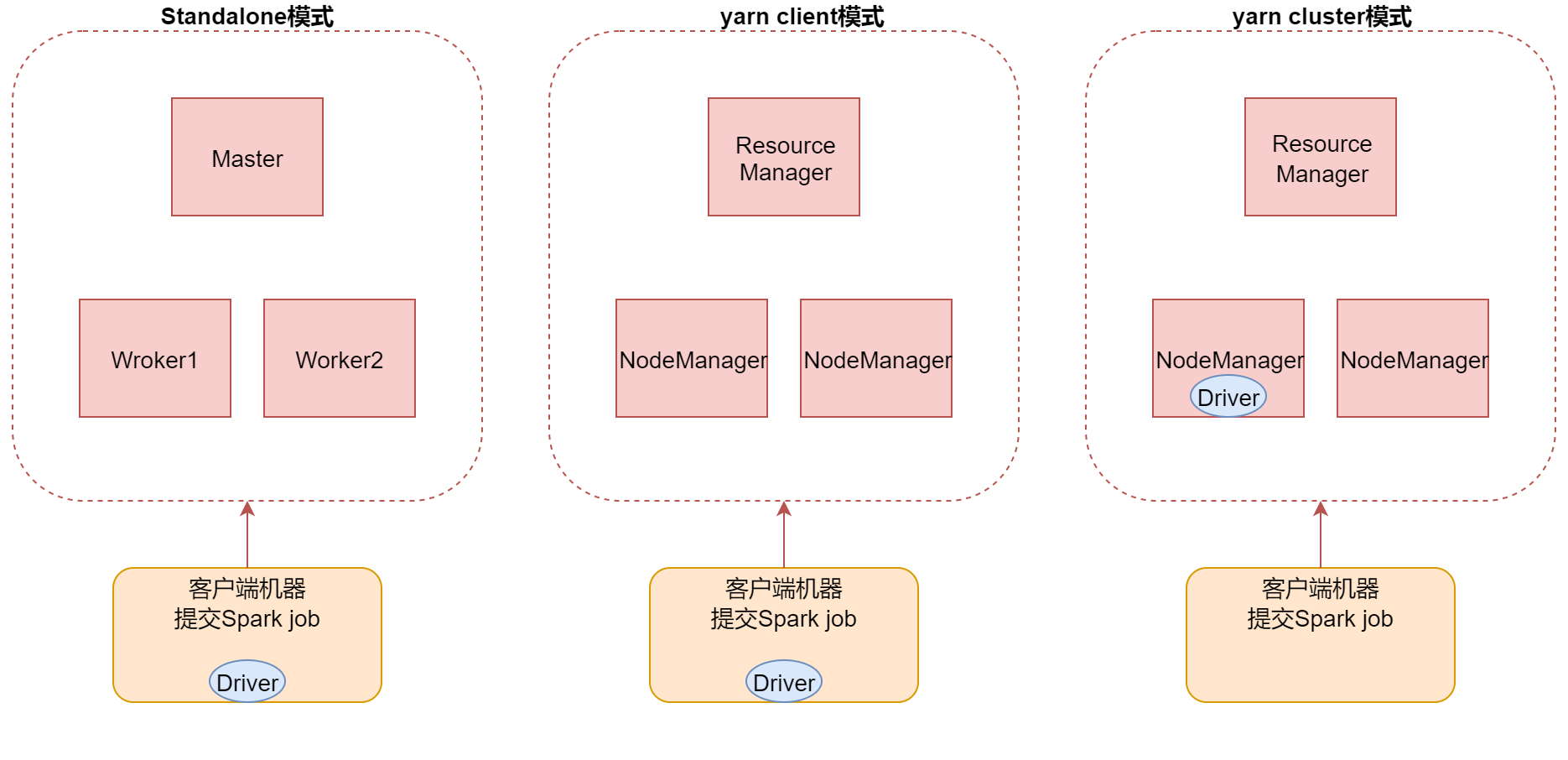
左边是standalone模式,中间的值yarn client模式,由于是on yarn模式,所以里面是yarn集群的进程,此时driver进程就在提交spark任务的客户端机器上了。