MapReduce任务日志查看
MapReduce任务日志查看
MapReduce任务日志查看。
1.如何查看MapReduce任务日志
在上小节案例中,我们无法查看MapReduce任务日志。我们可以在自定义mapper类的map函数中增加一个输出,将k1,v1的值打印出来。
WordCountJob.java 改写如下:
/**
* 创建自定义的reducer类
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
/**
* 针对v2s的数据进行累加求和 并且最终把数据转化为k3,v3写出去
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context)
throws IOException, InterruptedException {
// 创建一个sum变量,保存v2s的和
long sum = 0L;
for (LongWritable v2 : v2s) {
//输出k2,v2的值
System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
}
// 组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
// 把结果写出去
context.write(k3,v3);
}
}
/**
* 创建自定义mapper类
*/
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
/**
* 需要实现map函数
* 这个map函数就是可以接收k1,v1, 产生k2,v2
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
// k1代表的是每一行的行首偏移量,v1代表的是每一行内容
// 对获取到的每一行数据进行切割,把单词切割出来
//输出k1,v1的值
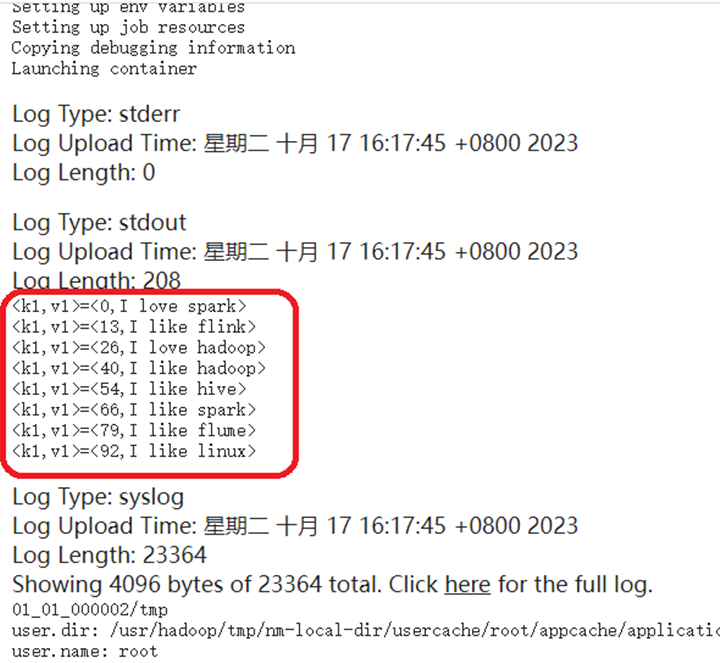
System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
String[] words = v1.toString().split(" ");
// 迭代切割出来的单词数据
for (String word:words) {
// 把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
// 把<k2,v2>写出去
context.write(k2,v2);
}
}
}
下来需要开启日志聚合功能。开启日志聚合功能需要修改yarn-site.xml的配置,增加yarn.log-aggregation-enable和yarn.log.server.url这两个参数。
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs/</value>
</property>
注意:修改这个配置想要生效需要重启集群。把修改后的yarn-site.xml分发到slave1和slave2。
[root@master examples]# scp -rq yarn-site.xml slave1:/usr/local/hadoop3.1/etc/hadoop/
[root@master examples]# scp -rq yarn-site.xml slave2:/usr/local/hadoop3.1/etc/hadoop/
在master主机启动hadoop集群后分别在master,slave1和slave2上启动historyserver。
cd $HADOOP_HOME
bin/mapred --daemon start historyserver
master主机进程如下:
[root@master examples]# jps
18947 Jps
125493 ResourceManager
126791 JobHistoryServer
124812 SecondaryNameNode
124191 NameNode
从节点主机进程如下:
[root@slave1 hadoop3.1]# jps
123573 Jps
96683 DataNode
123275 JobHistoryServer
97567 NodeManager
项目重新打包,重新再提交mapreduce任务。
[root@master download_temp]# hadoop jar wordcount.jar com.simoniu.mapreduce.WordCountJob /hello/input /hello/output
此时再进入yarn的8088界面,点击任务对应的history链接就可以打开了。
此时,点击对应map和reduce后面的链接就可以点进去查看日志信息了,点击map后面的数字1,可以进入如下界面.

点击这个界面中的logs文字链接,可以查看详细的日志信息。