MapReduce原理分析。
1.分布式计算
传统web应用之所以慢,这个慢主要是由于两个方面造成的。
- 一个是磁盘io(会进行磁盘读写操作)
- 一个是网络io(网络传输)
两个里面其实最耗时的还是网络IO,我们平时在两台电脑之间传输一个几十G的文件也需要很长时间的,但是如果是使用U盘拷贝就很快了,所以可以看出来主要耗时的地方是在网络IO上面。我们把这种计算方式我们称之为移动数据。
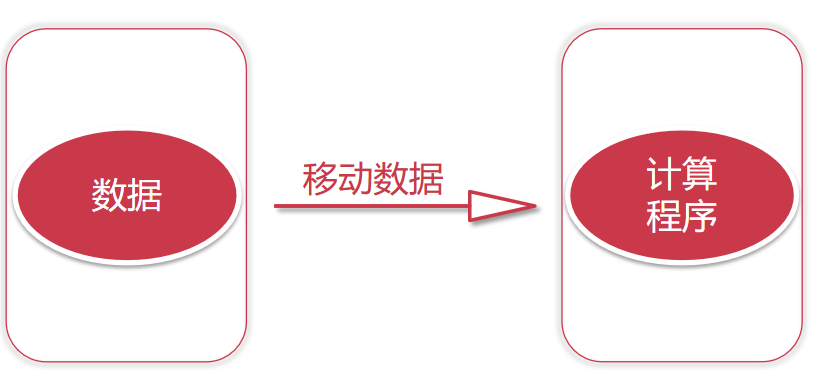
如果我们考虑把计算程序移动到mysql上面去执行,是不是就可以节省网络IO了,是的!这种方式称之为移动计算,就是把计算程序移动到数据所在的节点上面。
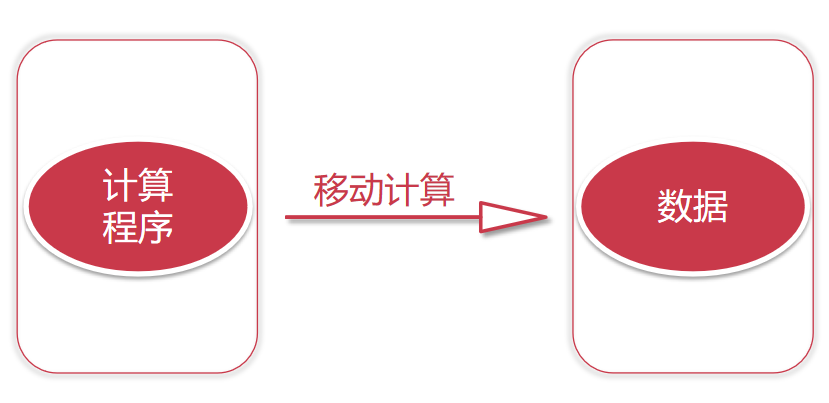
如果我们数据量很大的话,我们的数据肯定是由很多个节点存储的,这个时候我们就可以把我们的程序代码拷贝到对应的节点上面去执行,程序代码都是很小的,一般也就几十KB或者几百KB,加上外部依赖包,最大也就几兆 ,甚至几十兆,但是我们需要计算的数据动辄都是几十G、几百G,他们两个之间的差距不是一星半点啊。
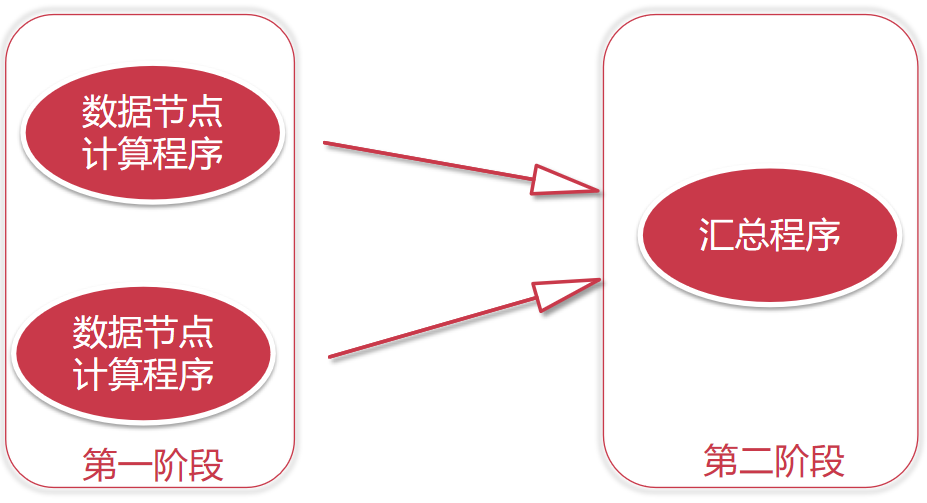
这样我们的代码就可以在每个数据节点上面执行了,但是这个代码只能计算当前节点上的数据的,如果我们想要统计数据的总行数,这里每个数据节点上的代码只能计算当前节点上数据的行数,所以还的有一个汇总程序,这样每个数据节点上面计算的临时结果就可以通过汇总程序得到最终的结果了。
此时汇总程序需要传递的数据量就很小了,只需要接收一个数字即可。
这个计算过程就是分布式计算,这个步骤分为两步:
2.MapReduce原理
MapReduce是一种分布式计算模型,是Google提出来的,主要用于搜索领域,解决海量数据的计算问题。MapReduce是分布式运行的,由两个阶段组成:Map和Reduce。
Map就是对数据进行局部汇总,Reduce就是对局部数据进行最终汇总。分别对应分布式计算步骤的第一步和第二步。
我们来看下面这张图:
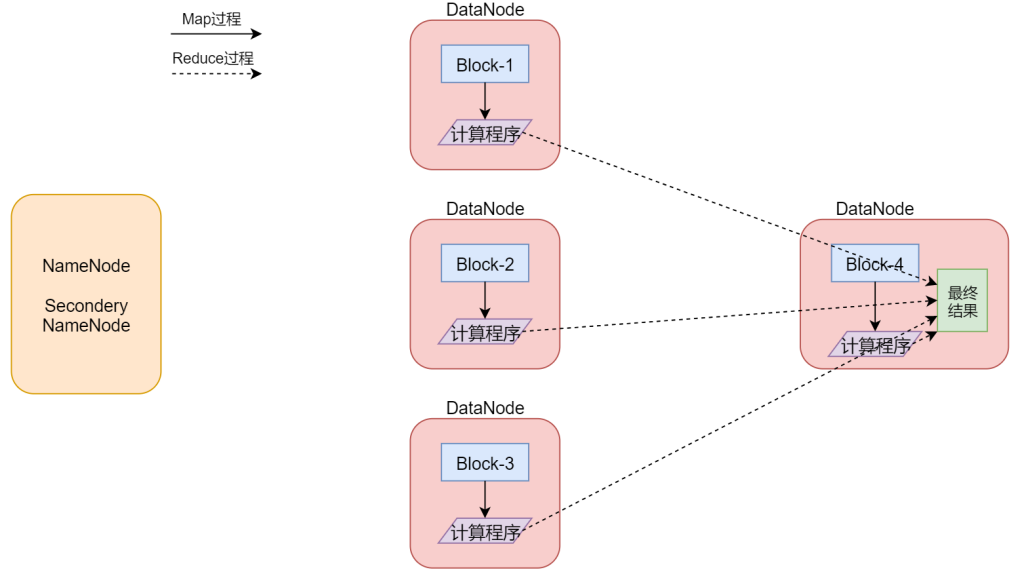
这是一个Hadoop集群,一共5个节点。一个主节点,四个从节点。
假设我们有一个512M的文件,这个文件会产生4个block块,假设这4个block块正好分别存储到了集群的4个节点上,我们的计算程序会被分发到每一个数据所在的节点,然后开始执行计算,在map阶段,针对每一个block块对应的数据都会产生一个map任务(这个map任务其实就是执行这个计算程序的),在这里也就意味着会产生4个map任务并行执行,4个map阶段都执行完毕以后,会执行reduce阶段,在reduce阶段中会对这4个map任务的输出数据进行汇总统计,得到最终的结果。
下面看一个官方的mapreduce原理图。
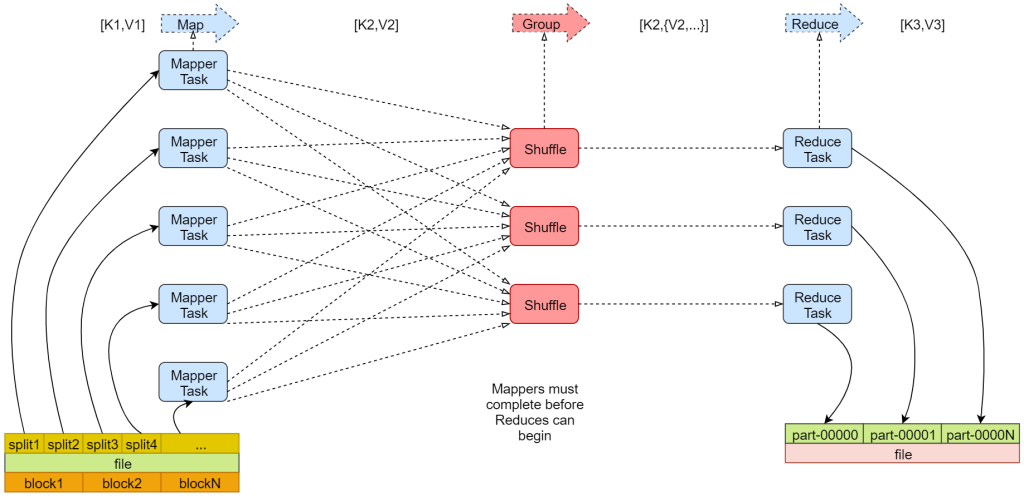
左下角是一个文件,文件最下面是几个block块,说明这个文件被切分成了这几个block块,文件上面是一些split,注意,咱们前面说的每个block产生一个map任务,其实这是不严谨的,其实严谨一点来说的话应该是一个split产生一个map任务。
那这里的block和split之间有什么关系吗? 我们来分析一下。block块是文件的物理切分,在磁盘上是真实存在的。是对文件的真正切分。而split是逻辑划分,不是对文件真正的切分,默认情况下我们可以认为一个split的大小和一个block的大小是一样的,所以实际上是一个split会产生一个map task。
这里面的map Task就是咱们前面说的map任务,看后面有一个reduce Task,reduce会把结果数据输出到hdfs上,有几个reduce任务就会产生几个文件,这里有三个reduce任务,就产生了3个文件,咱们前面分析的案例中只有一个reduce任务做全局汇总。
注意观察map的输入输出, reduce的输入输出。也就是说map的输出刚好就是reduce的输入。
3.MapReduce之Map阶段
假设我们有一个文件,文件里面有两行内容: 第一行是hello you 第二行是hello me
我们想统计文件中每个单词出现的总次数。
第一步:框架会把输入文件(夹)划分为很多InputSplit,这里的inputsplit就是前面我们所说的split【对文件进行逻辑划分产生的】,默认情况下,每个HDFS的Block对应一个InputSplit。再通过RecordReader类,把每个InputSplit解析成一个一个的
注意:map第一次执行会产生<0,hello you>,第二次执行会产生<10,hello me>,并不是执行一次就获取到这两行结果了,因为每次只会读取一行数据,我在这里只是把这两行执行的最终结果都列出来了
第二步:框架调用Mapper类中的map(…)函数,map函数的输入是
因为我们需要统计文件中每个单词出现的总次数,所以需要先把每一行内容中的单词切开,然后记录出现次数为1,这个逻辑就需要我们在map函数中实现了
那针对<0,hello you>执行这个逻辑之后的结果就是
针对<10,hello me>执行这个逻辑之后的结果是
第三步:框架对map函数输出的
第四步:框架对每个分区中的数据,都会按照k2进行排序、分组。分组指的是相同k2的v2分成一个组。
先按照k2排序
然后按照k2进行分组,把相同k2的v2分成一个组
第五步:在map阶段,框架可以选择执行Combiner过程 Combiner可以翻译为规约,规约是什么意思呢? 在刚才的例子中,咱们最终是要在reduce端计算单词出现的总次数的,所以其实是可以在map端提前执行reduce的计算逻辑,先对在map端对单词出现的次数进行局部求和操作,这样就可以减少map端到reduce端数据传输的大小,这就是规约的好处,当然了,并不是所有场景都可以使用规约,针对求平均值之类的操作就不能使用规约了,否则最终计算的结果就不准确了。
Combiner一个可选步骤,默认这个步骤是不执行的。
第六步:框架会把map task输出的
至此,整个map阶段执行结束
最后注意一点: MapReduce程序是由map和reduce这两个阶段组成的,但是reduce阶段不是必须的,也就是说有的mapreduce任务只有map阶段,为什么会有这种任务呢? 是这样的,咱们前面说过,其实reduce主要是做最终聚合的,如果我们这个需求是不需要聚合操作,直接对数据做过滤处理就行了,那也就意味着数据经过map阶段处理完就结束了,所以如果reduce阶段不存在的话,map的结果是可以直接保存到HDFS中的
注意,如果没有reduce阶段,其实map阶段只需要执行到第二步就可以,第二步执行完成以后,结果就可以直接输出到HDFS了。
4.MapReduce之Reduce阶段
第一步:框架对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。这个过程称作shuffle
针对我们这个需求,只有一个分区,所以把数据拷贝到reduce端之后还是老样子
第二步:框架对reduce端接收的相同分区的
不过针对我们这个需求只有一个map任务一个分区,所以最终的结果还是老样子
第三步:框架调用Reducer类中的reduce方法,reduce方法的输入是
第四步:框架把reduce的输出结果保存到HDFS中。 hello 2 me 1 you 1
至此,整个reduce阶段结束。