Spark有一个非常重要的特性就是共享变量。默认情况下,如果在一个算子函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个task中。此时每个task只能操作自己的那份变量数据。如果多个task想要共享某个变量,那么这种方式是做不到的。
1.共享变量的工作原理
Spark有一个非常重要的特性就是共享变量。默认情况下,如果在一个算子函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个task中。此时每个task只能操作自己的那份变量数据。如果多个task想要共享某个变量,那么这种方式是做不到的。
Spark为此提供了两种共享变量:
- Broadcast Variable(广播变量)
- Accumulator(累加变量)
2.Broadcast Variable
Broadcast Variable会将使用到的变量,仅仅为每个节点拷贝一份,而不会为每个task都拷贝一份副本,因此其最大的作用,就是减少变量到各个节点的网络传输消耗,以及在各个节点上的内存消耗。通过调用SparkContext的broadcast()方法,针对某个变量创建广播变量。
注意:广播变量,是只读的。然后在算子函数内,使用到广播变量时,每个节点只会拷贝一份副本。可以使用广播变量的value()方法获取值。
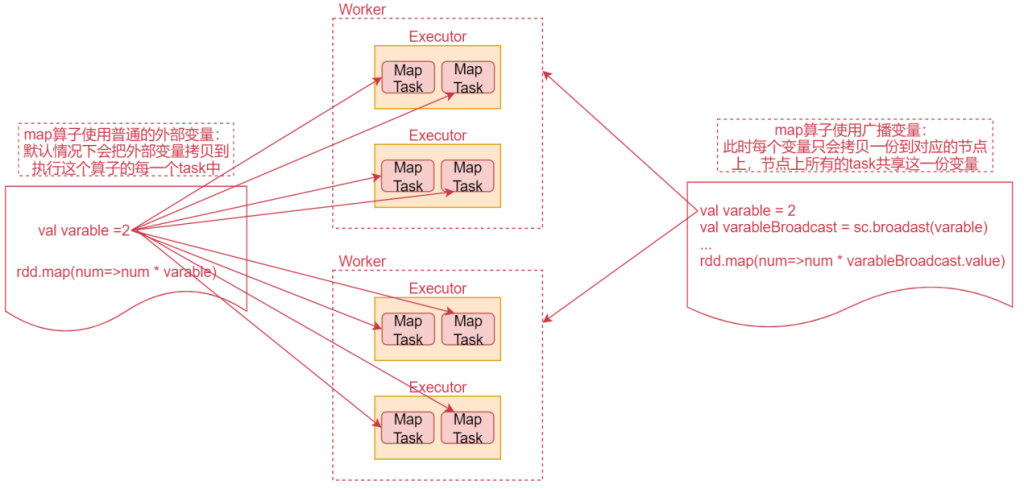
如果算子函数中使用的外部变量,是广播变量的话,那么每个变量只会拷贝一份到每个节点上。节点上所有的task都会共享这一份变量,就可以减少网络传输消耗的时间,以及减少内存占用了。大家可以想象一个极端情况,如果map算子有10个task,恰好这10个task还都在一个worker节点上,那么这个时候,map算子使用的外部变量就会在这个worker节点上保存10份,这样就很占用内存了。
下面我们来具体使用一下这个广播变量,Scala代码如下:
package com.simoniu.scalademo
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:使用广播变量
* Created by simoniu
*/
object BroadcastScalaDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("BroadcastOpScala")
.setMaster("local")
val sc = new SparkContext(conf)
val dataRDD = sc.parallelize(Array(1,2,3,4,5))
val varable = 2
//dataRDD.map(_ * varable)
//1:定义广播变量
val varableBroadcast = sc.broadcast(varable)
//2:使用广播变量,调用其value方法,注意:广播变量是只读的不能修改。
dataRDD.map(_ * varableBroadcast.value).foreach(println(_))
sc.stop()
}
}
运行结果:
2
4
6
8
10
Java实现如下:
package com.simoniu.sparkdemo.javademo;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.broadcast.Broadcast;
import java.util.Arrays;
/**
* 需求:使用广播变量
* Created by simoniu
*/
public class BroadcastJavaDemo {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("BroadcastOpJava")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
int varable = 2;
//1:定义广播变量
Broadcast<Integer> varableBroadcast = sc.broadcast(varable);
//2:使用广播变量
dataRDD.map(new Function<Integer, Integer>() {
@Override
public Integer call(Integer i1) throws Exception {
return i1 * varableBroadcast.value();
}
}).foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer i) throws Exception {
System.out.println(i);
}
});
sc.stop();
}
}
3.Accumulator
Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。正常情况下在Spark的任务中,由于一个算子可能会产生多个task并行执行,所以在这个算子内部执行的聚合计算都是局部的,想要实现多个task进行全局聚合计算,此时需要使用到Accumulator这个共享的累加变量。
注意:Accumulator只提供了累加的功能。在task只能对Accumulator进行累加操作,不能读取它的值。只有在Driver进程中才可以读取Accumulator的值。
1).scala实现
package com.simoniu.scalademo
import org.apache.spark.{SparkConf, SparkContext}
/**
* 需求:使用累加变量
* Created by simoniu
*/
object AccumulatorScalaDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("AccumulatorOpScala")
.setMaster("local")
val sc = new SparkContext(conf)
val dataRDD = sc.parallelize(Array(1, 2, 3, 4, 5))
//这种写法是错误的,因为foreach代码是在worker节点上执行的
// var total = 0和println("total:"+total)是在Driver进程中执行的
//所以无法实现累加操作
//并且foreach算子可能会在多个task中执行,这样foreach内部实现的累加也不是最终全局累加的结果
/*var total = 0
dataRDD.foreach(num=>total += num)
println("total:"+total)*/
//所以此时想要实现累加操作就需要使用累加变量了
//1:定义累加变量
val sumAccumulator = sc.longAccumulator
//2:使用累加变量
dataRDD.foreach(num => sumAccumulator.add(num))
//注意:只能在Driver进程中获取累加变量的结果
println("sum = "+sumAccumulator.value)
}
}
运行结果:
sum = 15
2).Java实现
package com.simoniu.sparkdemo.javademo;
import org.apache.spark.Accumulator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.util.LongAccumulator;
import java.util.Arrays;
/**
* 需求:使用累加变量
* Created by simoniu
*/
public class AccumulatorJavaDemo {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName("AccumulatorOpJava")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> dataRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
//1:定义累加变量
LongAccumulator sumAccumulator = sc.sc().longAccumulator();
//2:使用累加变量
dataRDD.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer i) throws Exception {
sumAccumulator.add(i);
}
});
//获取累加变量的值
System.out.println("sum = "+ sumAccumulator.value());
}
}