配置Spark引擎
配置Spark引擎
配置Spark引擎。
1.向HDFS上传Spark纯净版jar包
hive配置spark引擎需要先确认已经正确安装了spark-2.4.5和正确配置了spark环境变量。
1).上传并解压spark-2.4.5-bin-without-hadoop-scala-2.12.tgz
[root@master tools]# cd /root/tools
[root@master tools]# mkdir temp
[root@master tools]# tar -zxvf spark-2.4.5-bin-without-hadoop-scala-2.12.tgz -C /root/tools/temp
2).上传Spark纯净版jar包到HDFS
[root@master tools]# hdfs dfs -mkdir /spark-jars
[root@master tools]# hdfs dfs -put temp/spark-without/jars/* /spark-jars
2.修改hive-site.xml文件
<!--Spark依赖位置(注意:端口号9000必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://master:9000/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive和Spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>10000ms</value>
</property>
3.Hive on Spark测试
beeline连接到hive后,首先检查是否已经使用了spark引擎。
0: jdbc:hive2://master:10000> set hive.execution.engine;
+------------------------------+
| set |
+------------------------------+
| hive.execution.engine=spark |
+------------------------------+
测试一条插入语句。
0: jdbc:hive2://master:10000> insert into users values (600,'robot','888888');
No rows affected (24.506 seconds)
0: jdbc:hive2://master:10000> select * from users;
+------------+-----------------+-----------------+
| users.uid | users.username | users.password |
+------------+-----------------+-----------------+
| 100 | admin | 123456 |
| 200 | zhangsan | 123456 |
| 300 | lisi | 654321 |
| 600 | robot | 888888 |
+------------+-----------------+-----------------+
4 rows selected (0.197 seconds)
可访问ResourceManager的web页面查看spark计算任务完成情况相关信息。
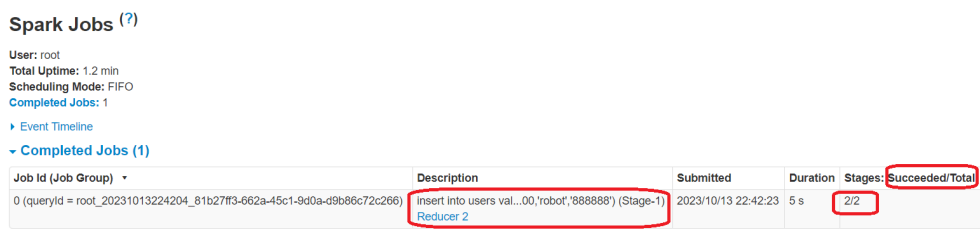
使用yarn application -kill 关闭任务。
[root@master bin]# yarn application -kill application_1697204874902_0004
2023-10-13 22:47:39,746 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.128.128:8032
Application application_1697204874902_0004 has already finished