Spark HistoryServer
Spark HistoryServer
Spark HistoryServer.
上小节我们使用了 on yarn模式的时候会发现看不到输出的日志信息,这主要是因为没有开启spark的historyserver,我们只开启了hadoop的historyserver。
我们可以任意选择一个服务器开启spark 的historyserver进程都可以。
1.开启Spark History Server
在HDFS中建立存放目录。
hdfs dfs -mkdir -p /user/spark/applicationHistory
#把该目录的访问权限赋给spark用户
[root@master examples]# hdfs dfs -chown -R spark: /user/spark/
[root@master examples]# hdfs dfs -chown -R spark: /user/spark/applicationHistory
[root@master examples]# hdfs dfs -chmod -R 777 /user/spark
需要修改spark-defaults.conf和spark-env.sh。
spark-defaults.conf
# Example:
spark.master spark://master:4040
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/user/spark/applicationHistory
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
spark.yarn.historyServer.address master:18080
注意:在哪个节点上启动spark的historyserver进程,spark.yarn.historyServer.address的值里面就指定哪个节点的主机名信息。
spark-env.sh
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_271
export SPARK_MASTER_HOST=master
export HADOOP_CONF_DIR=/usr/local/hadoop3.1/etc/hadoop
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://master:9000//user/spark/applicationHistory"
启动Spark HistoryServer:
cd $SPARK_HOME
sbin/start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-master.out
jps查看Spark HistoryServer是否启动成功:
[root@master examples]# jps
5232 ResourceManager
32209 HistoryServer
44419 Jps
4469 NameNode
4875 SecondaryNameNode
6763 JobHistoryServer
重新使用on yarn模式向集群提交任务,查看spark的任务界面。
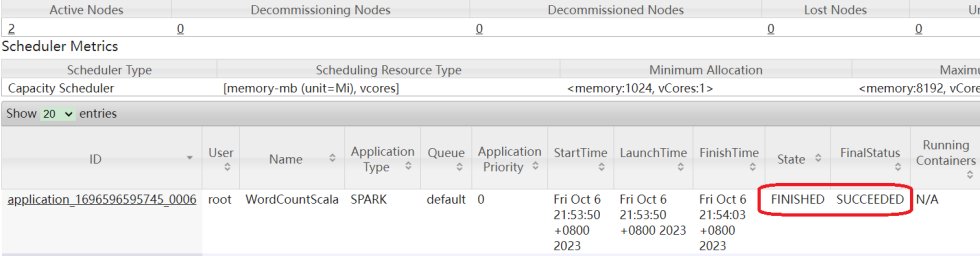
点击任务后面的history链接即可。
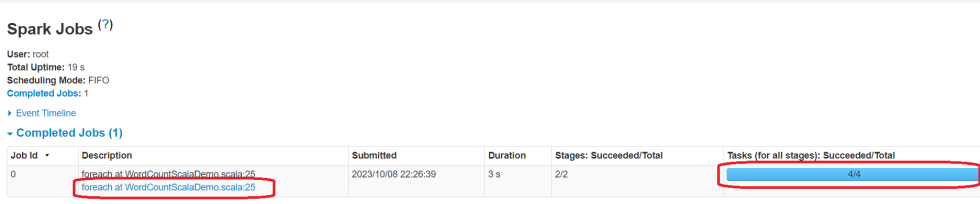
想要查看foreach打印的日志信息,可以点击Stages链接。
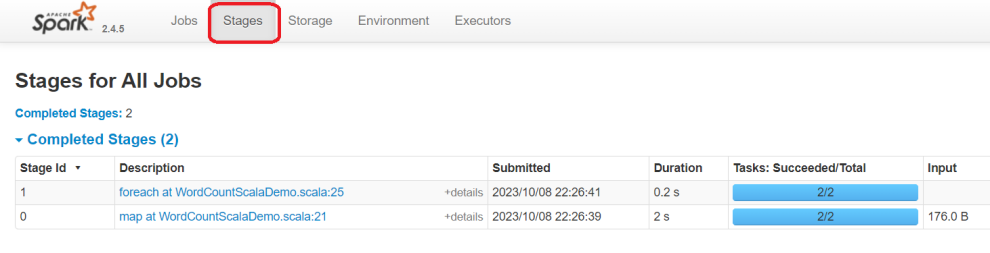
再点击stdout这里。
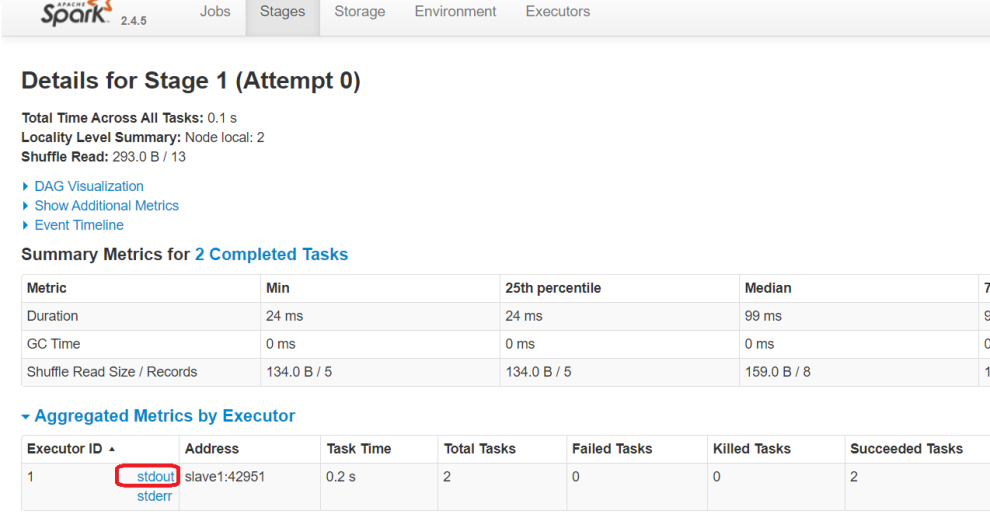
最后就可以看到foreach输出的信息了。
如果history链接无法打开,说明window 的DNS无法解析 master主机。我们在windows的hosts文件中配置master这个主机名和ip的映射关系即可。
192.168.128.129 slave1
192.168.128.130 slave2
192.168.128.128 master
关闭Spark HistoryServer:
cd $SPARK_HOME
sbin/stop-history-server.sh