WordCount案例
Spark之WordCount案例
Spark之WordCount案例。
首先看来一个快速入门案例,单词计数。这个需求就是类似于我们在学习Hadoop的MapReduce的时候学的案例。 需求这样的:读取文件中的所有内容,计算每个单词出现的次数。
1.搭建开发环境
下面来创建一个maven或者springboot项目,集成java和scala的sdk。
1).检查idea是否安装了scala插件。
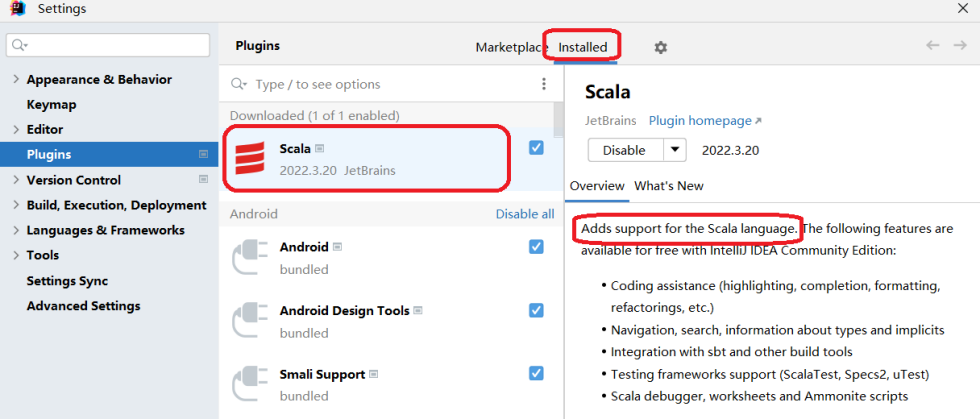
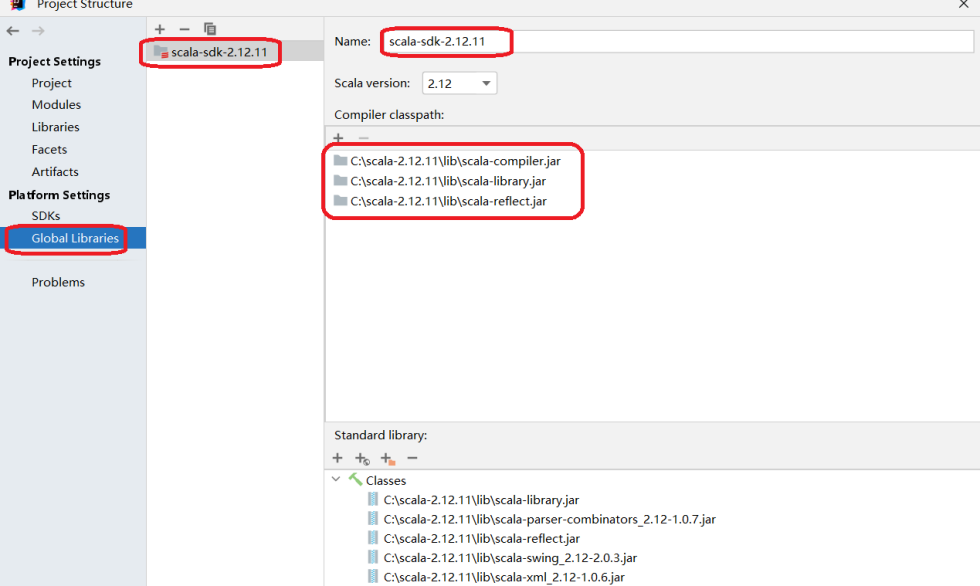
2).ProjectStructure->GlobalLibraries 里添加scala-sdk
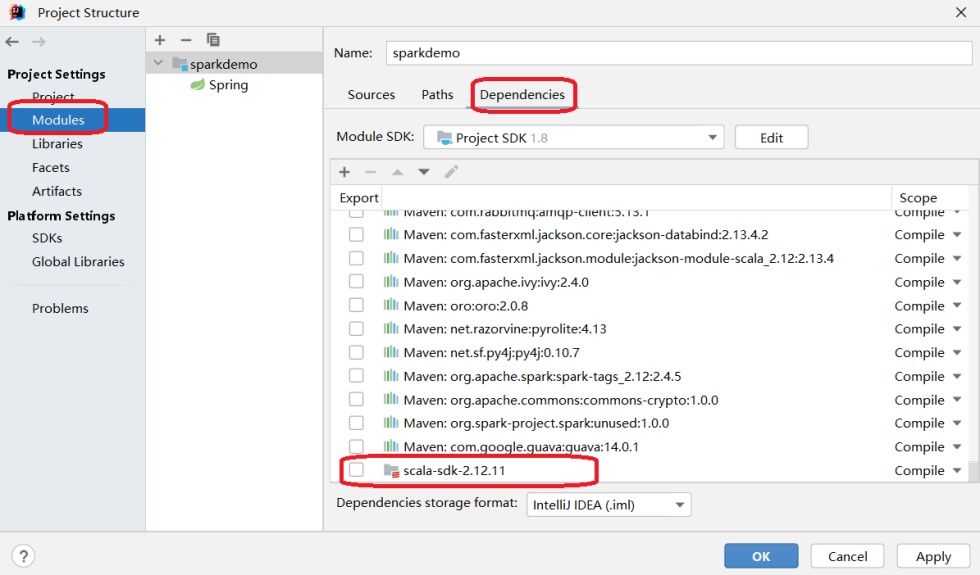
3).ProjectStructure->Modules->Dependencies里添加scala-sdk
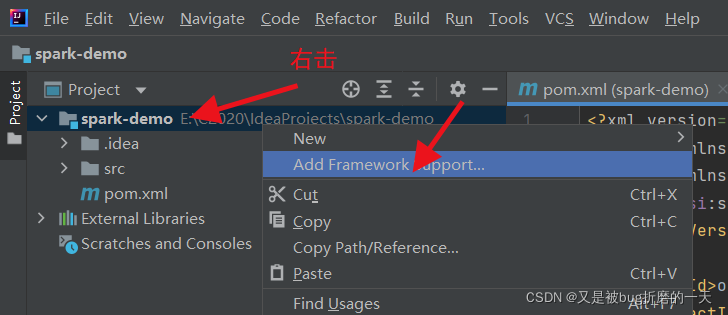
4).项目开启支持spark。
5).以springboot项目为例,其pom.xml依赖如下:
...
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.6.13</spring-boot.version>
<spark-version>2.4.5</spark-version>
<guava-version>14.0.1</guava-version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark-version}</version>
</dependency>
<!--解决guava依赖版本冲突-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava-version}</version>
</dependency>
</dependencies>
6).项目结构图如下所示:
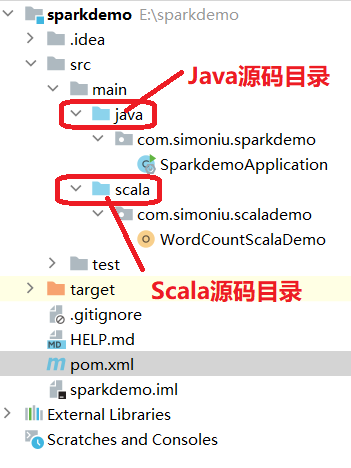
7).在scala目录下创建包com.simoniu.scalademo,再创建一个Scala object:WordCountScalaDemo
代码如下:
package com.simoniu.scalademo
import org.apache.spark.{SparkConf, SparkContext}
object WordCountScalaDemo {
def main(args: Array[String]): Unit = {
//第一步:创建SparkContext
val conf = new SparkConf()
conf.setAppName("WordCountScala") //设置任务名称
.setMaster("local") //local表示在本地执行
val sc = new SparkContext(conf)
//第二步:加载数据
val linesRDD = sc.textFile("D:\\uploadFiles\\hello.txt")
//第三步:对数据进行切割,把一行数据切分成一个一个的单词
val wordsRDD = linesRDD.flatMap(_.split(" "))
//第四步:迭代words,将每个word转化为(word,1)这种形式
val pairRDD = wordsRDD.map((_, 1))
//第五步:根据key(其实就是word)进行分组聚合统计
val wordCountRDD = pairRDD.reduceByKey(_ + _)
//第六步:将结果打印到控制台
wordCountRDD.foreach(wordCount => println(wordCount._1 + "--" + wordCount._2))
//第七步:停止SparkContext
sc.stop()
}
}
8). hello.txt 测试数据如下:
hello linux
hello java
hello python
hello javascript
welcome html
hello spark
welcome hadoop
welcome flume
hello hive
9).运行结果
spark--1
hive--1
hadoop--1
flume--1
python--1
hello--6
linux--1
java--1
welcome--3
javascript--1
html--1
注意:由于此时我们在代码中设置的Master为local,表示会在本地创建一个临时的spark集群运行这个代码,这样有利于代码调试。
10).在com.simoniu.sparkdemo.javademo包下,新建名字为WordCountJavaDemo的Java class.
package com.simoniu.sparkdemo.javademo;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.*;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* 需求:单词计数
* Created by simoniu
*/
public class WordCountJavaDemo {
public static void main(String[] args) {
//第一步:创建SparkContext:
//注意,针对java代码需要获取JavaSparkContext
SparkConf conf = new SparkConf();
conf.setAppName("WordCountJava")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
//第二步:加载数据
JavaRDD<String> linesRDD = sc.textFile("D:\\uploadFiles\\hello.txt");
//第三步:对数据进行切割,把一行数据切分成一个一个的单词
//注意:FlatMapFunction的泛型,第一个参数表示输入数据类型,第二个表示是输出数据类型
JavaRDD<String> wordRDD = linesRDD.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
//第四步:迭代words,将每个word转化为(word,1)这种形式
//注意:PairFunction的泛型,第一个参数是输入数据类型
//第二个是输出tuple中的第一个参数类型,第三个是输出tuple中的第二个参数类型
//注意:如果后面需要使用到....ByKey,前面都需要使用mapToPair去处理
JavaPairRDD<String, Integer> pairRDD = wordRDD.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
//第五步:根据key(其实就是word)进行分组聚合统计
JavaPairRDD<String, Integer> wordCountRDD = pairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
//第六步:将结果打印到控制台
wordCountRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {
public void call(Tuple2<String, Integer> tup) throws Exception {
System.out.println(tup._1 + "--" + tup._2);
}
});
//第七步:停止sparkContext
sc.stop();
}
}
11).测试运行
spark--1
hive--1
hadoop--1
flume--1
python--1
hello--6
linux--1
java--1
welcome--3
javascript--1
html--1