Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。

1.Flume版本
当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分。
Flume原名是 Flume OG (original generation)也就是Flume 0.9X版本,但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94.0 中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation,改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume)。
2.Flume特点
- 它有一个简单、灵活的基于流的数据流结构,这个其实就是刚才说的Agent内部有三大组件,数据通过这三大组件流动的。
- 具有负载均衡机制和故障转移机制。
- 一个简单可扩展的数据模型(Source、Channel、Sink),这几个组件是可灵活组合的。
3.Flume应用场景
下面这个图,这个图里面主要演示了Flume的多路输出,就是可以将采集到的一份数据输出到多个目的地中,不同目的地的数据对应不同的业务场景。
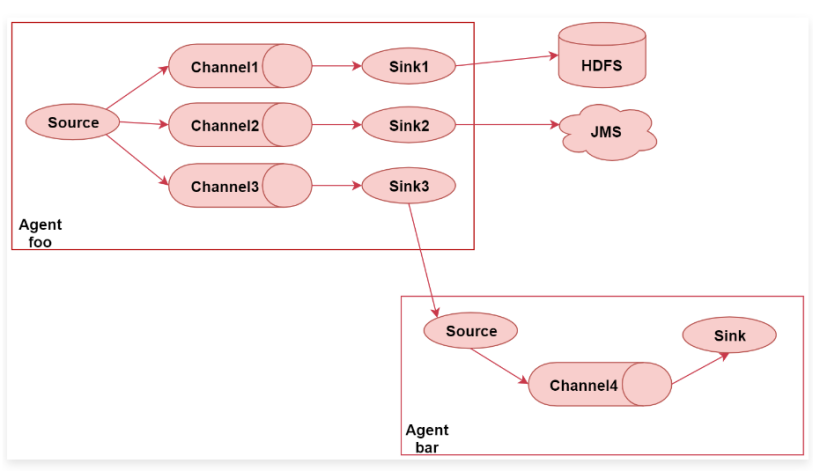
这个图里面一共有两个Agent,表示我们启动了2个Flume的代理,或者可以理解为了启动了2个flume的进程。 首先看左边这个agent,给他起个名字叫 foo。 这里面有一个source,source后面接了3个channel,表示source读取到的数据会重复发送给每个channel,每个channel中的数据都是一样的 针对每个channel都接了一个sink,这三个sink负责读取对应channel中的数据,并且把数据输出到不同的目的地, sink1负责把数据写到hdfs中,sink2负责把数据写到一个Java消息服务数据队列中,sink3负责把数据写给另一个Agent。
4.Flume的三大核心组件
Flume的三大核心组件: - Source:数据源 - Channel:临时存储数据的管道 - Sink:目的地
Source:数据源:通过source组件可以指定让Flume读取哪里的数据,然后将数据传递给后面的channel Flume内置支持读取很多种数据源,基于文件、基于目录、基于TCP\UDP端口、基于HTTP、Kafka的等等、当然了,如果这里面没有你喜欢的,他也是支持自定义的。
Channel:接受Source发出的数据,可以把channel理解为一个临时存储数据的管道 Channel的类型有很多:内存、文件,内存+文件、JDBC等
Sink:从Channel中读取数据并存储到指定目的地。 Sink的表现形式有很多:打印到控制台、HDFS、Kafka等,