hive实战之谷粒影音(一)
hive实战之谷粒影音(一)
1.需求描述
统计硅谷影音视频网站的常规指标,各种TopN指标: - 统计视频观看数Top10 - 统计视频类别热度Top10 - 统计视频观看数Top20所属类别 - 统计视频观看数Top50所关联视频的所属类别Rank - 统计每个类别中的视频热度Top10 - 统计每个类别中视频流量Top10 - 统计上传视频最多的用户Top10以及他们上传的视频 - 统计每个类别视频观看数Top10
2.项目数据结构
视频表:
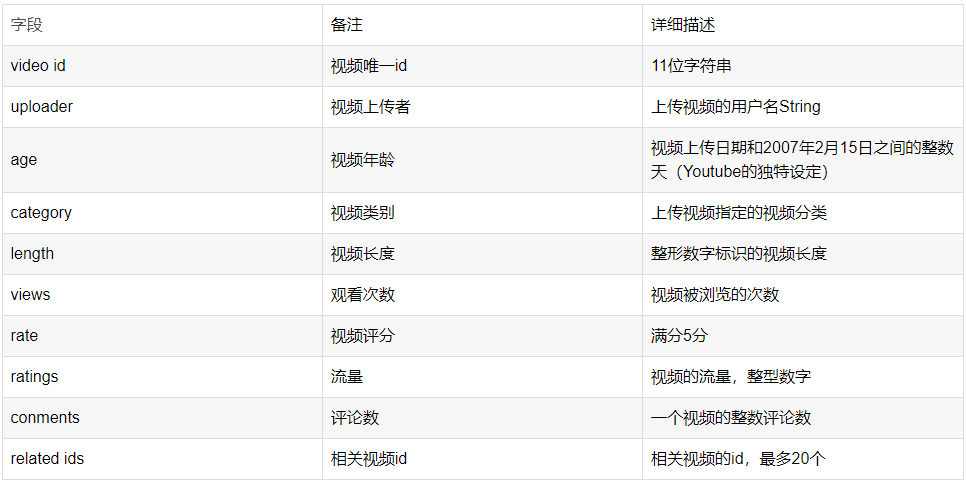
用户表:

3.ETL原始数据
ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
ETL是构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。
通过观察原始数据形式,可以发现,视频可以有多个所属分类,每个所属分类用&符号分割,且分割的两边有空格字符,同时相关视频也是可以有多个元素,多个相关视频又用“\t”进行分割。为了分析数据时方便对存在多个子元素的数据进行操作,我们首先进行数据重组清洗操作。即:将所有的类别用“&”分割,同时去掉两边空格,多个相关视频id也使用“&”进行分割。
4.项目依赖准备
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<java.version>1.8</java.version>
<!-- maven打包时跳过测试 -->
<skipTests>true</skipTests>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.6.13</spring-boot.version>
<mysql.version>8.0.28</mysql.version>
<mybatis-plus.version>3.5.0</mybatis-plus.version>
<junit.version>4.12</junit.version>
<lombok.version>1.18.24</lombok.version>
<hutool.version>5.8.18</hutool.version>
<hive.version>3.1.3</hive.version>
<hadoop.version>3.1.3</hadoop.version>
</properties>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<version>${spring-boot.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>${spring-boot.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
<version>${spring-boot.version}</version>
</dependency>
<!--mysql的驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
<version>${mysql.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
<version>${lombok.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<version>${spring-boot.version}</version>
</dependency>
<!--mybatis-plus的依赖-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
<version>${junit.version}</version>
</dependency>
<!--糊涂工具类依赖-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>${hutool.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-runner</artifactId>
</exclusion>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
5.数据清洗实现
项目结构图如下:
ETLUtil.java
package com.sust.hive.server.util;
public class ETLUtil {
/**
* 1.过滤掉长度不够的,小于9个字段
* 2.去掉类别字段中的空格
* 3.修改相关视频ID字段的分隔符,‘\t’替换为'&'
* @param oriStr
* @return
*/
public static String etlStr(String oriStr){
StringBuffer sb = new StringBuffer();
//1.切割
String[] fields = oriStr.split("\t");
//2.对字段长度进行过滤(我们一共有10个字段)
if (fields.length<9){
return null;
}else {
try {
int temp = Integer.parseInt(fields[8]);
}catch (NumberFormatException ex){
ex.printStackTrace();
System.out.println("缺失重要字段....");
return null;
}
}
//3.去掉类别字段的空格
fields[3] = fields[3].replaceAll(" ","");
//4.修改相关视频ID字段的分隔符,由‘t’替换为‘&’
for (int i = 0; i < fields.length; i++) {
//对非相关ID进行处理
if (i < 9) {
sb.append(fields[i]).append("\t");
} else {
//对非相关ID字段进行处理 第一个是输出结尾的值tsSmTN3h_9-s
if (i == fields.length - 1) {
sb.append(fields[i]);
} else {
sb.append(fields[i]).append("&");
}
}
}
//5.返回结果
return sb.toString();
}
public static void main(String[] args) {
System.out.println(ETLUtil.etlStr("bdDskrr8jRY\tjana9999\t589\tPeople & Blogs\t219\t414\t1" +
".73\t15\t14\t7D0Mf4Kn4Xk\tbdDskrr8jRY\tORbIqKM-Wkc\tj2uwoUGbRY8\tTeGGfjqQASk\tyuO6yjlvXe8" +
"\tXCpe8Z5bi74\tG0KPorRyxzA\tBfmbPtL0iMg\txd1BK7eHtmE\tII6sc3fWMmw\te2k0h6tPvGc\ty3IDp2n7B48" +
"\th944I8xXmqc\t60f6z_DWhBs\tk7_fEazJQpA\tXKI2J8ecimk\t_NwCteJyUPg\ttBUsm2RbkV4\tsSmTN3h_9-s"));
}
}
ETLMapper.java
package com.sust.hive.server.mapper;
import com.sust.hive.server.util.ETLUtil;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ETLMapper extends Mapper<LongWritable, Text, NullWritable,Text> {
//定义全局的value
private Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException {
//1.获取数据
String oriStr = value.toString();
//2.过滤数据
String etlStr = ETLUtil.etlStr(oriStr);
//3.写出
if (etlStr == null){
return;
}
v.set(etlStr);
context.write(NullWritable.get(),v);
}
}
ETLDriver.java
package com.sust.hive.server.util;
import com.sust.hive.server.mapper.ETLMapper;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ETLDriver implements Tool {
private Configuration configuration;
public int run(String[] args) throws Exception {
//注意:这行代码打包之前一定要注释掉,因为我们是在windows上做的测试。
//window的路径在linux上肯定不识别。
args = new String[]{"F:\\myvideo\\2008\\0222","f:/myvideo/out"};
//1.获取Job
Job job = Job.getInstance(configuration);
//2.设置Jar包路径
job.setJarByClass(ETLDriver.class);
//3.设置Mapper类输出Kv类型
job.setMapperClass(ETLMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
//job.setOutputValueClass(Text.class);
job.setMapOutputValueClass(Text.class);
//4.设置最终输出的KV类型
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
//5.设置输入输出的路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//6.提交任务
boolean result = job.waitForCompletion(true);
return result?0:1;
}
public void setConf(Configuration conf) {
configuration = conf;
}
public Configuration getConf() {
return configuration;
}
public static void main(String[] args) {
try {
//构建配置信息
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new ETLDriver(), args);
System.out.println(run);
} catch (Exception e) {
e.printStackTrace();
}
}
}
测试执行,ETLDriver的main方法。观察数据清洗后的输出结果如下图所示。
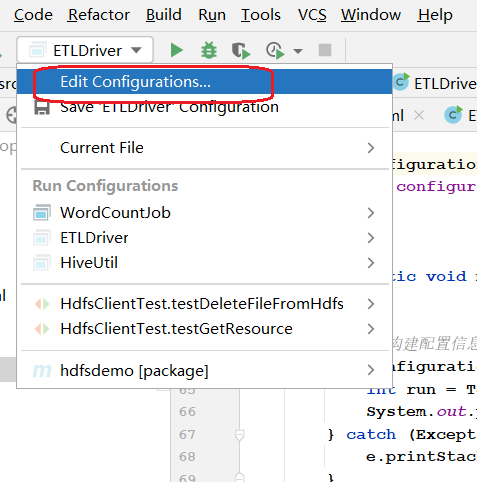
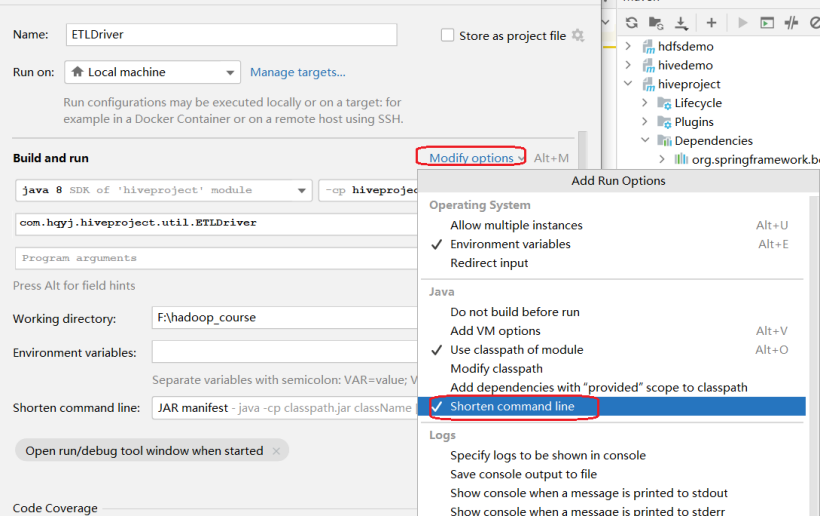
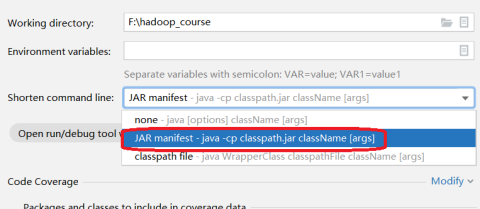
注意:如果编译执行时出现以下异常:
CreateProcess error=206, 文件名或扩展名太长。
修改运行时配置即可。步骤如下: