配置tez引擎
hive3.1.3配置tez引擎
目前Hive支持MapReduce、Tez和Spark, 三种计算引擎。
1.Hive支持的引擎
Hive支持MapReduce、Tez和Spark, 三种计算引擎。在Hive 2.0之后不推荐MR作为计算引擎。
Tez计算引擎
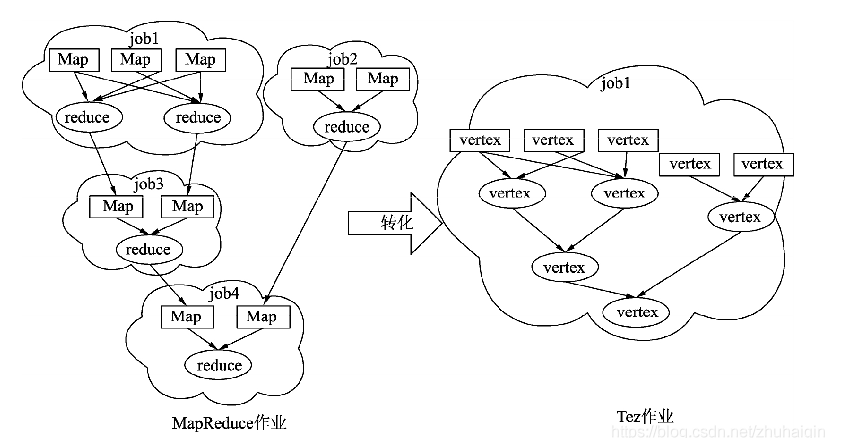
Apache Tez是进行大规模数据处理且支持DAG作业的计算框架,它直接源于MapReduce框架,除了能够支持MapReduce特性,还支持新的作业形式,并允许不同类型的作业能够在一个集群中运行。
Tez绕过了MapReduce很多不必要的中间的数据存储和读取的过程,直接在一个作业中表达了MapReduce需要多个作业共同协作才能完成的事情。
Tez相比于MapReduce有几点重大改进:
- 当查询需要有多个reduce逻辑时,Hive的MapReduce引擎会将计划分解,每个Redcue提交一个MR作业。这个链中的所有MR作业都需要逐个调度,每个作业都必须从HDFS中重新读取上一个作业的输出并重新洗牌。而在Tez中,几个reduce接收器可以直接连接,数据可以流水线传输,而不需要临时HDFS文件,这种模式称为MRR(Map-reduce-reduce*)。
- Tez还允许一次发送整个查询计划,实现应用程序动态规划,从而使框架能够更智能地分配资源,并通过各个阶段流水线传输数据。对于更复杂的查询来说,这是一个巨大的改进,因为它消除了IO/sync障碍和各个阶段之间的调度开销。
- 在MapReduce计算引擎中,无论数据大小,在洗牌阶段都以相同的方式执行,将数据序列化到磁盘,再由下游的程序去拉取,并反序列化。Tez可以允许小数据集完全在内存中处理,而MapReduce中没有这样的优化。仓库查询经常需要在处理完大量的数据后对小型数据集进行排序或聚合,Tez的优化也能极大地提升效率。
2.hive3配置tez引擎
实现步骤如下:
1).上传tez包到HDFS
#创建tez目录
hdfs dfs -mkdir /tez
#上传tez的jar包至/tez目录
hadoop fs -put /root/tools/apache-tez-0.10.1-bin.tar.gz /tez
2).解压缩apache-tez-0.10.1-bin.tar.gz
#解压缩至/usr/local
tar -xzvf apache-tez-0.10.1-bin.tar.gz -C /usr/local
#修改目录名字
mv apache-tez-0.10.1 tez
3).在HADOOP_HOME/etc/hadoop下,新建tez-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<!--hdfs上的tez包的存储路径-->
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/apache-tez-0.10.1-bin.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.history.logging.service.class</name>
<value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value>
</property>
</configuration>
注意:确保core-site.xml中有以下配置。
<property>
<name>fs.defaultFS</name>
<!--集群配置是这里要配置主节点的主机别名,要在/etc/hosts文件中记录别名和ip地址之间的关系-->
<value>hdfs://hadoop-master:9000</value>
</property>
4). 配置hive-env.sh
在hive-env.sh末尾追加一下内容:
#是你的tez的解压目录
export TEZ_HOME=/usr/local/tez
export TEZ_JARS=""
#读取到tez下的jar包
for jar in `ls $TEZ_HOME |grep jar`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar
done
for jar in `ls $TEZ_HOME/lib`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar
done
export HIVE_AUX_JARS_PATH=${TEZ_JARS:1}
5).修改hive-site.xml
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
<property>
<name>hive.tez.container.size</name>
<value>1024</value>
</property>
6).关闭yarn的虚拟内存检查
修改yarn-site.xml
<!-- 关闭yarn虚拟内存检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
7).使用beeline测试tez引擎。
create table student(id string, name string);
insert into student values('1003', 'lisi')
0: jdbc:hive2://hadoop-master:10000> insert into student values('1003', 'lisi');
INFO : Compiling command(queryId=root_20230702235129_214b7847-af3c-4556-ad04-3fbcc2a9f512): insert into student values('1003', 'lisi')
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:col1, type:string, comment:null), FieldSchema(name:col2, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=root_20230702235129_214b7847-af3c-4556-ad04-3fbcc2a9f512); Time taken: 0.247 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20230702235129_214b7847-af3c-4556-ad04-3fbcc2a9f512): insert into student values('1003', 'lisi')
INFO : Query ID = root_20230702235129_214b7847-af3c-4556-ad04-3fbcc2a9f512
INFO : Total jobs = 1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Subscribed to counters: [] for queryId: root_20230702235129_214b7847-af3c-4556-ad04-3fbcc2a9f512
INFO : Session is already open
INFO : Dag name: insert into student values('1003', 'lisi') (Stage-1)
INFO : Status: Running (Executing on YARN cluster with App id application_1688312360480_0007)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... container SUCCEEDED 1 1 0 0 0 0
Reducer 2 ...... container SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 5.49 s
----------------------------------------------------------------------------------------------
INFO : Starting task [Stage-2:DEPENDENCY_COLLECTION] in serial mode
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table myschool.student from hdfs://hadoop-master:9000/user/hive/warehouse/myschool.db/student/.hive-staging_hive_2023-07-02_23-51-29_209_2665729843536195700-4/-ext-10000
INFO : Starting task [Stage-3:STATS] in serial mode
INFO : Completed executing command(queryId=root_20230702235129_214b7847-af3c-4556-ad04-3fbcc2a9f512); Time taken: 5.746 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (6.011 seconds)