Hadoop基础教程(十一)
Hadoop-3.1.3集群配置
Hadoop-3.1.3集群配置
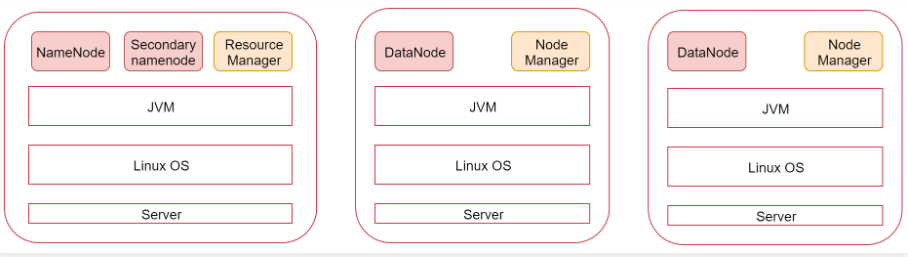
Hadoop一主两从集群配置案例:
我们来看一下这张图,图里面表示是三个节点,左边这一个是主节点,右边的两个是从节点,hadoop集群是支持主从架构的。
1.hosts配置
在hosts文件中增加如下三条IP和主机名映射关系:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.128.128 master
192.168.128.129 slave1
192.168.128.130 slave2
2.测试免密登录
在master主机测试能否免密登录到slave1和slave2.
#把master主机的公钥分别复制到slave1和slave2
[root@hadoop-master sbin]# scp ~/.ssh/authorized_keys slave1:~/
[root@hadoop-master sbin]# scp ~/.ssh/authorized_keys slave2:~/
#在slave1和slave2中添加master的公钥
[root@hadoop-master sbin]# cat ~/authorized_keys >> ~/.ssh/authorized_keys
#测试免密登录
[root@hadoop-master sbin]# ssh slave1
Last login: Tue Jun 27 21:22:11 2023 from hadoop-master
[root@slave1 ~]# ssh slave2
Last login: Tue Jun 27 21:22:17 2023 from slave1
3.配置workers
在master主节点配置$HADOOP_HOME/etc/hadoop/workers
#localhost
slave1
slave2
4.核心配置文档配置
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<!--集群配置是这里要配置主节点的主机别名,要在/etc/hosts文件中记录别名和ip地址之间的关系-->
<value>hdfs://master:9000</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
<!--设置代理用户root访问的主机和组-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<!--修改hdfs-webui使用默认的50070端口-->
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:50070</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<!--两个从节点-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/share/hadoop/mapreduce/*:/share/hadoop/mapreduce/lib/*</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop3.1</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop3.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop3.1</value>
</property>
</configuration>
yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<!--服务器ip地址根据个人情况修改-->
<value>master:8099</value>
<description>这个地址是mr管理界面的</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<!--解决内存不足问题因为yarn的虚拟内存检查模式太过于霸道-->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>15.5</value>
</property>
</configuration>
5.复制hadoop到从节点
cd /usr/local
scp -rq hadoop3.1 slave1:/usr/local/
scp -rq hadoop3.1 slave2:/usr/local/
#重新格式化namenode
hadoop namenode -format
6.测试Hadoop集群
在hadoop-master主机上启动服务。
[root@master sbin]# ./start-all.sh
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Starting namenodes on [master]
上一次登录:日 9月 17 16:22:51 CST 2023pts/5 上
Starting datanodes
上一次登录:日 9月 17 16:23:19 CST 2023pts/5 上
Starting secondary namenodes [master]
上一次登录:日 9月 17 16:23:22 CST 2023pts/5 上
Starting resourcemanager
上一次登录:日 9月 17 16:23:26 CST 2023pts/5 上
Starting nodemanagers
上一次登录:日 9月 17 16:23:30 CST 2023pts/5 上
[root@master sbin]# jps
72019 SecondaryNameNode
71634 NameNode
72356 ResourceManager
72812 Jps
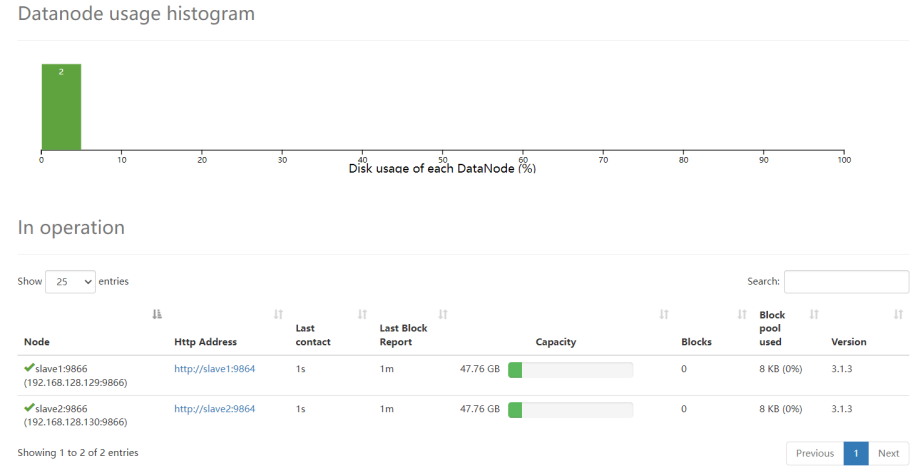
在slave1和slave2查看进程
[root@slave1 ~]# jps
68675 DataNode
70214 Jps
68975 NodeManager
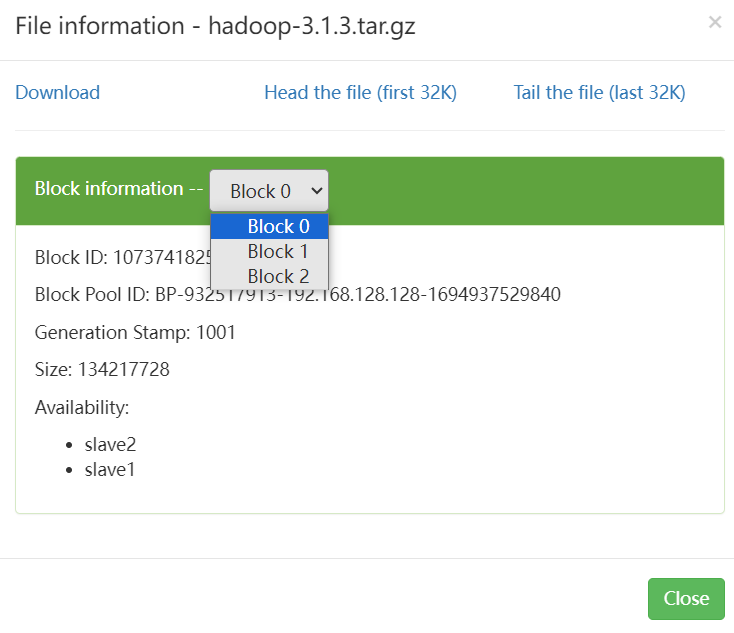
上传大文件测试。
[root@master tools]# hdfs dfs -mkdir -p /tools/
[root@master tools]# hdfs dfs -put hadoop-3.13.tar.gz /tools/