Python数据分析基础(二)
数学基础之一维述性统计
1.一维描述性统计
描述性统计量分为:集中趋势、离散程度(离中趋势)和分布形态。
2.集中趋势

数据的集中趋势,用于度量数据分布的中心位置。直观地说,测量一个属性值的大部分落在何处。描述数据集中趋势的统计量是:平均值、中位数、众数。
- 平均值(Mean):指一组数据的算术平均数,描述一组数据的平均水平,是集中趋势中波动最小、最可靠的指标,但是均值容易受到极端值(极小值或极大值)的影响。
- 中位数(Median):指当一组数据按照顺序排列后,位于中间位置的数,不受极端值的影响,对于定序型变量,中位数是最适合的表征集中趋势的指标。
- 众数(Mode):指一组数据中出现次数最多的观测值,不受极端值的影响,常用于描述定性数据的集中趋势。
众数不用计算,在一组数据中出现次数最多的数值为众数。
平均数非常明显的优点是,它能够利用所有数据的特征,而且比较好算。另外,在数学上,平均数是使误差平方和达到最小的统计量,也就是说利用平均数代表数据,可以使二次损失最小。中位数和众数这两个统计量的特点都是能够避免极端数据,但缺点是没有完全利用数据所反映出来的信息。由于各个统计量有各自的特征,所以需要我们根据实际问题来选择合适的统计量。
3.离散程度
数据的离散趋势,用于描述数据的分散程度,描述离散趋势的统计量是:极差、四分位数极差(IQR)、标准差、离散系数。

4.分布形态
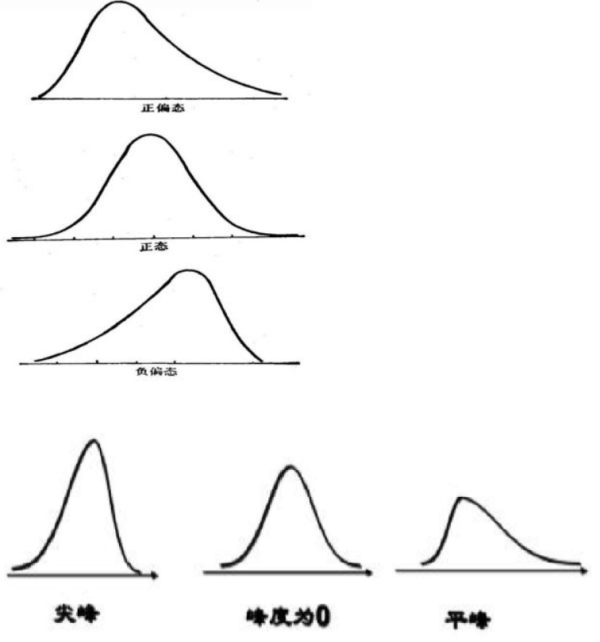
偏度(Skewness):用来评估一组数据分布呈现的对称程度。
当 偏度系数=0时,分布是对称的 当 偏度系数>0时,分布呈正偏态(右偏) 当 偏度系数<0时,分布呈负偏态(左偏)
峰度(Kurtosis):用来评估一组数据的分布形状的高低程度的指标。
当 峰度系数=0时,是正态分布 当 峰度系数>0时,分布形态陡峭,数据分布更集中 当 峰度系数<0时,分布形态平缓,数据分布更分散
其他数据分布图——分位数是观察数据分布的最简单有效的方法,但分位数只能用于观察单一属性的数据分布。散点图可以用来观察双变量的数据分布,聚类可以用来观察更多变量的数据分布。通过观察数据的分布,采用合理的指标,使数据的分析更全面,避免得出像平均工资这类偏离事实的的分析结果。