SKLearn基础教程(八)
手写数字识别案例
1.手写数字识别案例
训练用的数据集使用的是sklearn框架中内置的数字数据集, 共 1797条数据,每条数据由64个特征点组成。
源码实现:
import time
import urllib.request
import numpy as np
import pickle
import cv2
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn import svm, __all__, metrics
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
digits = load_digits()
X = digits.data # 特征数据
y = digits.target # 标签
print(X.shape)
print(X[0])
print(np.array(X[0]).reshape(8, 8)) # 训练数据都是1d的,转成8x8的2d矩阵后,能看出数字的轮廓
print("第一条数据的标签是:", y[0])
def train_by_svc(name, x_train, y_train):
"""
基于SVM的SVC分类器
:param name: 训练好的分类器持久化存储到此名称的文件中
:param x_train: 训练数据
:param y_train: 预期结果
:return:
"""
classifier = svm.SVC(gamma=0.001) # 创捷支持向量机的SVC的分类器(训练集大于1万时不要使用)
# classifier = svm.LinearSVC(dual=False) # 创捷支持向量机的LinearSVC的分类器
# 训练过程
start = time.perf_counter()
classifier.fit(x_train, y_train)
print("训练完成, 耗时:%s" % (time.perf_counter() - start))
with open(name, 'wb') as f:
pickle.dump(classifier, f)
def train_by_knn(name, x_train, y_train):
"""
基于k-邻近算法的KNN分类器
:param name: 训练好的分类器持久化存储到此名称的文件中
:param x_train: 训练数据
:param y_train: 预期结果
:return:
"""
classifier = KNN(n_neighbors=3, algorithm='auto')
# 训练过程
start = time.perf_counter()
classifier.fit(x_train, y_train)
print("训练完成, 耗时:%s" % (time.perf_counter() - start))
with open(name, 'wb') as f:
pickle.dump(classifier, f)
def predict(name, x_test):
"""
从指定文件加载分类器,对数据集进行测试,并返回预测结果
:param name: 分类器文件
:param x_test: 测试数据
:return:
"""
with open(name, 'rb') as f:
clsifier = pickle.load(f)
start = time.perf_counter()
predicted = clsifier.predict(x_test)
print("预测完成, 耗时:%s" % (time.perf_counter() - start))
return predicted
def readimg_from_url(url):
"""
从网络读取图片资源
"""
# 读入完整图片,含alpha通道
res = urllib.request.urlopen(url)
# 读取字节数组
img = np.asarray(bytearray(res.read()), dtype="uint8")
img = cv2.imdecode(img, cv2.IMREAD_COLOR)
return img
# 分隔训练和测试样本, test_size为用来进行测试的数据的占比,0.1即1797 * 0.1约等于180条
X_train, X_test, Y_train, Y_test = train_test_split(X, y,random_state=30, test_size=0.8)
# 训练好的分类器持久化存储到文件“手写数字分类器.cfr”中
# train_by_svc('手写数字分类器.cfr', X_train, Y_train)
train_by_knn('手写数字分类器.cfr', X_train, Y_train)
pre = predict('手写数字分类器.cfr', X_test)
print("分类器结果如下:")
print(metrics.classification_report(Y_test, pre))
print(metrics.confusion_matrix(Y_test, pre))
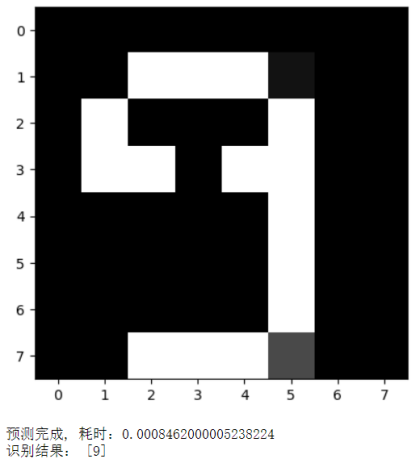
#识别手写数字9
source = readimg_from_url('https://img.simoniu.com/sklearn%E6%89%8B%E5%86%99%E8%AF%86%E5%88%AB%E6%95%B0%E5%AD%97009.jpg')
# source = cv2.imread('image/number009.jpg')
GrayImage = cv2.cvtColor(source, cv2.COLOR_BGR2GRAY) # 转成灰度图
ret, thresh2 = cv2.threshold(GrayImage, 127, 255, cv2.THRESH_BINARY_INV)
feature = cv2.resize(thresh2, (8, 8))
plt.imshow(feature, cmap='gray') # 查看二值化并压缩为8x8后的效果
plt.show()
feature_1d = feature.flatten()
pre = predict('手写数字分类器.cfr', [feature_1d])
print("识别结果:", pre)
运行结果:
(1797, 64)
[ 0. 0. 5. 13. 9. 1. 0. 0. 0. 0. 13. 15. 10. 15. 5. 0. 0. 3.
15. 2. 0. 11. 8. 0. 0. 4. 12. 0. 0. 8. 8. 0. 0. 5. 8. 0.
0. 9. 8. 0. 0. 4. 11. 0. 1. 12. 7. 0. 0. 2. 14. 5. 10. 12.
0. 0. 0. 0. 6. 13. 10. 0. 0. 0.]
[[ 0. 0. 5. 13. 9. 1. 0. 0.]
[ 0. 0. 13. 15. 10. 15. 5. 0.]
[ 0. 3. 15. 2. 0. 11. 8. 0.]
[ 0. 4. 12. 0. 0. 8. 8. 0.]
[ 0. 5. 8. 0. 0. 9. 8. 0.]
[ 0. 4. 11. 0. 1. 12. 7. 0.]
[ 0. 2. 14. 5. 10. 12. 0. 0.]
[ 0. 0. 6. 13. 10. 0. 0. 0.]]
第一条数据的标签是: 0
训练完成, 耗时:0.00047759999961272115
预测完成, 耗时:0.06644479999977193
分类器结果如下:
precision recall f1-score support
0 0.99 1.00 1.00 148
1 0.91 0.99 0.95 132
2 0.99 0.99 0.99 142
3 0.97 0.95 0.96 152
4 1.00 0.98 0.99 152
5 0.99 0.98 0.99 144
6 0.98 0.99 0.99 147
7 0.96 1.00 0.98 141
8 0.98 0.91 0.94 140
9 0.98 0.95 0.96 140
accuracy 0.97 1438
macro avg 0.97 0.97 0.97 1438
weighted avg 0.98 0.97 0.97 1438
[[148 0 0 0 0 0 0 0 0 0]
[ 0 131 0 0 0 0 1 0 0 0]
[ 1 0 141 0 0 0 0 0 0 0]
[ 0 0 2 144 0 0 0 3 1 2]
[ 0 1 0 0 149 0 0 1 1 0]
[ 0 0 0 1 0 141 2 0 0 0]
[ 0 1 0 0 0 0 146 0 0 0]
[ 0 0 0 0 0 0 0 141 0 0]
[ 0 8 0 2 0 0 0 1 128 1]
[ 0 3 0 1 0 1 0 1 1 133]]