1.scipy库简介

scipy是一个python开源的数学计算库,可以应用于数学、科学以及工程领域,它是基于numpy的科学计算库。
主要包含了统计学、最优化、线性代数、积分、傅里叶变换、信号处理和图像处理以及常微分方程的求解以及其他科学工程中所用到的计算。
scipy常用模块介绍:
scipy主要通过下面这些包来实现数学算法和科学计算,后面对于scipy的讲解主要也是基于这些包来实现的
- cluster:包含聚类算法
- constants:物理和数学上的一些常数
- fftpack:快速傅里叶变换
- integrate:积分和常微分方程的求解
- interpolate:插值和平滑的样条函数
- io:输入和输出
- linalg:线性代数
- ndimage:N维的图像处理
- ord:回归正交距离
- optimize:优化和寻根方程
- signal:信号处理
- sparse:稀疏矩阵
- spatial:空间数据结构和算法
- special:特殊的函数
- stats:统计分布和函数
2.标准差
简单来说,标准差是一组数据平均值分散程度的一种度量。一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
例如,两组数的集合{0,5,9,14}和{5,6,8,9}其平均值都是7,但第二个集合具有较小的标准差。
3.标准差的计算
样本标准差=方差的算术平方根=s=sqrt(((x1-x)^2 +(x2-x)^2 +......(xn-x)^2)/n)
标准差:所有数减去其平均值的平方和,所得结果除以该组数之个数(或个数减一,即变异数), 再把所得值开根号,所得之数就是这组数据的标准差。
实例:
import numpy as np
# 一维数组
arr = [1, 2, 3]
print("一维数组 :", arr)
print("标准差 ", np.std(arr))
# 二维数组按列求标准差
arr = [[1, 2, 3],[1, 2, 3],[1, 2, 3]]
print("二维数组 :", arr)
print("按列求标准差 ", np.std(arr,axis=0))
# 二维数组按行求标准差
arr = [[1, 2, 3],[1, 2, 3],[1, 2, 3]]
print("二维数组 :", arr)
print("按行求标准差 ", np.std(arr,axis=1))
# 二维数组求所有数的标准差
arr = [[1, 2, 3],[1, 2, 3],[1, 2, 3]]
print("二维数组 :", arr)
print("所有数的标准差 ", np.std(arr))
#####################################
'''
简单来说,标准差是一组数据平均值分散程度的一种度量。
一个较大的标准差,代表大部分数值和其平均值之间差异较大;
一个较小的标准差,代表这些数值较接近平均值。
例如,两组数的集合{0,5,9,14}和{5,6,8,9}其平均值都是7,但第二个集合具有较小的标准差。
标准差:所有数减去其平均值的平方和,所得结果除以该组数之个数(或个数减一,即变异数),
再把所得值开根号,所得之数就是这组数据的标准差。
'''
arr1=[0,5,9,14]
print("一维数组 arr1:", arr1)
print("一维数组arr1的平均值:",np.mean(arr1))
print("arr1 标准差 ", np.std(arr1))
arr2=[5,6,8,9]
print("一维数组 arr2:", arr2)
print("一维数组arr2的平均值:",np.mean(arr2))
print("arr2 标准差 ", np.std(arr2))
运行结果:
一维数组 : [1, 2, 3]
标准差 0.816496580927726
二维数组 : [[1, 2, 3], [1, 2, 3], [1, 2, 3]]
按列求标准差 [0. 0. 0.]
二维数组 : [[1, 2, 3], [1, 2, 3], [1, 2, 3]]
按行求标准差 [0.81649658 0.81649658 0.81649658]
二维数组 : [[1, 2, 3], [1, 2, 3], [1, 2, 3]]
所有数的标准差 0.816496580927726
一维数组 arr1: [0, 5, 9, 14]
一维数组arr1的平均值: 7.0
arr1 标准差 5.1478150704935
一维数组 arr2: [5, 6, 8, 9]
一维数组arr2的平均值: 7.0
arr2 标准差 1.5811388300841898
4.归一化
所谓“归一”,注意“一”,就是把数据归到(0,1)这个区间内。
归一化主要是应用于没有距离计算的地方上,标准化则是使用在不关乎权重的地方上,因为各自丢失了距离信息和权重信息。
数据归一化是将数据转换为特定范围内的值的过程。在机器学习和数据挖掘中,归一化(Normalization)是指将数据按比例缩放,使之落入一个小的特定区间。这个特定区间通常是[0,1]或[-1,1]。归一化是将原始数据转换为标准格式的一种方法。
常用归一化方法:
Zero-mean normalization(z-score标准化)
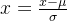 - 将原始数据集归一化为均值为0、方差1的数据集。
- 该种归一化方式要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕。
- 将原始数据集归一化为均值为0、方差1的数据集。
- 该种归一化方式要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕。
Min-max normalization(最大最小归一化)
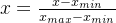
- 线性函数将原始数据线性化的方法转换到[0 1]的范围, 计算结果为归一化后的数据,X为原始数据
- 本归一化方法比较适用在数值比较集中的情况;
- 缺陷:如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量来替代max和min。
归一化实例:
import numpy as np
from sklearn.preprocessing import MinMaxScaler
#测试数据集
arr = np.array([[1, -1, 2], [2, 0, 0], [0, 1, -1]])
print(arr)
# 归一化
scales_mm = MinMaxScaler(feature_range=(0, 1), copy=False)
arr_new = scales_mm.fit(arr).transform(arr)
print("----------MinMaxScaler归一化----------")
print(arr_new)
print('----------手工归一化-----------')
c = arr.min(axis=0)
d = arr.max(axis=0)
print('min集合', c)
print('max集合', d)
X = arr.copy()
X_s = np.zeros(shape=(3, 3))
for j in range(c.size):
for i in range(X.shape[1]):
X_s[j][i] = (X[j][i] - c[i]) / (d[i] - c[i])
print(X_s)
运行结果:
[[ 1 -1 2]
[ 2 0 0]
[ 0 1 -1]]
----------MinMaxScaler归一化----------
[[0.5 0. 1. ]
[1. 0.5 0.33333333]
[0. 1. 0. ]]
----------手工归一化-----------
min集合 [ 0 -1 -1]
max集合 [2 1 2]
[[0.5 0. 1. ]
[1. 0.5 0.33333333]
[0. 1. 0. ]]
标准化实例:
import numpy as np
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# 测试数据集
arr = np.array([[1, -1, 2], [2, 0, 0], [0, 1, -1]])
print(arr)
# 标准化
scales_ss = StandardScaler()
arr_new = scales_ss.fit(arr).transform(arr)
print("----------StandardScaler()标准化--------------")
print(arr_new)
# 手动标准化函数
def Z_score_Scale(data):
return (data - np.mean(data, axis=0)) / np.std(data, axis=0)
print("----------手动标准化--------------")
arr_new2 = Z_score_Scale(arr)
print(arr_new2)
运行结果:
[[ 1 -1 2]
[ 2 0 0]
[ 0 1 -1]]
----------StandardScaler()标准化--------------
[[ 0. -1.22474487 1.33630621]
[ 1.22474487 0. -0.26726124]
[-1.22474487 1.22474487 -1.06904497]]
----------手动标准化--------------
[[ 0. -1.22474487 1.33630621]
[ 1.22474487 0. -0.26726124]
[-1.22474487 1.22474487 -1.06904497]]