一个汉字究竟占几个字节
一个汉字究竟占几个字节
一个汉字究竟占几个字节?
1.一个中文字符在计算机中究竟占几个字节?
一个中文字符在计算机中占几个字节,取决于这个中文字符使用什么字符编码。常见的中文字符编码有以下几种:
- GBK: 中国人自己定义的一套中文字符编码。
- Unicode:也成为万国码,支持全世界所有国家语言文字的字符编码。
- UTF8:是对Unicode编码的一种再编码,一种可变长度编码。
几种常见中文编码之间存的兼容性,如下图所示:
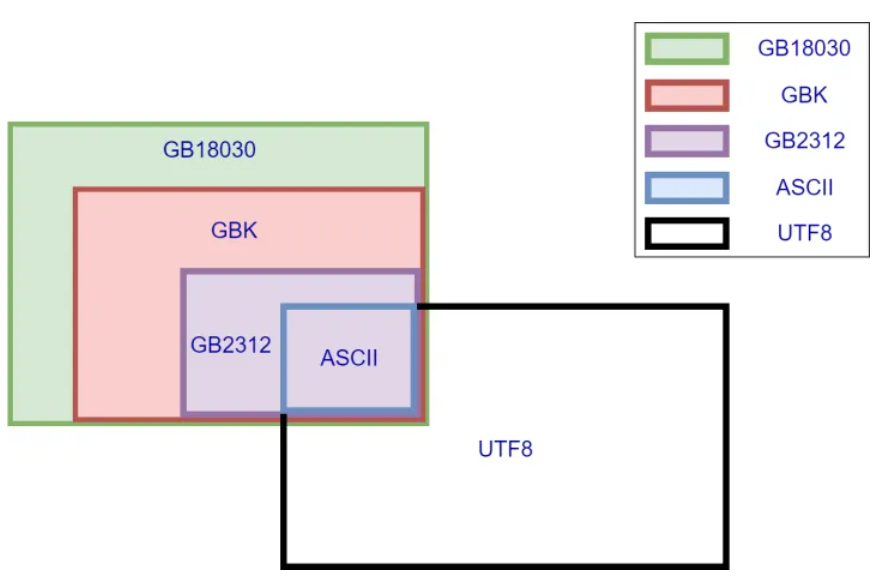
通过上图所示,我们不难发现所有的中文字符集中,只有ASCII码(纯英文字符)的编码是完全兼容的,中文字符GBK编码与Unicode编码完全不兼容。
2.通过一个例子说明
| 字符 | 编码 | 编码值 | 一个汉字占用字节数 |
|---|---|---|---|
| '中' | GBK | D6 D0 | 2 |
| '中' | Unicode | FF FE 2D 4E | 2, 注意:FF FE是unicode文件开头的标识符号 |
| '中' | UTF8 | E4 B8 AD | 2 |
我们发现同一个汉字,使用不同的字符集,其编码也完全不同。
通常我们软件系统,遵循国际化的思想,一律使用Unicode字符集。
注意:中文windows系统默认使用GBK字符集,这就给我们程序员在windows上开发程序,挖了一个大坑!
3.Unicode与UTF8之间的转换关系
Unicode编码的主要目的是维护一个表,它并没有规定一个字符到底用几个字节来表示。如果每个字符都占用两个字节,那么使用频率最高的英文字符就会造成巨大的存储空间浪费。为了解决空间浪费问题,因为就出现了UTF8字符集,UTF-8 就是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。这样做的好处是让使用频率越高的语言字符占用存储空间越少。
Unicode与UTF8之间的转换关系如下表:
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
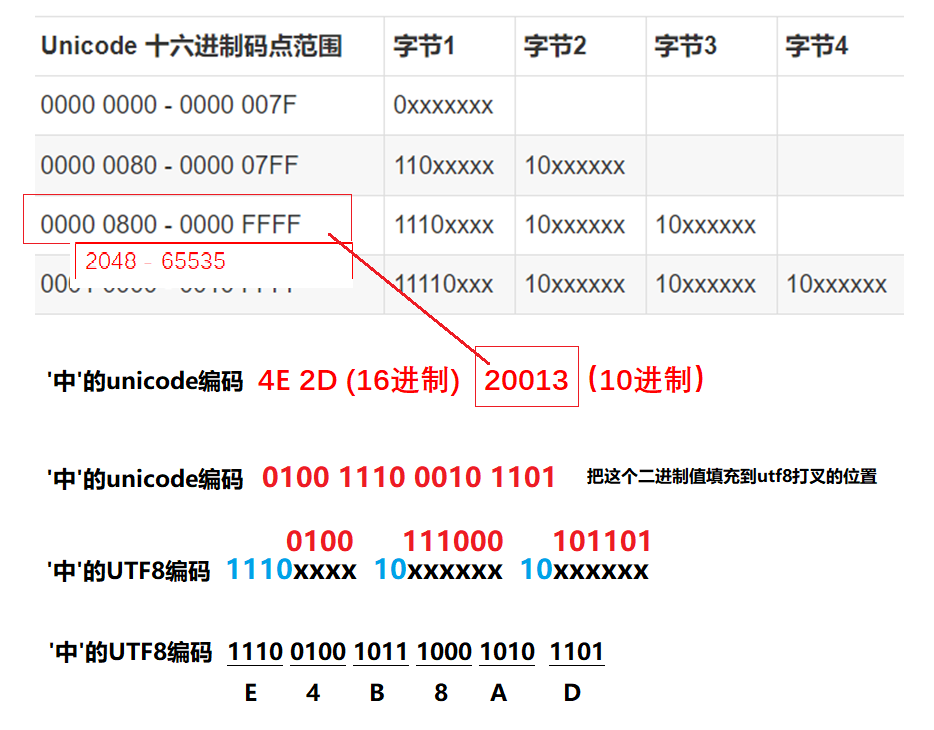
汉字‘中’ 的 unicode编码 2D 4E ,其中 4E是高位字节,2D是低位字节,因此真正的Unicode编码应该是 4E 2D, 汉字 ‘中’ 的UTF-8编码是:E4 B8 AD。
把汉字'中'的unicode编码 4E 2D ,转换为UTF8编码 E4 B8 AD,的过程如下图所示:
4.小结
- 一个汉字占多少字节,取决于这个汉字使用什么字符编码。
- 如果使用GBK编码,占用两个字节。
- 如果使用Unicode 编码,占用两个字节。注意:unicode字符文件规定必须以FF FE 开头,所以如果只有一个汉字,那么就是4个字节。
- 如果是UTF8编码,占用三个字节。
- 在软件系统中,强烈推荐中文字符一律使用utf-8编码,以支持国际化。