HBase基础教程
HBase基础教程
HBase基础教程
![]()
1.什么是HBase?
HBase是建立在Hadoop文件系统之上的分布式面向列的数据库。它是一个开源项目,是横向扩展的。
HBase是一个数据模型,类似于谷歌的大表设计,可以提供快速随机访问海量结构化数据。它利用了Hadoop的文件系统(HDFS)提供的容错能力。
HBase属于Hadoop的生态系统,提供对数据的随机实时读/写访问,是Hadoop文件系统的一部分。人们可以直接或通过HBase的存储HDFS数据。使用HBase在HDFS读取消费/随机访问数据。HBase在Hadoop的文件系统之上,并提供了读写访问。
2.Hbase与HDFS
| HDFS | HBase |
|---|---|
| HDFS是适于存储大容量文件的分布式文件系统。 | HBase是建立在HDFS之上的数据库 |
| HDFS不支持快速单独记录查。 | HBase提供在较大的表快速查找找。 |
| 它提供了高延迟批量处理; | 它提供了数十亿条记录低延迟访问单个行记录 |
| 提供的数据只能顺序访问。 | HBase内部使用哈希表和提供随机接入,并且其存储索引。可将在HDFS文件中的数据进行快速查找 |
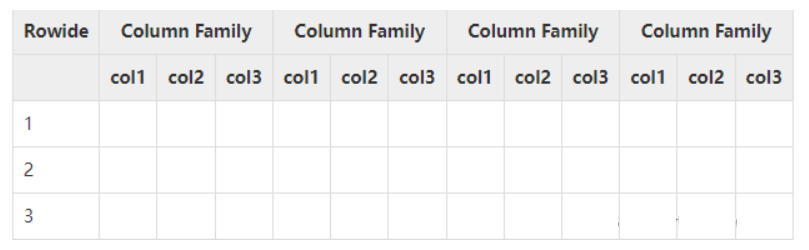
3.HBase的存储机制
HBase是一个面向列的数据库,在表中它由行排序。表模式定义只能列族,也就是键值对。一个表有多个列族以及每一个列族可以有任意数量的列。后续列的值连续地存储在磁盘上。表中的每个单元格值都具有时间戳。总之,在一个HBase:
- 表是行的集合。
- 行是列族的集合。
- 列族是列的集合。
- 列是键值对的集合。
4.面向列和面向行
| 行式数据库 | 列式数据库 |
|---|---|
| 它适用于联机事务处理(OLTP) | 它适用于在线分析处理(OLAP) |
| 这样的数据库被设计为小数目的行和列。 | 面向列的数据库设计的巨大表 |