Python3基础教程(九十七)
Pandas数据分析综合案例
Pandas数据分析综合案例
1.原始数据
有以下2017年中国各个省份的碳排放量的csv统计数据。
链接:https://pan.baidu.com/s/17djCzSqnWzU8CTo5m_kBQg 提取码:9527
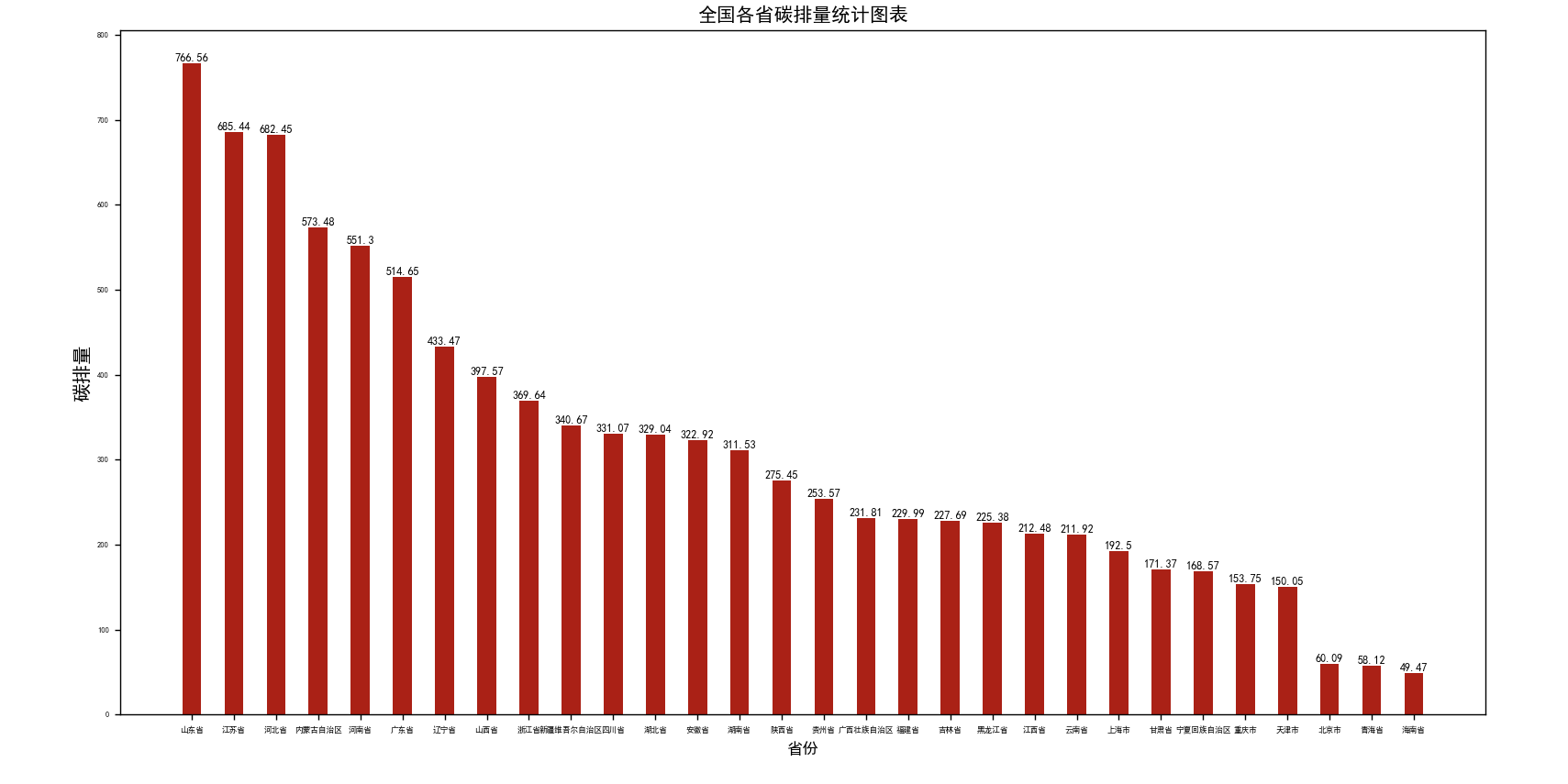
要求使用pandas的matplotlib库实现统计各个省碳排放总量,并且按照降序排序输出并且也图表展示。
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import cm
import numpy as np
# 设置 可视化风格
plt.style.use('tableau-colorblind10')
# 以下代码从全局设置字体为SimHei(黑体),解决显示中文问题
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决中文字体下坐标轴负数的负号显示问题
plt.rcParams['axes.unicode_minus'] = False
def main():
# 定义一个空字典
provice_group_list = []
# 读取csv文件
df = pd.read_csv('2017年中国县级尺度碳排放.csv', encoding="utf-8")
# 按照省份分组
province_df = df['碳排放'].groupby(df['省'])
# print(type(province_df))
# print(province_df)
for name, group in province_df:
# print(name)
# print(np.sum(group))
temp_list = [name, round(np.sum(group), 2)]
provice_group_list.append(temp_list)
print(provice_group_list)
province_group_df = pd.DataFrame(provice_group_list, columns=['省份', '碳排量'])
province_group_df = province_group_df.sort_values(by='碳排量', ascending=False, axis=0)
print(province_group_df)
# 柱状的颜色指定为渐变色
my_colors = cm.Blues(np.arange(province_group_df['省份'].shape[0]) / province_group_df['省份'].shape[0])
#bar1 = plt.bar(province_group_df['省份'], province_group_df['碳排量'], width=0.45, color=my_colors)
bar1 = plt.bar(province_group_df['省份'], province_group_df['碳排量'], width=0.45, color='#aa2116')
# 标注数值
plt.bar_label(bar1, fontsize=7)
plt.title('全国各省碳排量统计图表')
plt.ylabel('碳排量', fontsize=12)
plt.xlabel('省份', fontsize=10)
plt.yticks(fontsize=5)
plt.xticks(fontsize=5)
plt.show()
if __name__ == '__main__':
main()
运行效果: